









无名之人,希望自己能够踏踏实实地努力,在进步的路上看清自己的每一个脚印。
介绍
Coursera上面的机器学习课程是由Stanford大学的Andrew Ng(中文名:吴恩达)老师教授的。之前并不了解他,也是跟着上了这门课程后才知道这么个牛人。下面是第一周机器学习的笔记整理。
机器学习的定义
课程材料中提到了Arthur Samuel给机器学习的定义,比较通俗却不严谨:
The field of study that gives computers the ability to learn without being explicitly programmed.
研究不经精确编程而使得计算机具有学习能力的领域。
Tom Mitchell提供了更为现代的定义:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
一个电脑程序,如果它执行任务T的性能(由P来评估)通过经验E得到了提升,则可以说:就某些种类的任务T和性能评估P而言,此程序能够从经验E中学习。
举个栗子:西洋棋游戏。
- E = 玩很多西洋棋游戏的经验
- T = 下好西洋棋
- P = 程序在下局游戏中获胜的可能
监督式学习
在监督式学习supervised learning中,对于已知的数据集,我们已经知道正确的输入应该是什么样的,并且已知输入和输出之间存在某种关系。主要可分为回归Regression和分类Classification。
- 在回归问题中,通过将输入变量映射到某种连续函数,获得连续输出以预测结果。
- 在分类问题中,通过将输入变量映射到离散的类别中,以预测离散的输出。
举个栗子:
回归 - 根据已有房子面积和房子价格的数据集,预测某个房子的价格;
分类 - 同样的数据集,将输出更改为“房子的价格是否比购房子提出的价格高或低”。
非监督式学习
在非监督式学习unsupervised learning中,我们对输出结果所知甚少,或者一无所知。在过程中,并没有预测结果以获得反馈。比如,我们可以通过聚类从输入变量之间的关系中获得结构。这里不举栗子了,栗子好沉。
单变量线性回归
单变量线性回归 - Univariate linear regression,通过单一输入变量预测单一输出值。因此需要根据数据集求取输出变量和输入变量的函数表达式。
假设函数 The Hypothesis Function
单变量线性回归的假设函数的一般形式为:
其中 hθ(x) 和 x 分别为数据集的输出和输入值,求解假设函数就是根据数据集求得最优的
损失函数 Cost Function
损失函数能够评价假设函数的准确度,其一般形式为:
其中, m 表示数据集包含的样本数量,
很明显,使得损失函数取最小值的
对于单变量线性回归,可以证明其代价函数在直角坐标系中的形状为 碗形,如图2.1所示:
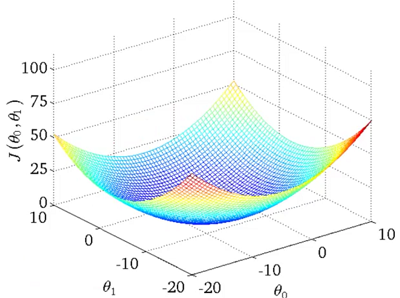
图2.1 单变量线性回归的代价函数图像
因此,可以用梯度下降法进行最优化。
梯度下降法 Gradient Descent
通过对损失函数进行求导,使导数为0的 θ0,θ1 就是最优解。在实际计算时采用梯度下降法,其方程式为:
重复下式直至收敛:
其中 j= {0, 1}。
一些解释:
针对单变量线性回归的梯度下降法
将上面这些结合一下,可得到针对单变量线性回归的梯度下降法:
重复下式直至收敛:
在进行计算时一定要按照上述步骤进行计算,即同步更新,根据上次迭代得到的( θ0,θ1 )分别计算 temp0,temp1 ,然后再赋值给( θ0,θ1 )。
学习速率 α 对迭代速度和效果的影响
- α 过大,很可能会导致梯度下降法无法收敛,也就是说每一步迭代计算出来的代价函数值逐渐增加而不是下降。
- α 过小,一般不会影响能否收敛,但会导致梯度下降法速度过慢,需要更多的迭代步骤才能获得最优解。
- 合适的 α 能保证梯度下降法以较少的迭代步骤收敛。
- 对于合适的 α 而言,即使在每一步迭代中都保持 α 固定不变,梯度下降法也能收敛到局部最小值(对于单变量线性回归,只有一个极小值,不存在其他的局部最小值)。
不过,在实际计算中,需要多次尝试才能获得较好的学习速率
α
。一般(举个栗子)以(0.01, 0.03, 0.1, 0.3, 1, …)对
α
进行尝试。一种直观的方法是,在计算的过程中plot某个
α
下
J(θ)
与迭代次数的图像,以观察收敛好坏,例如图2.2所示:
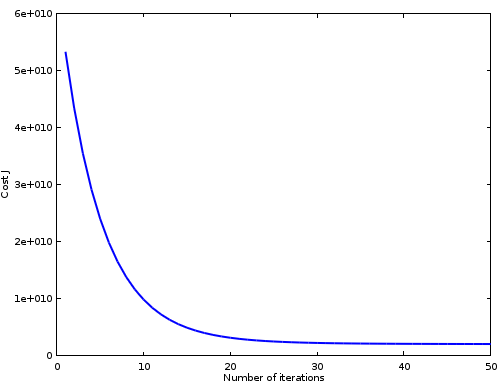
图2.2 某个
α
下损失函数VS迭代次数
What`s next?
- 多变量线性回归的梯度下降法编程求解 VS Normal Equations
- Matlab替代性软件Octave简介
版权声明:署名-非商业性使用-相同方式共享 3.0 中国大陆 (CC BY-NC-SA 3.0 CN)
发表日期:2016年4月14日















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









