







笔记整理时间:2017年1月20日
笔记整理者:王小草
向公司请了5天年假,提前回家过年。
长大了对过年反而没有太大期许,一切都是匆匆的路程,匆匆的相见,匆匆的碰杯与祝福,然后又匆匆回归朝夕规律地平淡。该想念的还是很想念,该失去的还是要失去。
希望家人和亲朋都健康幸福。
1.智能乘积ElementwiseProduct
1.1 概述
在训练模型的时候,经常会遇到这样的情况,特征之间的规模相差悬殊,对模型的训练产生了误导。此时我们需要人为的去平衡特征之间的规模,使他们都在同一个规模等级上,比如将0-1之间的特征,和100-1000之间的特征都分别乘以10,和除以100,使得两个特征的规模都在1-10之间。这个处理其实和归一化很像,只是归一化是使得所有的数据都在0-1之间分布。要注意的是规模化并不是保证所有数据一定落在某个区间内,而只是将不同的特征规模尽量放在一个水平上。
另一种情况,如果在特征中,有些特征特别重要,有些则相对重要度较低,那么需要给重要的特征以较高的权重,也可以使用本方法,将特征都乘上对应的权重从而形成新的特征组。
具体如何处理就要看具体情况的需求了。
1.2 sparkML提供的算法包的使用
ElementwiseProduct的处理逻辑非常简单,没有ml提供的方法,其实我们自己也能写出代码。
我们输入的特征一般都是Vector形式的,Vector中的每个元素表示该样本的各个特征值。创建一个与特征Vector等长的权重Vector–W,新的特征向量就是原来的特征向量与权重向量的乘积,即两个向量中位置相同的元素两两相乘。如下图:
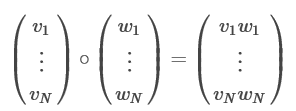
代码
object FeatureTransform01 {
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val conf = new SparkConf().setAppName("FeatureTransform01").setMaster("local")
val sc = new SparkContext(conf)
val spark = SparkSession
.builder()
.appName("Feature Extraction")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// 创建一组特征向量,a,b是两个样本,分别有3个特征
val dataFrame = spark.createDataFrame(Seq(
("a", Vectors.dense(1.0, 2.0, 3.0)),
("b", Vectors.dense(4.0, 5.0, 6.0)))).toDF("id", "vector")
println("特征向量:")
dataFrame.show(false)
// 创建一组权重,分别是3个特征的权重
val transformingVector = Vectors.dense(0.0, 1.0, 2.0)
// 建立转换的模型
val tran 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2518
2518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









