







线程格:
由 gridDim.x 个线程块组成
线程块:
由 blockDim.x 个线程组成
下面线程格就是由 4 个线程块组成,其中每个线程块有4个线程。
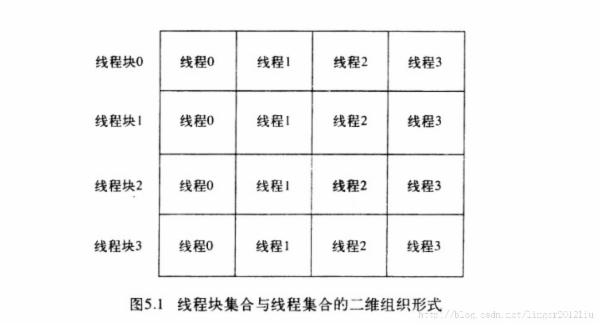
定位某个线程的方法:
threadIdx.x 表示该线程于所在线程块的索引
blockIdx.x 表示线程块于线程格的索引
根据 blockIdx.x 找到线程块,再根据 threadIdx.x 找到对应的线程。
----------------------------------------------------------------------------------------------------------------------
二维形式的线程格和二维形式的线程块
线程格:
由 gridDim.x*gridDim.y 个线程块组成
线程块:
由 blockDim.x*blockDim.y 个线程组成
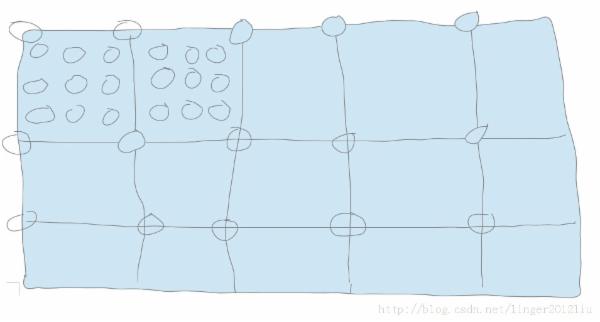
每个小矩形表示线程块,小矩形下面的圈表示线程。
定位某个线程的方法:
根据线程块的索引( blockIdx.x , blockIdx.y )找到线程块,就是上图每个小矩形的左上角的坐标。
然后根据线程的索引( threadIdx.x , threadIdx.y )找到线程。
代码表示举例:
一维 形式:
kernel<<<N,1>>>( );
为该函数启用 N 个线程块,每个线程块启用 1 个线程。
kernel<<<1,N>>>( );
为该函数启用 1 个线程块,每个线程块启用 N 个线程。
二维形式:
dim3 grid(DIM,DIM);
kernel<<<grid,1>>>();
为该函数启用 DIM*DIM 个线程块,每个线程块启用一个线程。
dim3 blocks(DIM/16,DIM/16);
dim3 threads(16,16);
kernel<<<blocks,threads>>>( );
为该函数启用 blocks 个线程块, threads 个线程。
内存共享和同步 :
所谓的共享内存,是指同一线程块中,里面线程共享。
线程同步(通过 syncthreads 实现)也是。块与块之间不影响。
当某些线程需要执行一条指令,而其他线程不需要执行时,这种情况就成为线程发散。
cuda 架构规定,除非线程块中的每个线程都执行了 syncthreads(), 否则没有任何线程
能执行 syncthreads 之后的指令。















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









