







王小草SparkML笔记
笔记整理时间:2017年1月10日
笔记整理者:王小草
今日计事:
除开上周五在家工作,2017年的工作日从3号开始今天第5次上班迟到,无论起多早每天都是会迟几分钟。第一次挤不上地铁,第二次地铁延误,第三次地铁卡刷不出去到服务台排队,第四次上错了终点站的列车,于是今天提早半小时出门,绕远路到起点站,带上了两张充满钱的地铁卡,上车前看准了对的终点站的车,而且还侥幸偶遇了一个空位,怎么说都是万无一失的呢。然而由于地铁冷风太大,肚子疼得死去活来终于在半路舍弃我的爱座下车出站四处找厕所。。回来车站居然3次眼睁睁得经历了看着车门打开,尝试把自己塞进去,关门警报声响,赶紧把自己扯出来,等待下一班列车的残酷过程。
“滴~9点04分迟到打卡”
哈哈哈,我在笑着流泪。
上一章讲了一个文本特征的提取方法:TF-IDF词项文档矩阵。在之前的许多项目与业务中,这是选择的最优方法,对于那些建立基于文本的机器学习模型的时候,我们都会先用TF-IDF提取文档的特征,将文档变成一个词向量的形式,然后再进行模型的学习与训练。
这一章,我要讲一个更优的方法,通过Word2Vec的方法建立词嵌入矩阵,以此来作为词的表征。
之所以暂且称之为最优,是因为Word2Vec是基于神经网络来训练得到的,每个词拥有一个向量来表征它,词和词之间可以通过向量来求相似性,并且向量是非离散的,这都是是TF-IDF所不具备的优势。当然优势也不是绝对的,Word2Vec的训练需要较多的资源,耗时也相对较长。总体上而言,经过实践的检验,Word2Vec的确表现甚好。
本文的结构分成4部分:首先介绍最初的神经网络语言模型NNLM,然后介绍Word2Vec的CBOM模型, 和介绍Word2Vec的skip-gram模型,最后给出spark实现Word2Vec的代码和解释。
关于理论部分其实在“王小草深度学习笔记”中专门有一章是介绍自然语言的向量模型的,故本文将其部分内容搬运过来。要了解其他传统的文档与词的表征方式,可以直接阅读该文。
1. 神经网络语言模型NNLM
NNLM全称Neural Network Language model,直接从语言模型出发,将模型最优化过程转化为求词向量表示的过程。
既然离散的表示有辣么多缺点,于是有小伙伴就尝试着用模型最优化的过程去转换词向量了。
1.1 目标函数
NNLM的目标函数如下:
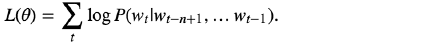
比如”我/是/中国/人“这句话,Wt是“人”,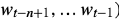 是“人”前面的词,前面的词的长度我们叫前向窗口函数,窗口长度为n-1,因为只有前面的词,所以是非对称的前向窗口函数。也就是说目标函数求的是,当“我”“是”“中国”这几个词出现的时候,后面出现“人”的概率的最大值。
是“人”前面的词,前面的词的长度我们叫前向窗口函数,窗口长度为n-1,因为只有前面的词,所以是非对称的前向窗口函数。也就是说目标函数求的是,当“我”“是”“中国”这几个词出现的时候,后面出现“人”的概率的最大值。
这个窗口会滑动遍历整个语料库并且求和,计算量正比与语料库的大小。
概率P满足归一化条件,这样不同位置t处的概率才能相加,即:
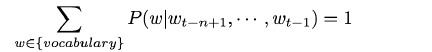
也就是说,当出现“我”“是”“中国”这几个词时,会计算后面出现语料库中的每一个词的概率,所有的概率相加为1.
1.2 NNLM的结构
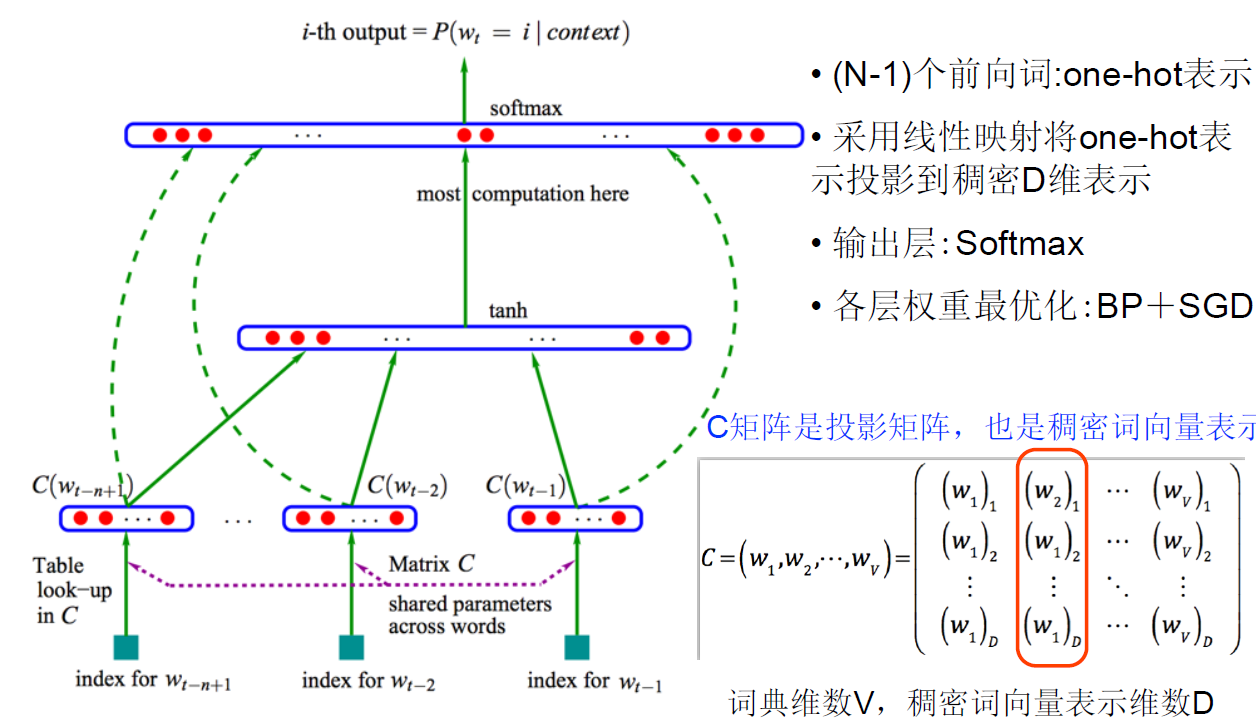
首先,不要
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 551
551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









