






使用Caffe复现DeepID实验
本实验使用Casia-Webface part2的切图来复现DeepID实验结果。
- DeepID网络配置文件
- 训练验证数据组织
- 实验结果
- 结果分析
DeepID网络配置文件
-下面给出deepId_train_test.prototxt的内容
name: “deepID_network”
layer {
name: ”input_data” top: “data” top: “label” type: “Data” data_param { source: “dataset/deepId_train_lmdb” backend: LMDB batch_size: 128 }
transform_param {
mean_file: ”dataset/deepId_mean.proto” }
include {
phase: TRAIN }
}
layer {
name: ”input_data” top: “data” top: “label” type: “Data” data_param { source: “dataset/deepId_test_lmdb” backend: LMDB batch_size: 128 }
transform_param {
mean_file: ”dataset/deepId_mean.proto” }
include {
phase: TEST }
}
layer {
name: ”conv1” type: “Convolution” bottom: “data” top: “conv1” param { name: “conv1_w” lr_mult: 1 decay_mult: 0 }
param {
name: ”conv1_b” lr_mult: 2 decay_mult: 0 }
convolution_param {
num_output: 20 kernel_size: 4 stride: 1 weight_filler { type: “gaussian” std: 0.01 }
bias_filler {
type: ”constant” }
}
}
layer {
name: ”relu1” type: “ReLU” bottom: “conv1” top: “conv1” }
layer {
name: ”pool1” type: “Pooling” bottom: “conv1” top: “pool1” pooling_param { pool: MAX kernel_size: 2 stride: 2 }
}
layer {
name: ”conv2” type: “Convolution” bottom: “pool1” top: “conv2” param { name: “conv2_w” lr_mult: 1 decay_mult: 0 }
param {
name: ”conv2_b” lr_mult: 2 decay_mult: 0 }
convolution_param {
num_output: 40 kernel_size: 3 stride: 1 weight_filler { type: “gaussian” std: 0.01 }
bias_filler {
type: ”constant” }
}
}
layer {
name: ”relu2” type: “ReLU” bottom: “conv2” top: “conv2” }
layer {
name: ”pool2” type: “Pooling” bottom: “conv2” top: “pool2” pooling_param { pool: MAX kernel_size: 2 stride: 1 }
}
layer {
name: ”conv3” type: “Convolution” bottom: “pool2” top: “conv3” param { name: “conv3_w” lr_mult: 1 decay_mult: 0 }
param {
name: ”conv3_b” lr_mult: 2 decay_mult: 0 }
convolution_param {
num_output: 60 kernel_size: 3 stride: 1 weight_filler { type: “gaussian” std: 0.01 }
bias_filler {
type: ”constant” }
}
}
layer {
name: ”relu3” type: “ReLU” bottom: “conv3” top: “conv3” }
layer {
name: ”pool3” type: “Pooling” bottom: “conv3” top: “pool3” pooling_param { pool: MAX kernel_size: 2 stride: 2 }
}
layer {
name: ”conv4” type: “Convolution” bottom: “pool3” top: “conv4” param { name: “conv4_w” lr_mult: 1 decay_mult: 0 }
param {
name: ”conv4_b” lr_mult: 2 decay_mult: 0 }
convolution_param {
num_output: 80 kernel_size: 2 stride: 1 weight_filler { type: “gaussian” std: 0.01 }
bias_filler {
type: ”constant” }
}
}
layer {
name: ”relu4” type: “ReLU” bottom: “conv4” top: “conv4” }
layer {
name: ”fc160_1” type: “InnerProduct” bottom: “pool3” top: “fc160_1” param { name: “fc160_1_w” lr_mult: 1 decay_mult: 1 }
param {
name: ”fc160_1_b” lr_mult: 2 decay_mult: 1 }
inner_product_param {
num_output: 160 weight_filler { type: “gaussian” std: 0.01 }
bias_filler {
type: ”constant” }
}
}
layer {
name: ”fc160_2” type: “InnerProduct” bottom: “conv4” top: “fc160_2” param { name: “fc160_2_w” lr_mult: 1 decay_mult: 1 }
param {
name: ”fc160_2_b” lr_mult: 2 decay_mult: 1 }
inner_product_param {
num_output: 160 weight_filler { type: “gaussian” std: 0.01 }
bias_filler {
type: ”constant” }
}
}
layer {
name: ”fc160” type: “Eltwise” bottom: “fc160_1” bottom: “fc160_2” top: “fc160” eltwise_param { operation: SUM }
}
layer {
name: ”dropout” type: “Dropout” bottom: “fc160” top: “fc160” dropout_param { dropout_ratio: 0.4 }
}
layer {
name: ”fc_class” type: “InnerProduct” bottom: “fc160” top: “fc_class” param { name: “fc_class_w” lr_mult: 1 decay_mult: 1 }
param {
name: ”fc_class_b” lr_mult: 2 decay_mult: 1 }
inner_product_param {
num_output: 10499 weight_filler { type: “gaussian” std: 0.01 }
bias_filler {
type: ”constant” }
}
}
layer {
name: ”loss” type: “SoftmaxWithLoss” bottom: “fc_class” bottom: “label” top: “loss” }
layer {
name: ”accuracy” type: “Accuracy” bottom: “fc_class” bottom: “label” top: “accuracy” include { phase: TEST }
}
- 下面是deepId_solver.prototxt
net: "deepId_train_test.prototxt"
# conver the whole test set. 484 * 128 = 62006 images.
test_iter: 484
# Each 6805 is one epoch, test after each epoch
test_interval: 6805
base_lr: 0.01
momentum: 0.9
weight_decay: 0.005
lr_policy: "step"
# every 30 epochs, decrease the learning rate by factor 10.
stepsize: 204164
gamma: 0.1
# power: 0.75
display: 200
max_iter: 816659 # 120 epochs.
snapshot: 10000
snapshot_prefix: “trained_model/deepId"
solver_mode: GPU
训练数据组织
数据来自CASIA-Webface的切图(人脸对齐,缩放到一个固定的比例,比如55*55),CASIA-Webface共10575个人,每个人的图片数量从几十到几百不等。类别数量之间严重不平衡,这里,我试验了两个方式(没有用全部的10575类,如deepId_train_test.prototxt定义的那样,只使用了10499类,如果某类别的图片数目过少,就不使用它):
1. 让训练集的每一类数目完全一样,比如我的实验中为训练集每个人50张图片。
2. 图片数目最多的那一类于最少的哪一类的数目比例不超过3:1(个人愚见,不知是否有道理,请高手指点一二)。
验证集是从每一类别的都随机挑选一部分不在训练集中的图片来做验证。
-下面的prepare_deepId_data.py是我组织训练测试数据的Python代码,仅供参考(高手请拍砖)。
import os
from random import shuffle
import cPickle
def check_parameter(param, param_type, create_new_if_missing=False):
assert param_type == 'file' or param_type == 'directory'
if param_type == 'file':
assert os.path.exists(param)
assert os.path.isfile(param)
else:
if create_new_if_missing is True:
if not os.path.exists(param):
os.makedirs(param)
else:
assert os.path.isdir(param)
else:
assert os.path.exists(param)
assert os.path.isdir(param)
def listdir(top_dir, type='image'):
# type_len = len(type)
tmp_file_lists = os.listdir(top_dir)
file_lists = []
if type == 'image':
for e in tmp_file_lists:
if e.endswith('.jpg') or e.endswith('.png') or e.endswith('.bmp'):
file_lists.append(e)
elif type == 'dir':
for e in tmp_file_lists:
if os.path.isdir(top_dir + e):
file_lists.append(e)
else:
raise Exception('Unknown type in listdir')
return file_lists
def prepare_deepId_data_eq(src_dir, tgt_dir, num_threshold=50):
check_parameter(src_dir, 'directory')
check_parameter(tgt_dir, 'directory', True)
if src_dir[-1] != '/':
src_dir += '/'
if tgt_dir[-1] != '/':
tgt_dir += '/'
class_lists = listdir(src_dir, 'dir')
print '# class is : %d' % len(class_lists)
class_table = {}
num = 0
for e in class_lists:
assert e not in class_table
class_table[e] = listdir(''.join([src_dir, e]), 'image')
if len(class_table[e]) > num_threshold:
num += 1
print 'There are %d people whose number of images is greater than %d.' % (num, num_threshold)
print 'Use %d num people to train the deepId net..' % num
train_set = []
test_set = []
label = 0
dirname2label = {}
for k, v in class_table.iteritems():
if len(v) >= num_threshold:
shuffle(v)
assert k not in dirname2label
dirname2label[k] = label
i = 0
for i in xrange(num_threshold):
train_set.append((k + '/' + v[i], label))
i += 1
num_test_images = min(num_threshold / 3, len(v) - num_threshold)
for j in xrange(num_test_images):
test_set.append((k + '/' + v[i + j], label))
label += 1
f = open(tgt_dir + 'dirname2label.pkl', 'wb')
cPickle.dump(dirname2label, f, 0)
f.close()
f = open(tgt_dir + 'deepId_train_lists.txt', 'w')
for e in train_set:
print >> f, e[0], ' ', e[1]
f.close()
f = open(tgt_dir + 'deepId_test_lists.txt', 'w')
for e in test_set:
print >> f, e[0], ' ', e[1]
f.close()
def prepare_deepId_data_dif(src_dir, tgt_dir, num_threshold=20, add_all=False):
check_parameter(src_dir, 'directory')
check_parameter(tgt_dir, 'directory', True)
if src_dir[-1] != '/':
src_dir += '/'
if tgt_dir[-1] != '/':
tgt_dir += '/'
class_lists = listdir(src_dir, 'dir')
print '# class is : %d' % len(class_lists)
class_table = {}
num = 0
for e in class_lists:
assert e not in class_table
class_table[e] = listdir(''.join([src_dir, e]), 'image')
if len(class_table[e]) > num_threshold:
num += 1
print 'There are %d people whose number of images is greater than %d.' % (num, num_threshold)
print 'Use %d num people to train the deepId net, we do not care the validation set result...' % num
train_set = []
test_set = []
label = 0
dirname2label = {}
for k, v in class_table.iteritems():
if len(v) >= num_threshold:
shuffle(v)
assert k not in dirname2label
dirname2label[k] = label
i = 0
for i in xrange(num_threshold):
train_set.append((k + '/' + v[i], label))
i += 1
j = 0
num_test_images = min(int(num_threshold / 3), len(v) - num_threshold)
for j in xrange(num_test_images):
test_set.append((k + '/' + v[i + j], label))
if len(v) > num_threshold + num_test_images:
offset = j + 1 + i
if add_all is False:
# add the rest of all images or 3 times the num_threshold images to the training set....
num_left = len(v) - num_threshold - num_test_images
num_left = min(num_left, num_threshold)
for ii in xrange(num_left):
train_set.append((k + '/' + v[ii + offset], label))
else:
# print 'Adding the rest of all data into training set.'
while offset < len(v):
train_set.append((k + '/' + v[offset], label))
offset += 1
label += 1
f = open(tgt_dir + 'dirname2label.pkl', 'wb')
cPickle.dump(dirname2label, f, 0)
f.close()
f = open(tgt_dir + 'deepId_train_lists.txt', 'w')
for e in train_set:
print >> f, e[0], ' ', e[1]
f.close()
f = open(tgt_dir + 'deepId_test_lists.txt', 'w')
for e in test_set:
print >> f, e[0], ' ', e[1]
f.close()
if __name__ == '__main__':
prepare_deepId_data_eq('CASIA-Webface/','dataset', 50)
prepare_deepId_data_dif('CASIA-Webface/','dataset', 20, True)
#后缀eq表示每一类数目一样,50表示希望每一类都有50幅图片,dif每一类数目不一样。
实验结果
实验过程是抽取已经训练好了的模型,将lfw的测试数据抽取特征fc160维的特征,然后对特征用cos距离或者joint bayesian距离来做人脸验证。
-训练过程loss曲线如下:
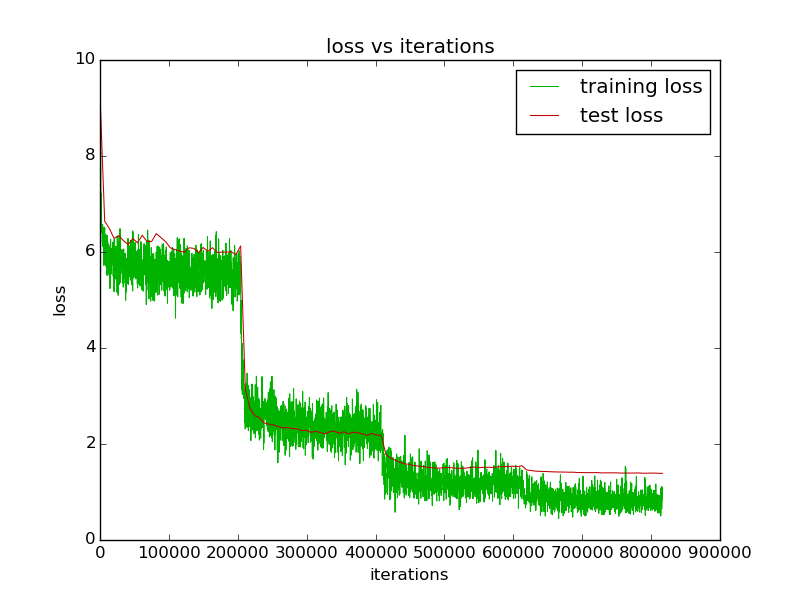
-训练过程的accuracy曲线如下:
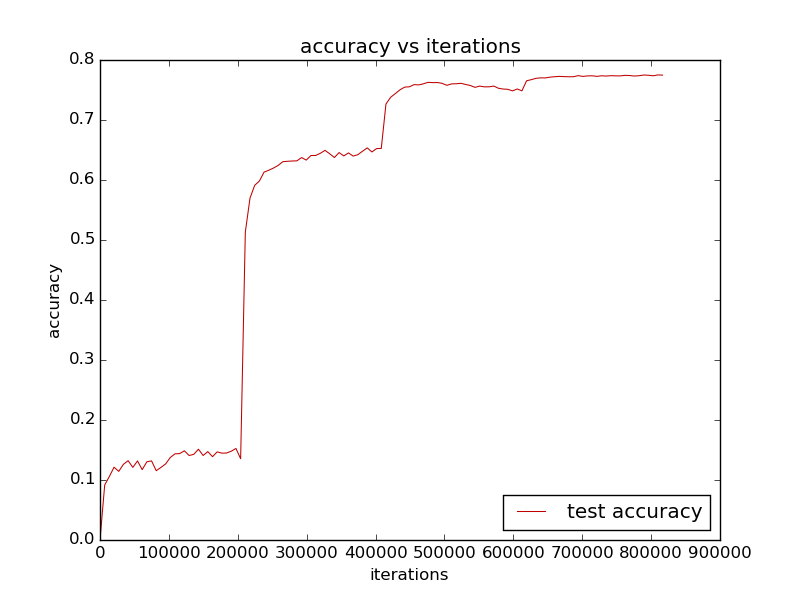
-使用cos距离度量在LFW上的roc曲线以及正负样本分布图
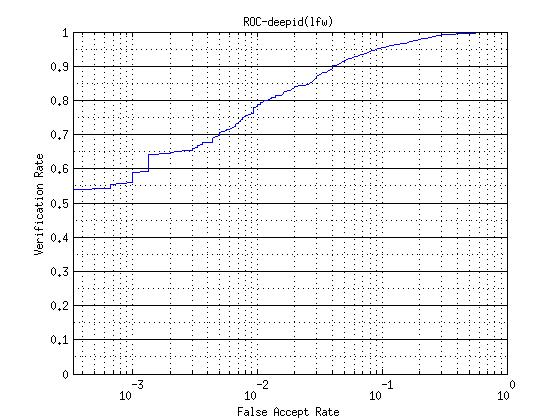
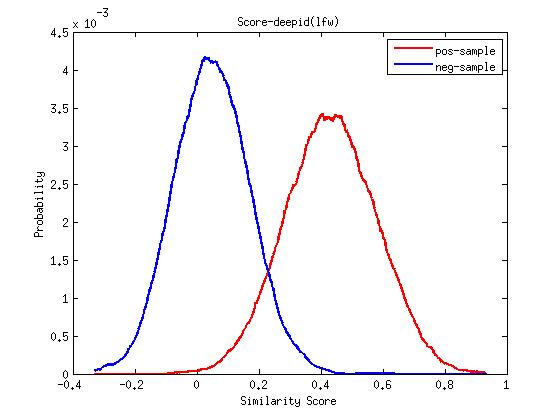
-使用joint bayesian在LFW上的roc曲线以及正负样本分布图
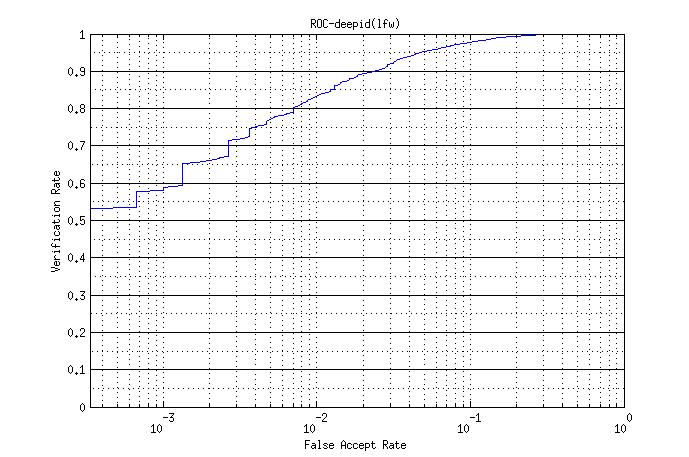
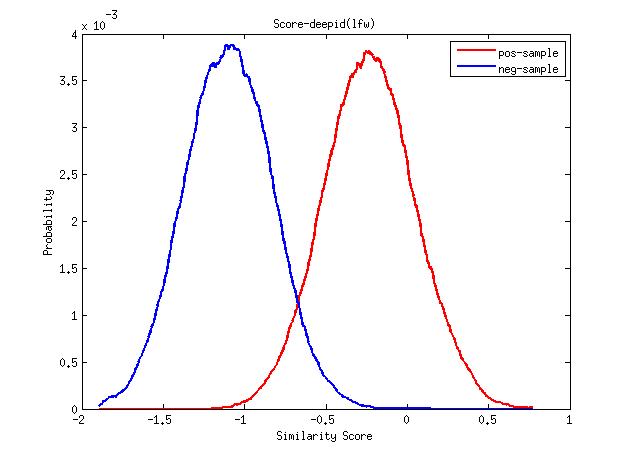
-在LFW上的单part模型结果如下:
| metric | mean accuracy | std |
|---|---|---|
| cos | 0.9395 | 0.0035 |
| joint bayesian | 0.9545 | 0.0045 |
实验结果分析说明
本实验单模型只有95.45%的准确率,没有到97%左右(实验室师兄用convnet复现得到的单part的准确率),存在如此大的差距。一方面还是参数没调好,训练的不够好,数据组织欠妥,另一方面也许是deepID的第3个conv层和第4个conv层用的local卷积,人脸不同区域用不同filter来提取特征能得到更加丰富的特征?
ps: caffe的local卷积太慢了,有点不能忍。 话说happynear大神deepID的LFW上了97.17,不得不佩服大神调参能力,还是自己太菜了。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









