







What’s problem?
根据策略梯度方法,参数更新方程式为:
策略梯度算法的硬伤就在更新步长 α ,当步长不合适时,更新的参数所对应的策略是一个更不好的策略,当利用这个更不好的策略进行采样学习时,再次更新的参数会更差,因此很容易导致越学越差,最后崩溃。所以,合适的步长对于强化学习非常关键。
所谓合适的步长是指当策略更新后,回报函数的值不能更差。如何选择这个步长?或者说,如何找到新的策略使得新的回报函数的值单调增,或单调不减。
What’s the proposed solution?
用
τ
表示一组状态-行为序列
[s0,u0,⋯,sH,uH]
,强化学习的回报函数为(用
π~
表示策略):
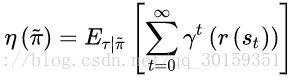
TRPO是找到新的策略,使得回报函数单调不减,一个自然地想法是能不能将新的策略所对应的回报函数分解成旧的策略所对应的回报函数+其他项。只要新的策略所对应的其他项大于等于零,那么新的策略就能保证回报函数单调不减。
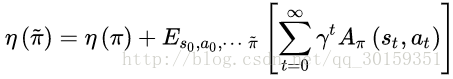
用
π
表示旧的策略,用
π~
表示新的策略。其中,
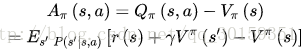
Aπ=Qπ(s,a)−Vπ(s)
称为优势函数,相当于用当前动作的期望reward减去所有动作的平均期望reward,能评价当前动作值函数相对于平均值的大小。
证明:
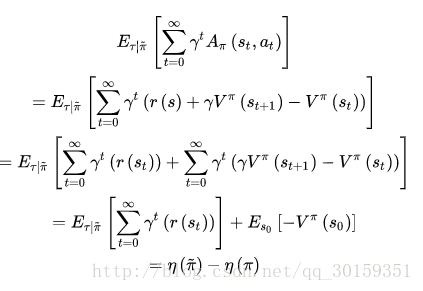
又优势函数的期望可以写成如下式:
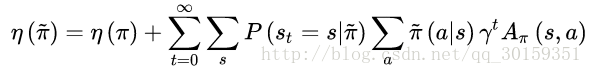
其中
P(st=s|π~)π~(a|s)
为 (s,a) 的联合概率
另外定义:
ρπ=P(s=s0)+γP(s=s1)+γ2P(s=s3)+⋯
则:
η(π~)=η(π)+∑sρπ(s)∑aπ~(a|s)Aπ(s,a)
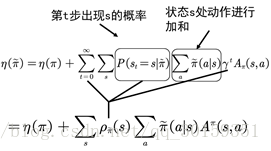
这时状态s的分布由新的策略产生,对新的策略严重依赖。
引入TRPO第一步是对状态分布进行处理。忽略状态分布的变化,依然采用旧的策略所对应的状态分布。这个技巧是对原代价函数的第一次近似。其实,当新旧参数很接近时,我们将用旧的状态分布代替新的状态分布也是合理的。代价函数转换为:
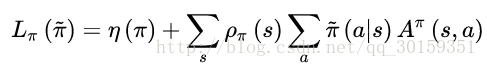
式中的第二项策略部分,这时的动作a是由新的策略
π~
产生。可是新的策略
π~
是带参数
θ
的,这个参数是未知的,因此无法用来产生动作。
于是论文中使用了important sampling。(http://blog.csdn.net/qq_30159351/article/details/72896239中有提及)
再利用 11−γEs∼ρθold[⋯] 代替 ∑sρθold(s) 得到回报函数为:
由此可知 η(π~) 和 Lπ(π~) 在 πθold 处一阶近似,即:
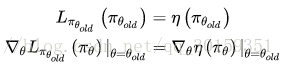
如图所示:
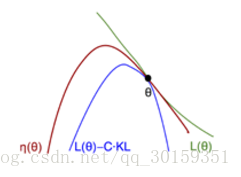
η(π~) 是真实策略回报,而 Lπ(π~) 是我们近似的回报函数。在 θold 处可以同时优化 η(π~) 和 Lπ(π~)
现在的问题在于如何确定步长:
论文中给出了如下不等式(细节见论文):
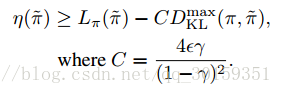
其中
DKL(π,π~)
为两个策略的KL散度,由上面这个公式,我们就可以单调得更新策略了:

使得
Mi
最大的策略即为我们要更新的策略,所以问题转换为:
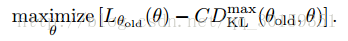
另外论文中采用在约束条件中,利用平均KL散度代替最大KL散度,即:
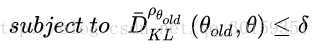
并用Q来代替A来简化,最终得到:
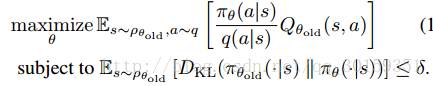
What’s the performance of the proposed solution?
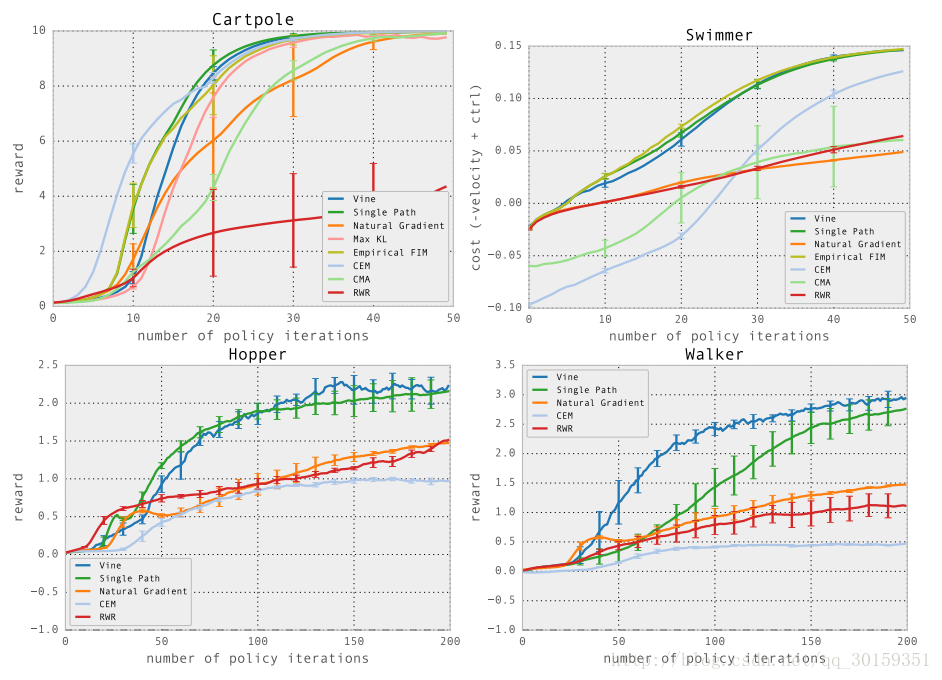
Figure 4. Learning curves for locomotion tasks, averaged across five runs of each algorithm with random initializations. Note that for the hopper and walker, a score of −1 is achievable without any forward velocity, indicating a policy that simply learned balanced standing, but not walking.
Conclusion
We proposed and analyzed trust region methods for optimizing stochastic control policies. We proved monotonic improvement for an algorithm that repeatedly optimizes a local approximation to the expected return of the policy with a KL divergence penalty, and we showed that an approximation to this method that incorporates a KL divergence constraint achieves good empirical results on a range of challenging policy learning tasks, outperforming prior methods.














 5247
5247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









