







 本文介绍了神经网络训练中的梯度消失和梯度爆炸问题,重点讨论了sigmoid激活函数导致的梯度消失现象。为了解决这个问题,文章推荐使用ReLU及其变体,如Leaky ReLU,因为它们能更有效地传播梯度,避免梯度消失,并具有生物合理性、稀疏激活和高效计算等优点。ReLU在深度学习中已成为主流激活函数,且不需要预训练即可取得较好的效果。
本文介绍了神经网络训练中的梯度消失和梯度爆炸问题,重点讨论了sigmoid激活函数导致的梯度消失现象。为了解决这个问题,文章推荐使用ReLU及其变体,如Leaky ReLU,因为它们能更有效地传播梯度,避免梯度消失,并具有生物合理性、稀疏激活和高效计算等优点。ReLU在深度学习中已成为主流激活函数,且不需要预训练即可取得较好的效果。
神经网络的训练过程通常分为两个阶段:前向传播和反向传播。
前向传播如下图所示,原理比较简单
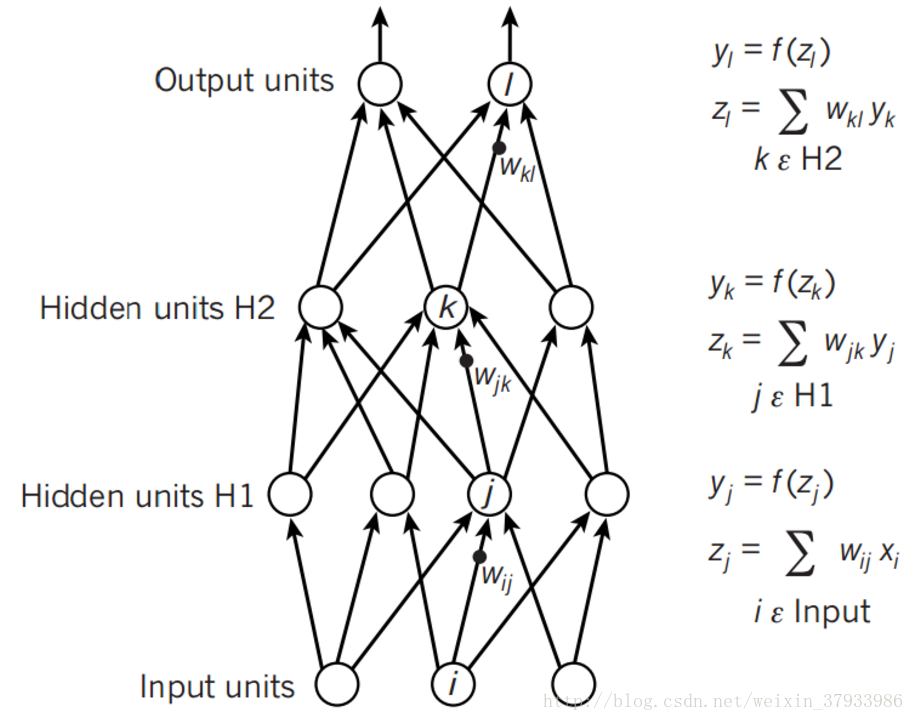
上一层的神经元与本层的神经元有连接,那么本层的神经元的激活等于上一层神经元对应的权值进行加权和运算,最后通过一个非线性函数(激活函数)如ReLu,sigmoid等函数,最后得到的结果就是本层神经元的输出。逐层逐神经元通过该操作向前传播,最终得到输出层的结果。
反向传播由最后一层开始,逐层向前传播进行权值的调整,如下图所示:
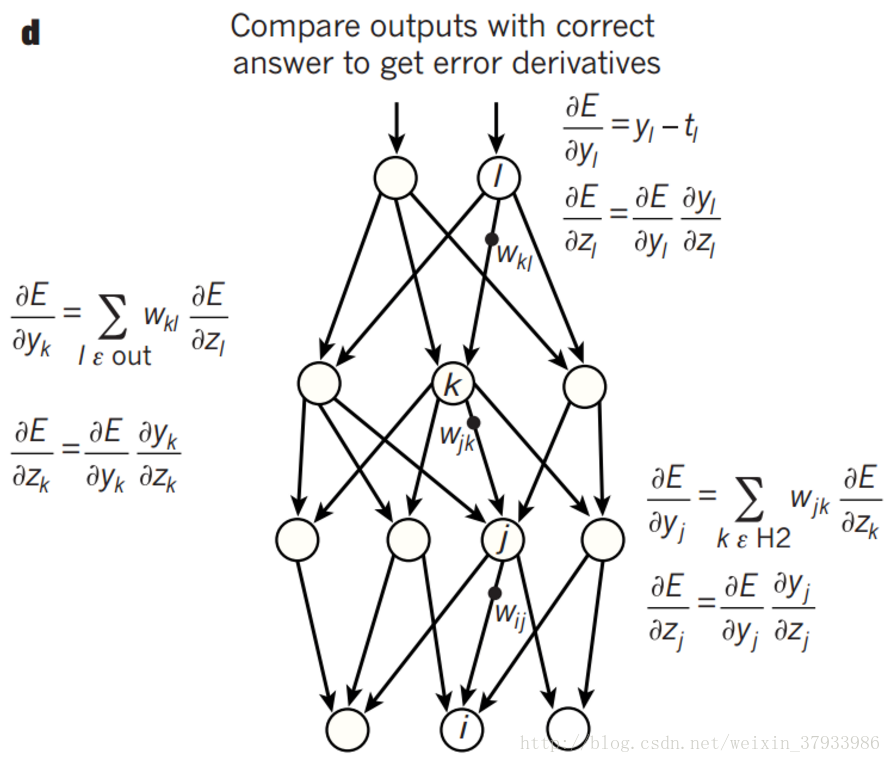
前向传播得到的结果与实际的结果得到一个偏差,然后通过梯度下降法的思想,通过偏导数与残差的乘积通过从最后一层逐层向前去改变每一层的权重。通过不断的前向传播和反向传播不断调整神经网络的权重,最终到达预设的迭代次数或者对样本的学习已经到了比较好的程度后,就停止迭代,那么一个神经网络就训练好了。
那么为什么会出现梯度消失的现象呢?因为通常神经网络所用的激活函数是sigmoid函数,这个函数有个特点,就是能将负无穷到正无穷的数映射到0和1之间,并且对这个函数求导的结果是 f′(x)=f(x)(1−f(x))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









