







 本文介绍了在Matlab中实现RBF神经网络的过程,包括初始化参数、训练算法,并通过与BP神经网络的实验对比,展示了RBF网络在分类任务上的优势。实验结果显示,RBF神经网络的分类准确率平均达到96%,并与SVM进行了比较,揭示了SVM在某些情况下可能提供更好的性能。
本文介绍了在Matlab中实现RBF神经网络的过程,包括初始化参数、训练算法,并通过与BP神经网络的实验对比,展示了RBF网络在分类任务上的优势。实验结果显示,RBF神经网络的分类准确率平均达到96%,并与SVM进行了比较,揭示了SVM在某些情况下可能提供更好的性能。
在上一篇博文中:Matlab实现BP神经网络和RBF神经网络(一) 中,我们讨论了BP网络设计部分,下面我们将设计RBF网络并将它们结果与SVM对比。
数据格式不变,详情请看上一篇博文。
RBF神经网络:
RBF网络和BP网络都是非线性多层前向网络,它们都是通用逼近器。对于任一个BP神经网络,总存在一个RBF神经网络可以代替它,反之亦然。但是这两个网络也存在着很多不同点,他们在网络结构、训练算法、网络资源的利用及逼近性能方面均有差异。RBF网络输入层与隐含层直接连接,相当于直接将输入向量输入到隐含层,隐含层的激活函数有几种,最常用的是高斯函数:

σ称为径向基函数的扩展常数,它反应了函数图像的宽度,σ越小,宽度越窄,函数越具有选择性。RBF网络传递函数是以输入向量与中心向量之间的距离|| X-Cj ||作为自变量的,把高斯函数中的r替换为|| X-Cj ||即可。RBF网络需要确定的参数是数据中心C,扩展常数σ和隐含层到输出层的权值。从网上查阅资料说,RBF网络可以根据具体问题确定相应的网络拓扑结构,具有自学习、自组织、自适应功能,它对非线性连续函数具有一致逼近性,学习速度快,可以进行大范围的数据融合,可以并行高速地处理数据。RBF神经网络的优良特性使得其显示出比BP神经网络更强的生命力,正在越来越多的领域内替代BP神经网络。下图是一个输出神经元RBF网络的示意图:
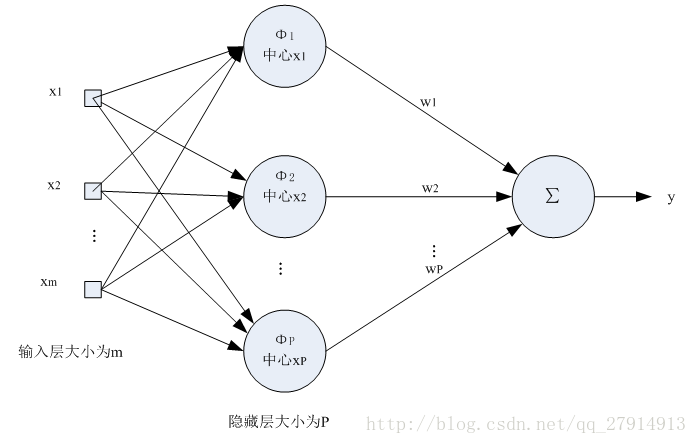
初始化参数:
同BP网络,RBF训练前同样需要初始化各类参数,RBF网络初始化参数有两种方法,一种是监督学习,一种是非监督学习。
(1)非监督方法:
数据中心的选取可以采用非监督的聚类算法,例如kmeans算法,直接求出k个数据中心不再变化,而扩展常数可根据各中心间距离来确定:
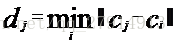
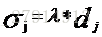
其中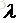
(2)监督方法:
最一般的情况,RBF函数中心、扩展常数、输出权值都应该采用监督学习算法进行训练,经历一个误差修正学习的过程,与BP网络的学习原理一样。同样采用梯度下降法,定义目标函数:
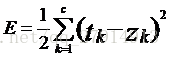
其中,c表示输出层神经元的个数,tk表示第k个输出神经元期望输出,zk表示实际输出。在本实验数据中,k取1。Zk由下式计算:
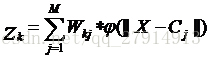
其中,M表示隐含层神经元的个数,Wkj表示隐含层到输出层的权值,X表示输入样本,Cj表示第j个隐含层神经元的数据中心。
分别计算目标函数E对权值Wkj、Cj和扩展常数σ的偏导,得到以下的更新公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









