







 本文介绍了CVPR2017收录的论文,研究如何使用语义自编码器解决zero-shot learning问题,减少领域漂移影响。通过在自编码器中加入约束,使编码后的数据能恢复原样,从而实现监督学习。这种方法不仅在多个数据集上取得最佳zero-shot learning结果,还能应用于监督聚类问题。
本文介绍了CVPR2017收录的论文,研究如何使用语义自编码器解决zero-shot learning问题,减少领域漂移影响。通过在自编码器中加入约束,使编码后的数据能恢复原样,从而实现监督学习。这种方法不仅在多个数据集上取得最佳zero-shot learning结果,还能应用于监督聚类问题。
论文地址:https://arxiv.org/pdf/1704.08345.pdf
代码地址:https://elyorcv.github.io/projects/sae
该论文已经被CVPR2017收录。主要是关于利用语义自编码器实现zero-shot learning的工作。一定程度上解决了训练集和测试集的领域漂移(domain shift)问题。整个算法最核心的地方是在自编码器进行编码和解码时,使用了原始数据作为约束,即编码后的数据能够尽可能恢复为原来的数据。该方法在6个数据集上的zero-shot learning结果都为目前最好。该方法还能解决监督聚类问题(supervised clustering problem),并也能取得目前最好的效果。
作者使用了一个十分基础的自编码器对原始样本进行编码,其结构如图1所示,其中X为样本,S为自编码器的隐层,x^为由隐层还原为样本的表示。需要注意的是隐藏层S层为属性层,它不仅仅是原样本的另一种表示,它同时也有着清晰的语义。
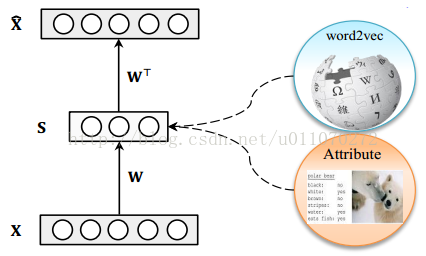
图1 自编码器结构
贡献
(1)提出了一种新的用于zero-shot learning语义自编码模型;(2)提出了模型对应的高效的学习算法;(3)算法具有扩展性,可以用于监督聚类问题(supervised clustering问题)。实验证明,该算法在多个数据集上能取得最好效果。
映射领域漂移(Projection domain shift)
对于zero-shot learning问题,由于训练模型时,对于测试数据类别是不可见的,因此,当训练集和测试集的类别相差很大的时候,比如一个里面全是动物,另一个全是家具,在这种情况下,传统zero-shot learning的效果将受到很大的影响。
算法内容
语义自编码器
上文已经提到了作者所使用的自编码器,它只有一层隐层,且隐层的维数要小于输入层的维度。设输入层到隐层的映射为W,隐层到输出层的映射为W*,W和W*是对称的,即有W*等于W的转置。由于我们希望输入和输出尽可能相似,则可设目标函数为:
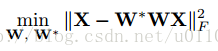
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









