









这一周的课程包括了逻辑回归(Logistic Regression)以及线性回归和逻辑回归损失函数的正则化。
逻辑回归
逻辑回归解决的是分类问题,通过回归得到的是一个分类器(classifier)。不过令人奇怪的是,既然是分类问题,为什么还要用回归来命名这种方法?模糊地记得Ng说是历史原因……
假设函数
分类问题可分为二元分类和多类分类,以二元分类为基础进行讨论,多类分类问题可在此基础上通过one vs all得到多个分类器进而得到解决。
对于二元分类问题,输出
y∈{0,1}
或者
y∈{−1,1}
。相对应的假设函数分别为:
或者:
这里我们让 y∈{0,1} ,假设函数为 sigmoid 函数。则有:
损失函数
先给出最终的损失函数
J(θ)
:
推导:
假设只有一个样本。由于假设函数 hθ(x)∈(0,1) ,又有公式3所示的条件,则有:
下图为 y=1 和 y=0 两种情况下的 J(θ) 对 hθ(x) 的函数图像。
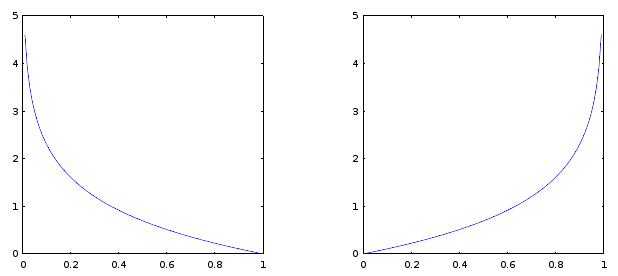
将公式5合并化简并运用到多个样本值就得到了公式4。
损失函数的概率解释
这部分内容参考了这篇文章。
在线性回归中,采用最小二乘法计算其损失函数还比较容易理解,
∑mi=1(hθ(x(i))−y(i))2
也比较直观。而在逻辑回归中,为什么采用自然对数来计算“损失”呢?
首先,在逻辑回归中,假设每一个样本事件符合伯努利分布,那么针对每一个样本,均有:
即:
由此可得到 似然函数:
接着进行最大似然估计,由于(来自 维基百科):
最大化一个似然函数同最大化它的自然对数是等价的。
因此可将似然函数变换为:
到了这里便很明显了,似然函数和前面的损失函数简直就是一样一样的嘛。不过还有一个问题, 为什么用 sigmoid(θTx) 表示 P(y=1|x;θ) 呢?感觉这里面完全没有什么道理可言,想不明白……
计算最优解
首先计算损失函数对
θ
的偏导数,简要推导过程如下(
sigmoid
函数求导为:
g′(a)=g(a)(1−g(a))
):
到这已知 J(θ) 和 ∂J(θ)∂θj ,由于逻辑回归可能存在局部最小值,因此使用梯度下降法并不合适,这里采用高级优化算法,比如MATLAB自带的优化函数fminunc。优化得到使损失函数最小化的 θ 。
正则化
这里正则化(Rgularization)和常说的归一化(Normalization)和标准化(Standardization)容易混淆,注意区分,另外在不同学科领域中,正则化也有不同的解释。在机器学习中,如果样本太小或者模型过于复杂,容易出现过拟合(overfitting)的现象。对损失函数进行正则化就是一种可以有效避免过拟合的方法。
正则化的方法对于线性回归和逻辑回归来说都一样,都是在损失函数添加一项关于
θ
的分项:
公式11中 n 为输入特征的数量,
版权声明:署名-非商业性使用-相同方式共享 3.0 中国大陆 (CC BY-NC-SA 3.0 CN)
发表日期:2016年5月18日















 6907
6907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









