







 K-means算法简要思想:算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。(1)适当选择k个类的初始中心;(2)在第k次迭代中,对任意一个样本,求其到各中心的距离,将该样本归到距离最短的中心所在的类;(3)利用均值等方法更新类的中心值;(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代
K-means算法简要思想:算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。(1)适当选择k个类的初始中心;(2)在第k次迭代中,对任意一个样本,求其到各中心的距离,将该样本归到距离最短的中心所在的类;(3)利用均值等方法更新类的中心值;(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代
K-means算法简要思想:
算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
(1)适当选择k个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到各中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,中心值保持不变或者满足变化距离小于一个精度或者达到最大迭代次数,则迭代结束,否则继续迭代。
实现步骤:
实验提供了两组数据(二维和三维),算法都能适用,这里我们以三维数据作为说明。首先读入数据,用scatter3将三维数据通过散点图显示出来:
load 3d-data.mat; %load数据,存在变量r中
figure(1);scatter3(r(:,1),r(:,2),r(:,3),'k');title('原始样本');结果见下图1:
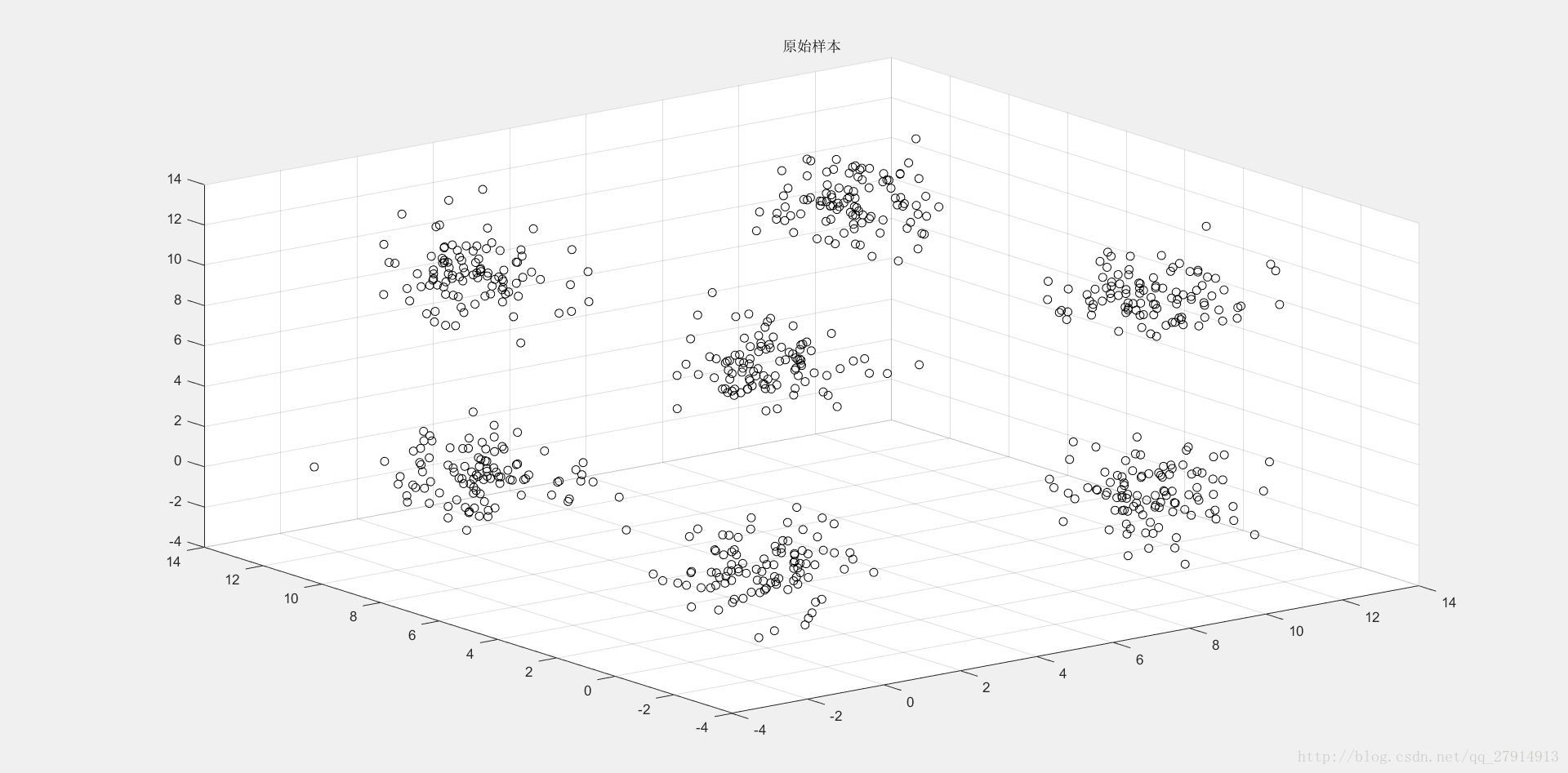
图1 三维样本集原始数据散点图
通过图1可以明显看出,样本集聚为7个簇,因此可将K初始化为7,然后随机选取7个中心点,存于clusters矩阵中:
clusters=zeros(K,cols);
for i=1:K
clusters(i,:)=r(floor(rand*rows),:); %随机选取K个质心
end质心选取后,需要计算每个样本点与K个质心的距离,存于dist矩阵中,并从此处开始迭代(for i=1:maxiter):
dist=zeros(rows,K);
for iter=1:maxiter
for i=1:rows
for j=1:K
dist(i,j)=sqrt(sum(( r(i,:)-clusters(j,:)).^2)); %dist存的是每一个样本数据与K个质心的距离,大小为rows*K
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2698
2698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









