




 本文介绍了在不完备数据情况下进行贝叶斯学习的方法,包括最大似然估计(MLE)的梯度上升法与EM算法,以及贝叶斯估计。通过具体的示例和算法步骤,展示了如何处理缺失数据,并探讨了EM算法与梯度上升法之间的区别。
本文介绍了在不完备数据情况下进行贝叶斯学习的方法,包括最大似然估计(MLE)的梯度上升法与EM算法,以及贝叶斯估计。通过具体的示例和算法步骤,展示了如何处理缺失数据,并探讨了EM算法与梯度上升法之间的区别。
http://blog.csdn.net/pipisorry/article/details/52626889
使用不完备数据的贝叶斯学习:MLE估计(梯度上升和EM算法)、贝叶斯估计。
表示:H[m]表示其值在数据实例o[m](观测)中缺失的变量。
参数估计
与处理完备数据的类似,有两种估计方法:最大似然估计MLE和贝叶斯估计。
使用不完备数据的最大似然估计MLE

梯度上升方法
{优化似然函数算法1}
计算梯度
先考虑相对于一个单一CPD的表值P(x|u)的导数(一个数据的某些变量的一组观测的导数)

Note: 联合概率P(x, u, o)可以这么看,数据及观测中x,u,o应该是相互对应的,如果不对应其概率应该为0。
一个观测时?

Note: p(e)可以表示成包含P(x|u)的乘积形式,所有对其求导就是直接相除。
部分赋值的一般情况

Note: 与往常一样,也就是将未观测到的值积掉,将P(o)写成与P(o)一致(参数的部分与观测到的完全相同)的所有完全赋值的和。

表格-CPD梯度的形式


Note: 也就是定理19.1的加和,因为19.1只考虑了一个观测数据的结果。这里只是对所有M个观测数据加和了。

示例

Note: 相当于联合分布相对条件分布求导,就是梯度上升?

Note: 定理19.2是要计算M个实例的和,现在只计算了其中一个实例o。如果每次只计算一个数据o,是不是就成了随机梯度上升?而这里是批梯度上升?






Note: 这个有点没搞懂,大概就是p(d1|c0)+p(d0|c0)=1且两者均非负,而在相对p(d1|c0)的梯度上增大l似然更快。
CPD表的网络中计算梯度算法


梯度上升算法

梯度上升的改进


梯度上升的局部最大和全局最大

期望最大化EM
{优化似然函数的算法2}
EM不是非线性函数优化的通用算法,而是专门为优化函数定做的特殊算法。
直觉
使用数据填充方法估计缺失数据的参数方法及其缺点
这种方法相当于用先验概率填充值

互相推导的EM算法
这种方法其实就是在计算期望充分统计量时使用了后验概率。


示例

完备数据的MLE

不完备数据的MLE


随机初始化参数并计算实例的权重

通过缺失实例权重计算新的参数的期望充分统计量


通过后验概率计算期望充分统计量
其实就是将完备数据的指示变量替换成了后验概率。也就是为了估计



贝叶斯网的EM算法

期望(E-步)
{可以从公式中看出注意期望是关于当前参数集的期望}




最大化(M-步)
将期望充分统计量当作观测,执行MLE,然后导出一个新的参数集。

贝叶斯网络EM算法的完整版本


扩展到一般的指数族。。。
EM步的一般情况

收敛性及局部最大值


使用EM的贝叶斯聚类
{EM的一个重要应用:聚类}
软聚类
假定类条件分布是多元高斯分布(实值数据)或者朴素贝叶斯结构(离散环境)。聚类的EM算法使用一个软聚类赋值,允许每个实例将其部分权重分摊给多个聚类,所分配的权重与其属于每个类别的概率成正比。
。。。
硬赋值EM
k-均值算法。。。
专栏19.A:发现用户聚类
给定用户的聚类赋值C,每个用户的个人购买Xi可以认为是相互条件独立的。我们有一个可以在其上使用EM算法的朴素贝叶斯模型。
这种方法的性能比专栏18.C的结构学习方法的性能更低,大概因为用户聚类变量完全不能在大量商品中捕捉复杂的偏好模式。
专栏18.C:用于协同过滤的贝叶斯网
对用户群体观察,学习不同交易间的相依结构。将每件商品i当作联合分布中的一个向量Xi,且将每个用户当作一个实例。
理论基础*
。。。
也可参考[EM算法]
硬-赋值EM
。。。
梯度上升和EM的比较
。。。
专栏19.C:参数学习中的实际考虑
局部极大值、停止准则、加速收敛
近似推理*
看不懂。。。
使用不完备数据的贝叶斯学习
概述
贝叶斯方法中,把参数视为影响所有训练实例概率的未观测变量。于是学习相当于根据观测来计算新样本的概率,这种学习可以通过计算参数上的后验概率来执行,且使用它进行预测。

不完备数据贝叶斯推理的解决方法

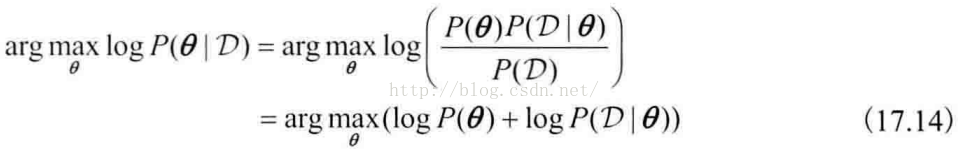



MCMC采样
Gibbs采样
专栏19.E:从狄利克雷分布中采样
坍塌的MCMC
变分贝叶斯学习
from: http://blog.csdn.net/pipisorry/article/details/52626889
ref:

















 87
87

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









