







引言及内容概要
微信公众平台支持向用户回复音乐消息,用户收到音乐消息后,点击即可播放音乐。通过音乐消息,公众账号可以实现音乐搜索(歌曲点播)功能,即用户输入想听的音乐名称,公众账号返回对应的音乐(歌曲)。读者可以关注xiaoqrobot体验该功能,操作指南及使用如下所示。
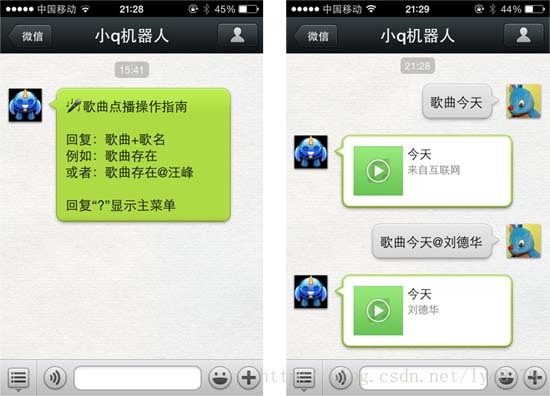
考虑到歌曲名称有重复的情况,用户还可以同时指定歌曲名称、演唱者搜索歌曲。下面就为读者详细介绍歌曲点播功能的实现过程。
音乐消息说明
在微信公众平台开发者文档中提到,向用户回复音乐消息需要构造如下格式的XML数据。
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>12345678</CreateTime>
<MsgType><![CDATA[music]]></MsgType>
<Music>
<Title><![CDATA[TITLE]]></Title>
<Description><![CDATA[DESCRIPTION]]></Description>
<MusicUrl><![CDATA[MUSIC_Url]]></MusicUrl>
<HQMusicUrl><![CDATA[HQ_MUSIC_Url]]></HQMusicUrl>
<ThumbMediaId><![CDATA[media_id]]></ThumbMediaId>
</Music>
</xml>1)参数Title:标题,本例中可以设置为歌曲名称;
2)参数Description:描述,本例中可以设置为歌曲的演唱者;
3)参数MusicUrl:普通品质的音乐链接;
4)参数HQMusicUrl:高品质的音乐链接,在WIFI环境下会优先使用该链接播放音乐;
5)参数ThumbMediaId:缩略图的媒体ID,通过上传多媒体文件获得;它指向的是一张图片,最终会作为音乐消息左侧绿色方形区域的背景图片。
上述5个参数中,最为重要的是MusicUrl和HQMusicUrl,这也是本文的重点,如何根据歌曲名称获得歌曲的链接。如果读者只能得到歌曲的一个链接,可以将MusicUrl和HQMusicUrl设置成一样的。至于ThumbMediaId参数,必须是通过微信认证的服务号才能得到,普通的服务号与订阅号可以忽略该参数,也就是说,在回复给微信服务器的XML中可以不包含ThumbMediaId参数。
百度音乐搜索API介绍
上面提到,给用户回复音乐消息最关键在于如何根据歌曲名称获得歌曲的链接,我们必须找一个现成的音乐搜索API,除非读者自己有音乐服务器,或者只向用户回复固定的几首音乐。百度有一个非公开的音乐搜索API,之所以说非公开,是因为笔者没有在百度官网的任何地方看到有关该API的介绍,但这并不影响读者对本例的学习,我们仍然可以调用它。百度音乐搜索API的请求地址如下:
http://box.zhangmen.baidu.com/x?op=12&count=1&title=TITLE$$AUTHOR$$$$http://box.zhangmen.baidu.com为百度音乐盒的首页地址,上面的链接中不用管参数op和count,重点关注TITLE和AUTHOR,TITLE表示歌曲名称,AUTHOR表示演唱者,AUTHOR可以为空,参数TITLE和AUTHOR需要进行URL编码(UTF-8或GB2312均可)。例如,要搜索歌曲零点乐队的“相信自己”,可以像下面这样:
// GB2312编码的音乐搜索链接
http://box.zhangmen.baidu.com/x?op=12&count=1&title=%CF%E0%D0%C5%D7%D4%BC%BA$$%C1%E3%B5%E3%C0%D6%B6%D3$$$$
// UTF-8编码的音乐搜索链接
http://box.zhangmen.baidu.com/x? 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









