







 数据预处理中的规范化或标准化是为了消除度量单位影响,赋予所有属性相等权重。常用方法包括最小-最大规范化、z分数规范化和小数定标规范化。最小-最大规范化保持数据间联系,z分数规范化适用于未知数据范围或受离群点影响的情况,小数定标规范化通过移动小数点实现。规范化可能大幅改变原始数据,需保存参数以便统一处理未来数据。
数据预处理中的规范化或标准化是为了消除度量单位影响,赋予所有属性相等权重。常用方法包括最小-最大规范化、z分数规范化和小数定标规范化。最小-最大规范化保持数据间联系,z分数规范化适用于未知数据范围或受离群点影响的情况,小数定标规范化通过移动小数点实现。规范化可能大幅改变原始数据,需保存参数以便统一处理未来数据。
概述
所用的度量单位可能影响数据分析。例如,把height的度量单位从米制换成英寸,把weight的度量单位从公斤换成磅,可能导致的结果不一样。一般而言,用较小的单位表示属性将导致该属性具有较大的值域,因此趋向于使这样的属性具有较大的影响或较高的“权重”。为了帮助避免对度量单位选择的依赖性,数据应该规范化或标准化。这涉及到变换数据,使之落入较小的共同区间,如[-1, 1]或[0.0, 1.0]。规范化数据试图赋予所有的属性相等的权重。对于涉及神经网络的分类算法或基于距离度量的分类(如最近邻分类)和聚类,规范化特别有用。
经常使用的数据规范化的方法有:最小-最大规范化、z分数规范化和按小数定规范化。
1、最小-最大规范化
对原始数据进行线性变换。假设max_A 和 min_A分别为属性A的最小值和最大值。那么规范化通过公式:
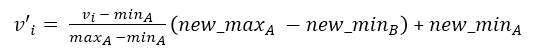
注意:最小-最大规范化保持原始数据值之间的联系。如果今后的输入数据落在A的原始数据值域之外,则该方法将面临“越界”错误。
2、z分数规范化(或零均值规范化)
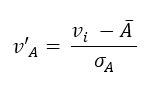
其中,分子的第二个字母表示A的均值,分母是A的标准差。
注意:当属性A的实际最小值和最大值未知,或离群点左右了最小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









