







神经网络的训练过程通常分为两个阶段:前向传播和反向传播。
前向传播如下图所示,原理比较简单
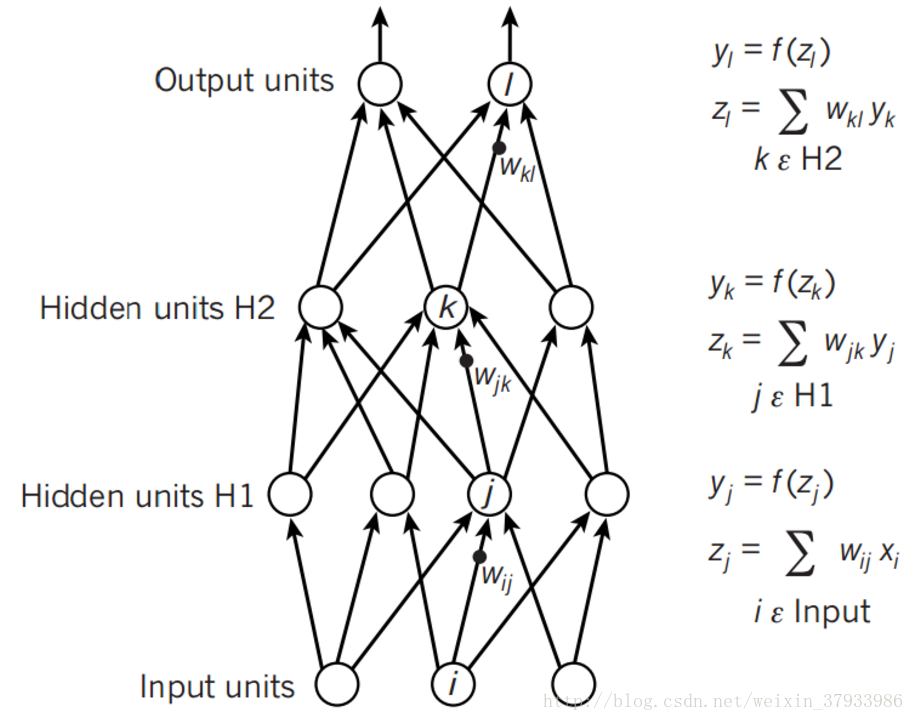
上一层的神经元与本层的神经元有连接,那么本层的神经元的激活等于上一层神经元对应的权值进行加权和运算,最后通过一个非线性函数(激活函数)如ReLu,sigmoid等函数,最后得到的结果就是本层神经元的输出。逐层逐神经元通过该操作向前传播,最终得到输出层的结果。
反向传播由最后一层开始,逐层向前传播进行权值的调整,如下图所示:
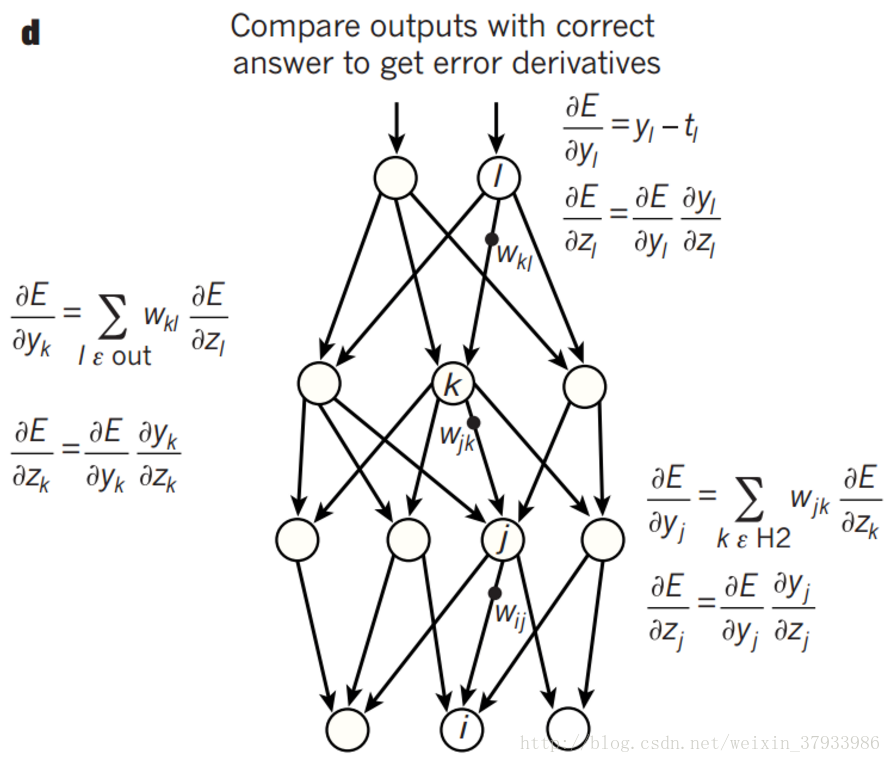
前向传播得到的结果与实际的结果得到一个偏差,然后通过梯度下降法的思想,通过偏导数与残差的乘积通过从最后一层逐层向前去改变每一层的权重。通过不断的前向传播和反向传播不断调整神经网络的权重,最终到达预设的迭代次数或者对样本的学习已经到了比较好的程度后,就停止迭代,那么一个神经网络就训练好了。
那么为什么会出现梯度消失的现象呢?因为通常神经网络所用的激活函数是sigmoid函数,这个函数有个特点,就是能将负无穷到正无穷的数映射到0和1之间,并且对这个函数求导的结果是 f′(x)=f(x)(1−f(x)) 。因此两个0到1之间的数相乘,得到的结果就会变得很小了。神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差就因为乘了很多的小于1的数而越来越小,最终就会变为0,从而导致层数比较浅的权重没有更新,这就是梯度消失。
那么什么是梯度爆炸呢?梯度爆炸就是由于初始化权值过大,前面层会比后面层变化的更快,就会导致权值越来越大,梯度爆炸的现象就发生了。
如何解决梯度消失或者梯度爆炸呢?
用ReLU激活函数来替代sigmoid函数。
Rectified linear unit(ReLU) 函数是深度神经网络在2015年最流行的激活函数。它的激活函数可以表示为
f(x)=max(0,x)
,它更加符合神经元的激活原理。它的一个平滑解析函数为
f(x)=ln(1+ex)
,被称为softplus function。softplus 的微分就是logistic函数
f(x)=1/(1+e−x)
。
ReLU函数有几种变体:
Noisy ReLUs:
将高斯噪声加入,
f(x)=max(0,x+N(0,δ(x)))
,常用在机器视觉里面。
Leaky ReLUs:
当unit没有被激活时,允许小的非零的梯度。
f(x)=x,x>0
,
f(x)=0.01x,x<=0
。
优点:
Biological plausibility:单边,相比于反对称结构(antisymmetry)的tanh
Sparse activation:基本上随机初始化的网络,只有有一半隐含层是处于激活状态,其余都是输出为0
efficient gradient propagation:不像sigmoid那样出现梯度消失的问题
efficient computation:只需比较、乘加运算。
使用rectifier 作为非线性激活函数使得深度网络学习不需要pre-training,在大、复杂的数据上,相比于sigmoid函数等更加快速和更有效率。
标准的sigmoid输出不具备稀疏性,需要通过惩罚因子来训练一堆接近于0的冗余数据,从而产生稀疏数据,比如L1,L2或者student-t作为惩罚因子,进行regularization。而ReLU为线性修正,是purelin的折线版,作用是如果计算输出小于0,就让它等于0,否则保持原来的值,这是一种简单粗暴地强制某些数据为0的方法,然而经实践证明,训练后的网络完全具备适度的稀疏性,而且训练后的可视化效果和传统pre-training的效果很相似。这说明了ReLU具备引导适度稀疏的能力。
从函数图形上看,ReLU比sigmoid更接近生物学的激活模型。
实际测量数据:纵坐标轴是神经元的放电速率(Firing Rate);横轴是毫秒(ms)
基于生物学的数学规则化激活模型(LIF)
(Softplus是ReLU的圆滑版,公式为:g(x)=log(1+e^x),从上面的结果看,效果比ReLU稍差)
ReLU在经历预训练和不经历预训练时的效果差不多,而其它激活函数在不用预训练时效果就差多了。ReLU不预训练和sigmoid预训练的效果差不多,甚至还更好。
相比之下,ReLU的速度非常快,而且精确度更高。
因此ReLU在深度网络中已逐渐取代sigmoid而成为主流。
ReLU导数(分段):
x <= 0时,导数为0
x > 0时,导数为1
早期多层神经网络如果用sigmoid函数或者hyperbolic tangent作为激活函数,如果不进行pre-training的话,会因为gradient vanishing problem而无法收敛。
而预训练的用处:规则化,防止过拟合;压缩数据,去除冗余;强化特征,减小误差;加快收敛速度。而采用ReLu则不需要进行pre-training。














 2466
2466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









