







 本文详细解析了Caffe中的softmax_loss层,包括其作为损失函数的两步计算过程:softmax概率归一化和损失计算。讨论了可选参数如ignore_label、normalize和normalization对损失计算的影响,并介绍了该层的常规及扩展使用场景,特别是在多维标签情况下的应用。
本文详细解析了Caffe中的softmax_loss层,包括其作为损失函数的两步计算过程:softmax概率归一化和损失计算。讨论了可选参数如ignore_label、normalize和normalization对损失计算的影响,并介绍了该层的常规及扩展使用场景,特别是在多维标签情况下的应用。
Loss Function
softmax_loss的计算包含2步:
(1)计算softmax归一化概率
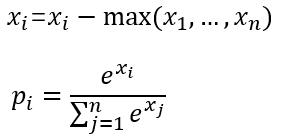
(2)计算损失
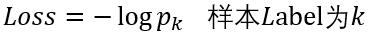
这里以batchsize=1的2分类为例:
设最后一层的输出为[1.2 0.8],减去最大值后为[0 -0.4],
然后计算归一化概率得到[0.5987 0.4013],
假如该图片的label为1,则Loss=-log0.4013=0.9130
可选参数
(1) ignore_label
int型变量,默认为空。
如果指定值,则label等于ignore_label的样本将不参与Loss计算,并且反向传播时梯度直接置0.
(2) norma
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









