







 本文批评了现有LSTM论文中常见的表述不清及误导性图表,并通过对比不同版本的LSTM架构图,指出了它们的问题所在。作者推荐了一篇优秀的博客文章及其直观的LSTM说明图,同时分享了一个自己绘制的更易于理解的LSTM架构图。
本文批评了现有LSTM论文中常见的表述不清及误导性图表,并通过对比不同版本的LSTM架构图,指出了它们的问题所在。作者推荐了一篇优秀的博客文章及其直观的LSTM说明图,同时分享了一个自己绘制的更易于理解的LSTM架构图。
People never judge an academic paper by those user experience standards that they apply to software. If the purpose of a paper were really promoting understanding, then most of them suck. A while ago, I read this article talking about academic pretentiousness and it speaks my heart out. My feeling is, papers are not for better understanding but rather for self-promotion. It’s a way for scholars to declare achievements and make others admire. Therefore the golden standard for an academic paper has always been letting others acknowledge the greatness, but never understand enough to surpass itself.
When it comes to LSTM, for example, there aren’t many good materials. Most likely what they would show you is this bullshit image:
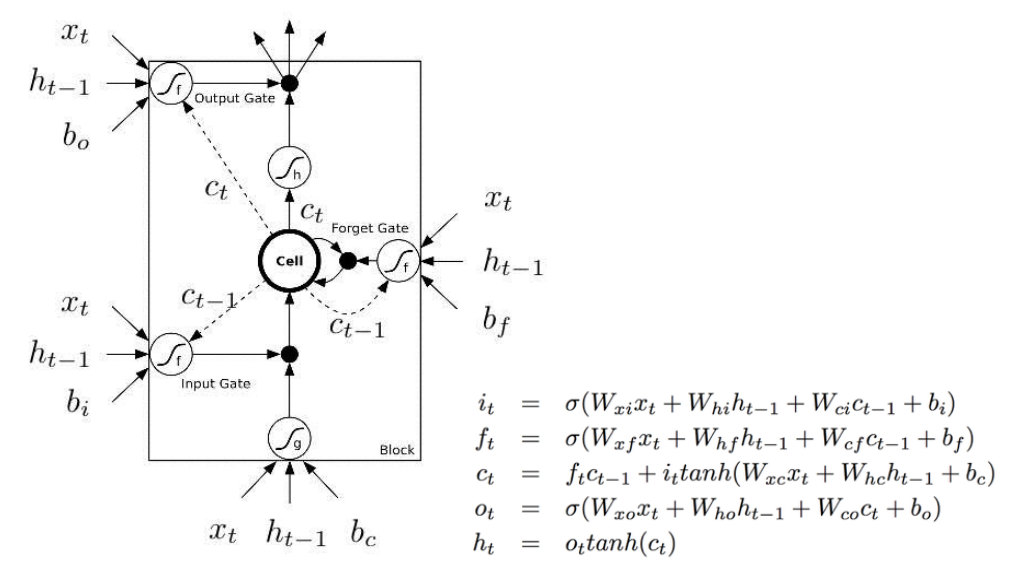
There are many things on this image pisses me off.
First of all, they use these f shapes (with a footnote “f” that looks like a “t”)to denote non-linearity and at the same time, they have f_t in their equations. And they are not the same thing!
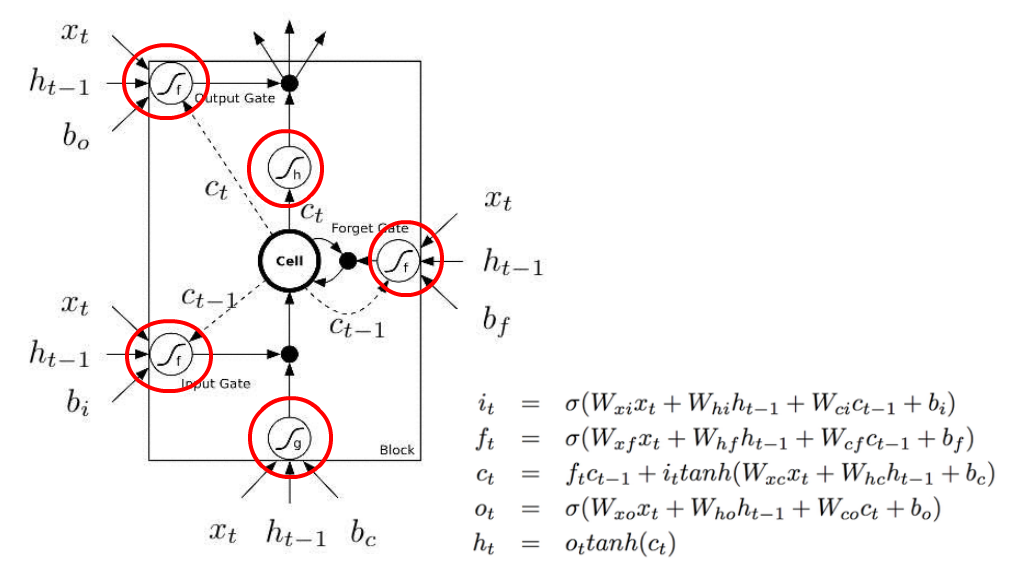
Second, they have these dash lines and solid lines to represent time delay. So solid lines are C_t, and dash lines are C_t-1. There are 5 arrows coming out of the “Cell”, but only 4 are labelled. One C_t is incorrectly labelled with dash line. One solid line is supposed to be a dash line and C_t-1.
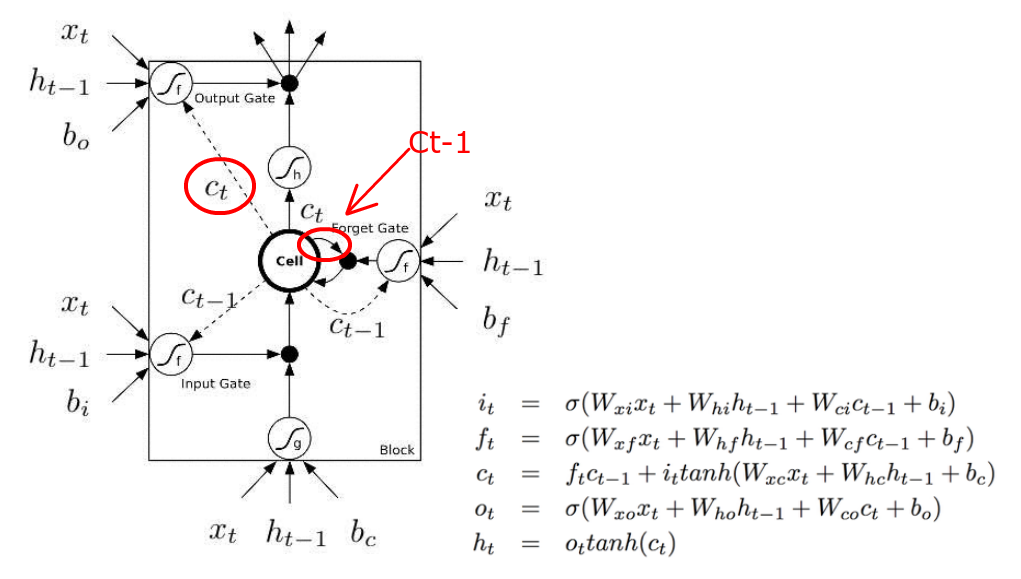
Third, what the hell are black dots? You have to look at the equation to figure out that they are element-wise multiplications of two vectors.
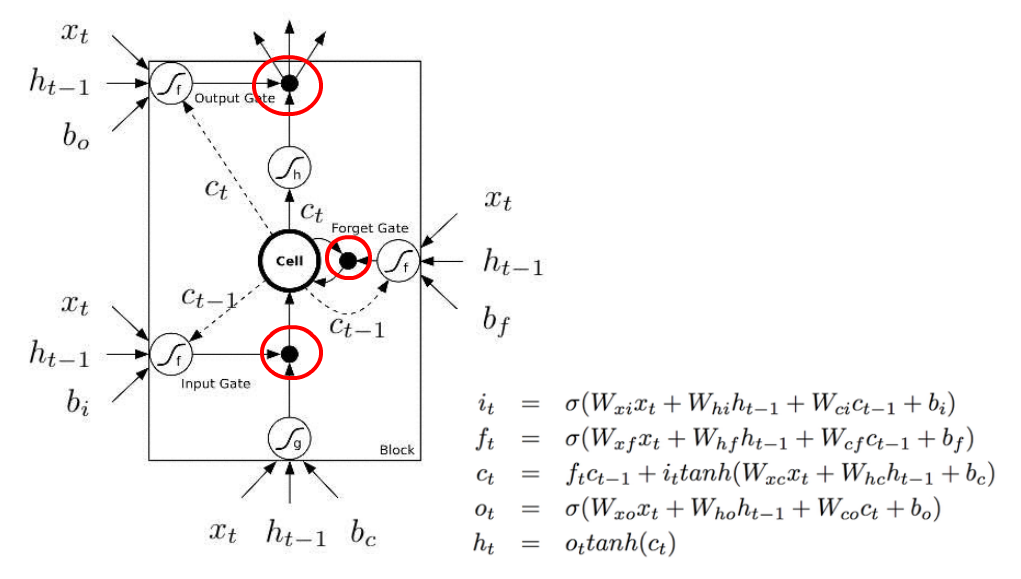
And finally, C_t is supposed to be calculated as a summation of f_t * C_t-1 and i_t * tanh(W_xc * x_t + W_hc*h_t-1 +b_c) (the third equation). But the image completely misses the plus sign.
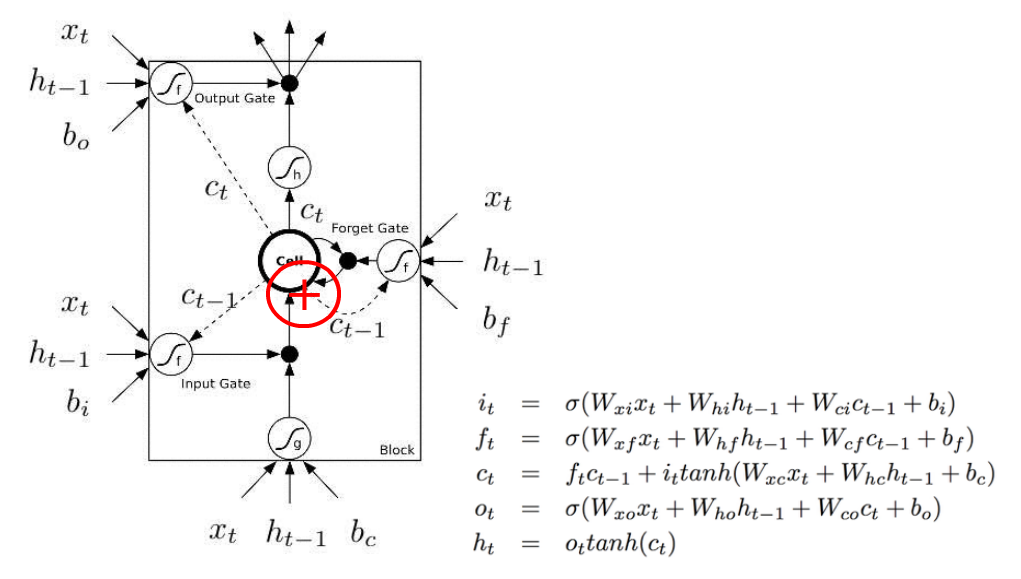
Compared to this shitty image, the following version is slightly better:
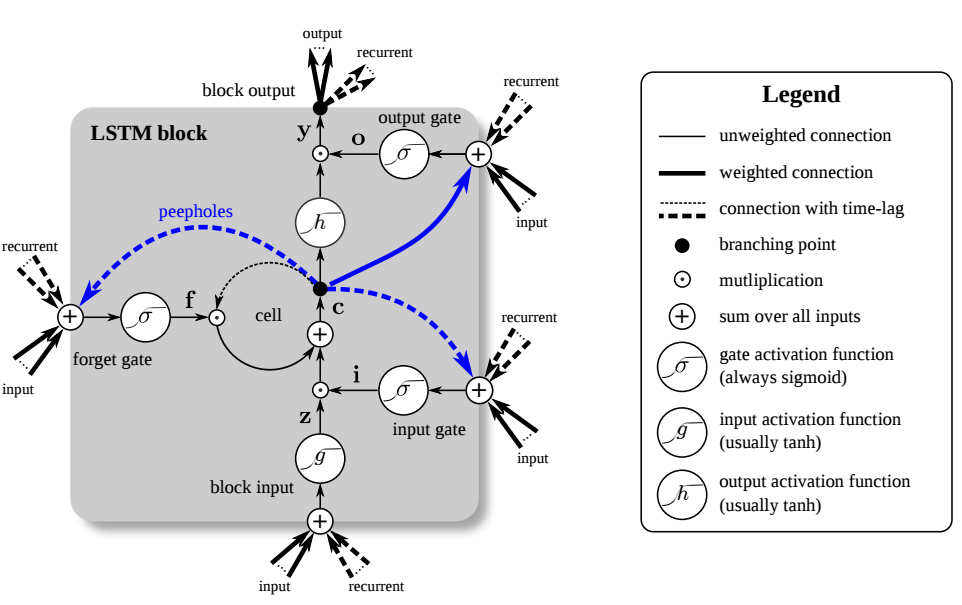
The 3 C_t-1 are correctly represented as dash lines. The plus sign is there too. Sigmoid functions are written with the proper sigma sign, not some freaking f_f.
See, things don’t have to be so difficult. And understanding shouldn’t be a painful experience. But unfortunately, academic writing makes it so almost all the time.
Perhaps the best learning material is really this excellent blog post:
And its diagram is simply beautiful:
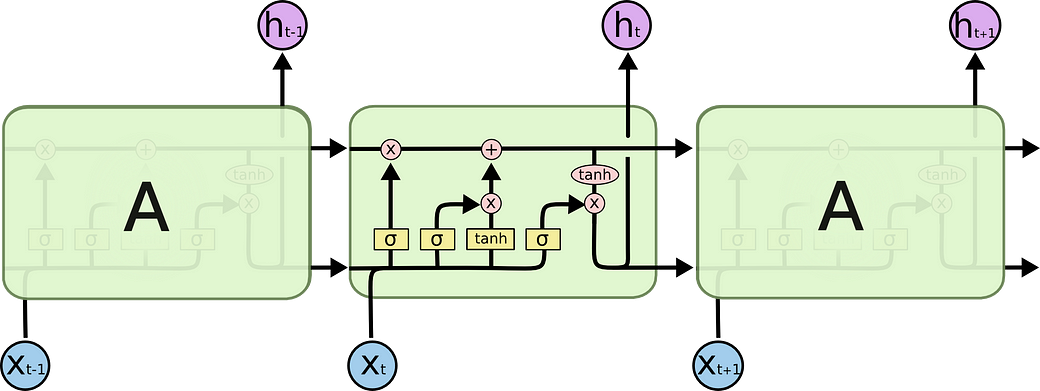

I think the most evil thing about the first two versions are that they treat C (the cell, or the memory) not as an input to the LSTM block, but rather a thing that is internal to the block. And they adopt this complex dash line, solid line thing to represent delay. This is really confusing.
But I do noticed one difference between the first two diagrams and the last one. The first two diagrams sum up the inputs with the outputs from the previous layer to calculate the gates (for example, f_t and i_t). But in the third version, the author concatenate them. I don’t know if it is because the third version is a variation or this doesn’t matter in terms of correctness. (But I don’t think it should be concatenation because the vector size h shouldn’t be changed. If it is really concatenation, the vector size of h will change to the size of x+h?)
I drew a new diagram, which I think is better:
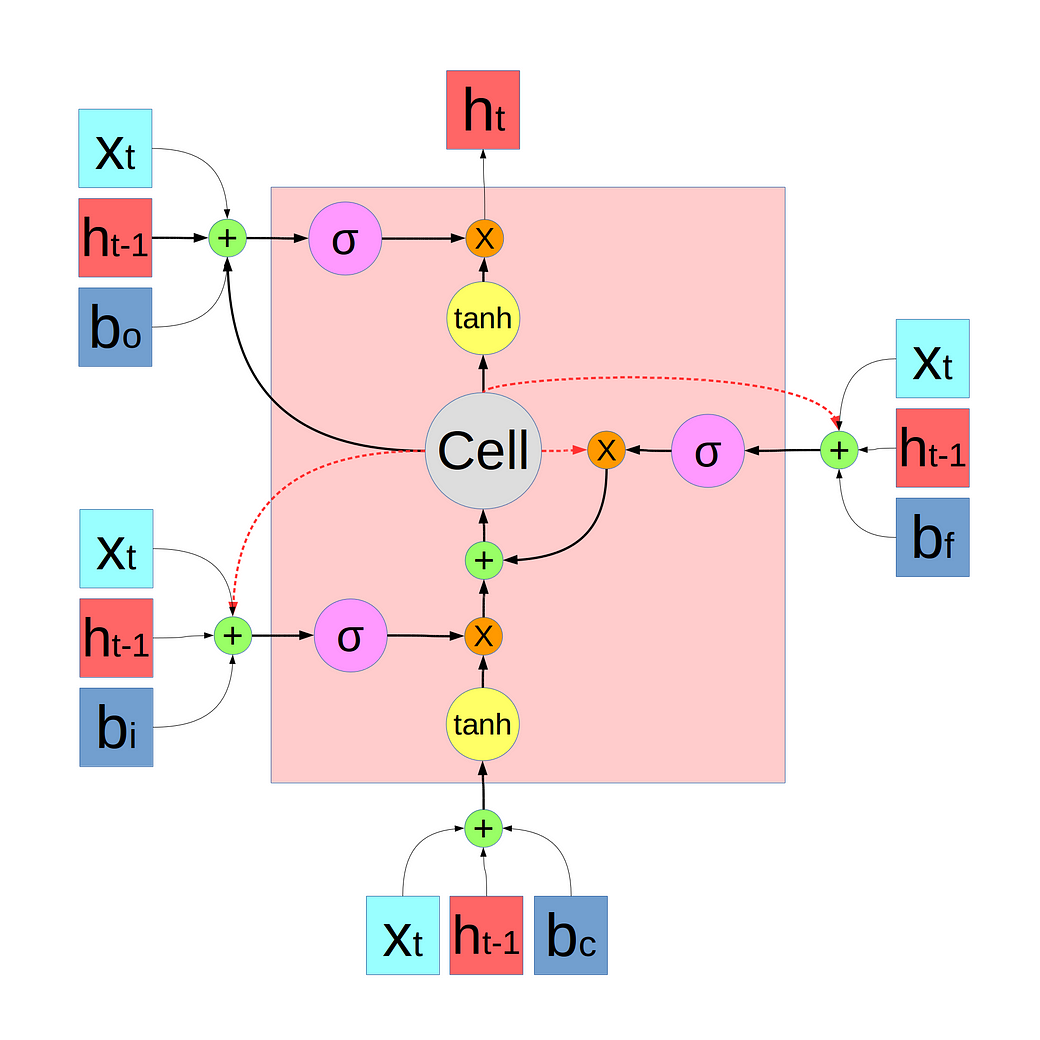
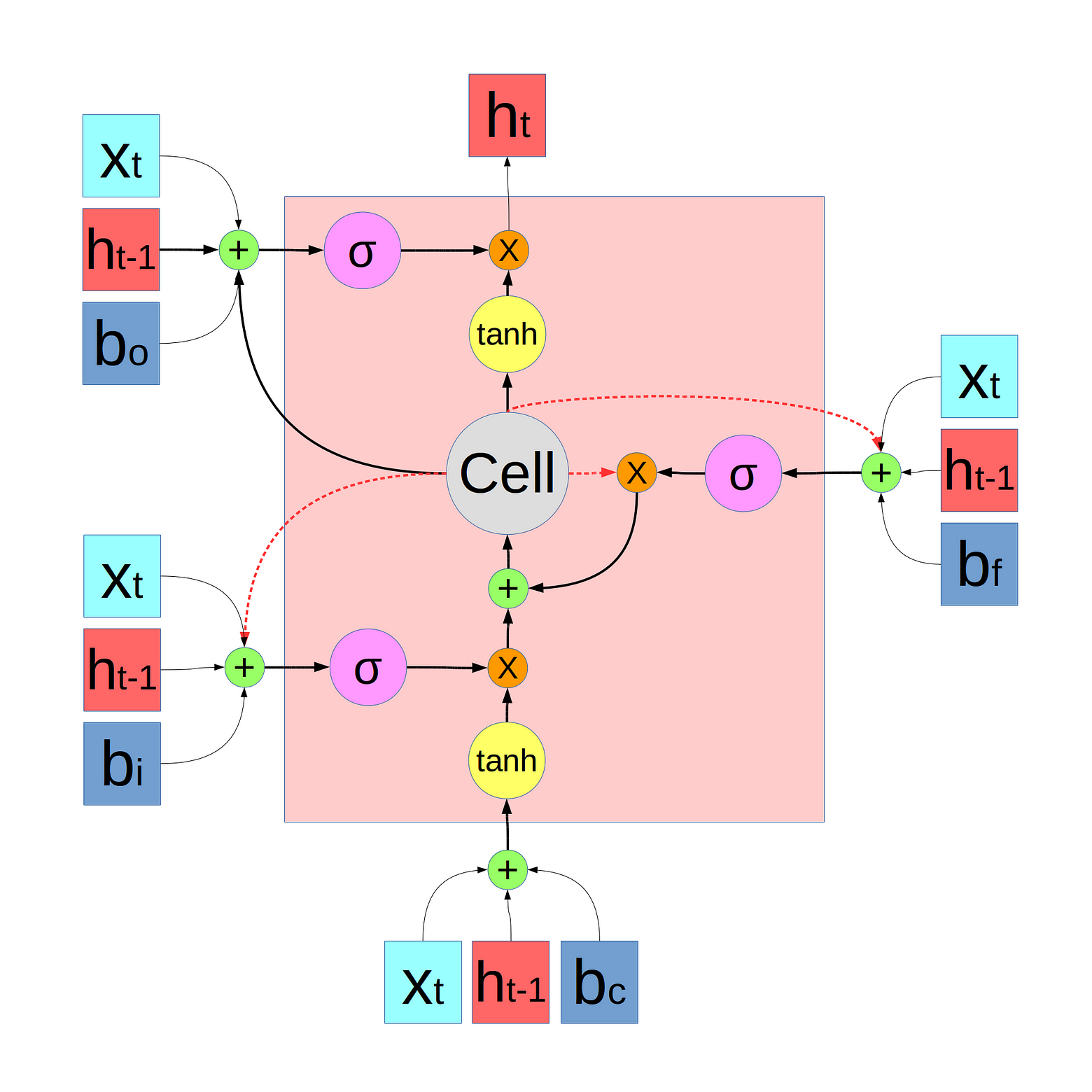
原文地址: https://medium.com/@shiyan/materials-to-understand-lstm-34387d6454c1

















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









