







KNN算法(K-NearestNeighbor)详解(手写python代码实现+sklearn实现) 数据挖掘 分类算法 例子讲解 优缺点特点总结
1、KNN算法(K-NearestNeighbor)的介绍
为了判定未知样本的类别,以全部训练样本作为代表点,计算未知样本与所有训练样本的距离,并以最近邻者的类别较多的作为决策未知样本类别的唯一依据。

度量方式包括:欧式距离,曼哈顿距离,切比雪夫距离等

2、KNN算法的优缺点
-
算法的优点就是简单易懂
-
算法的缺点是
1、只适合小数据集(每次预测都要用到全部的数据集)
2、数据不平衡,也就是类别分布不统一的话,会打破平衡
3、必须使用数据标准化,量纲不同的话,会导致结果被量纲大的数据所影响
4、不适合特征维度过多的数据
5、KNN是基于局部信息进行预测,对噪声非常敏感,K值的选取很重要,过小会导致对噪声敏感(容易过拟合),过大会包含过多其他的类别(容易欠拟合),影响最终的结果
3、KNN算法的手写实现
手写算法思路:

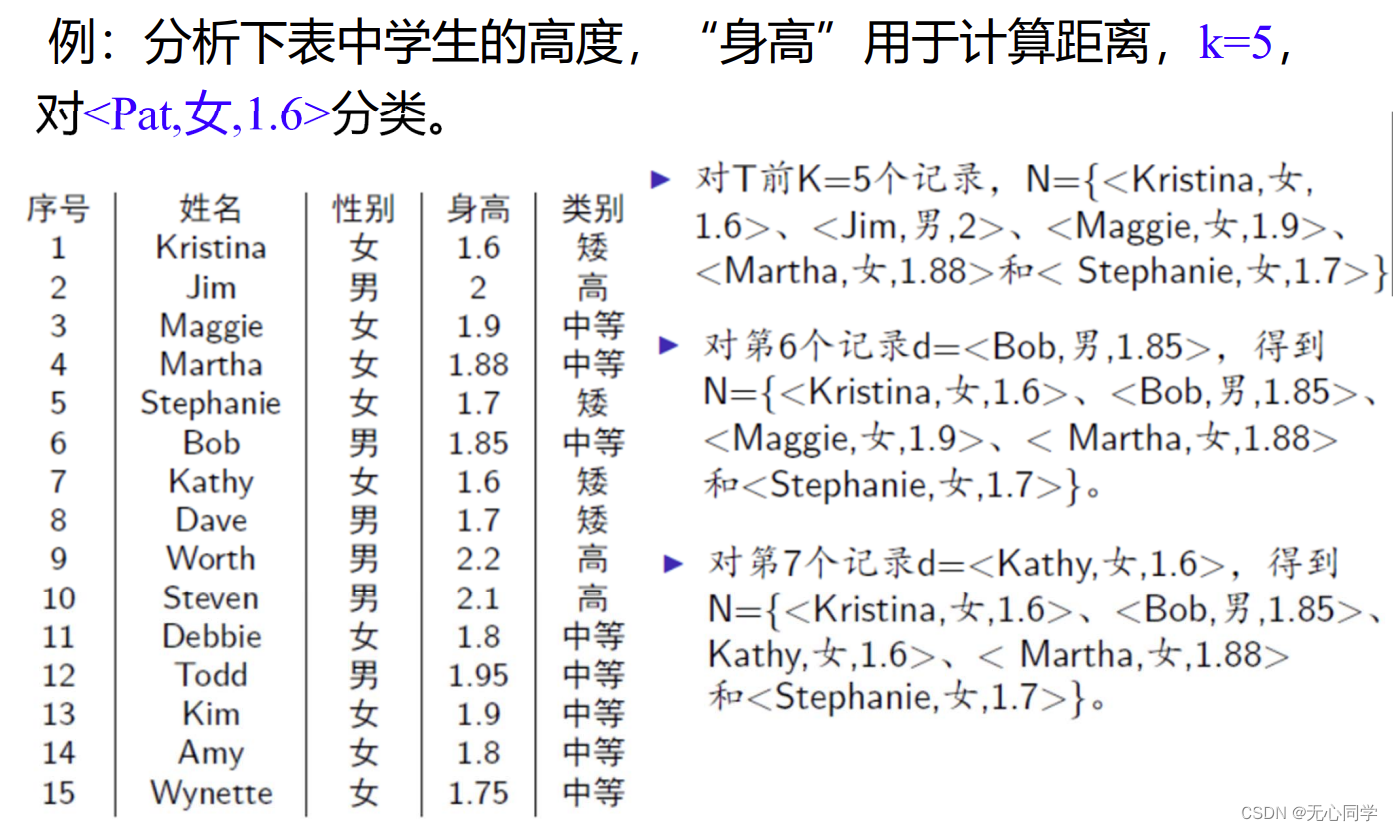
例子如下:
代码实现:
import numpy as np
def getMaxinN(NArray,y):
max_dist = 0
max_index = 0
print(NArray)
for i in range(len(NArray)):
print(np.abs(NArray[i][0] - y[0]))
if abs(NArray[i][0] - y[0]) > max_dist :
max_dist = NArray[i][0] - y[0]
max_index = i
print('max_dist:',max_dist)
print('max_index:',max_index)
print('================================')
return [max_dist,max_index]
if __name__ == '__main__':
data = [
[1.6, 1],
[2, 2],
[1.9, 3],
[1.88, 3],
[1.7, 1],
[1.85, 3],
[1.6, 1],
[1.7, 1],
[2.2, 2],
[2.1, 2],
[1.8, 3],
[1.95, 3],
[1.9, 3],
[1.8, 3],
[1.75, 3]
]
k = 5
# 存放最近的五个点
N = []
TextData = [1.6]
for i in range(len(data)):
if i<k:
N.append(data[i])
else :
max_arr = getMaxinN(N,TextData)
if np.abs(data[i][0]-TextData[0]) < max_arr[0]:
N.pop(max_arr[1])
N.append(data[i])
print(N)
flag_arr = []
for i in range(len(N)):
flag_arr.append(N[i][1])
frequencyNum = 0
result = 0
for i in range(max(flag_arr)):
flagNum = flag_arr.count(i+1)
if flagNum>frequencyNum:
frequencyNum = flagNum
result = i+1
print(f'即最终的结果为,1.6属于{result}类' )
4、KNN算法的sklearn实现
1、导入sklearn模块与numpy模块

2、加载数据,并划分训练以及测试集
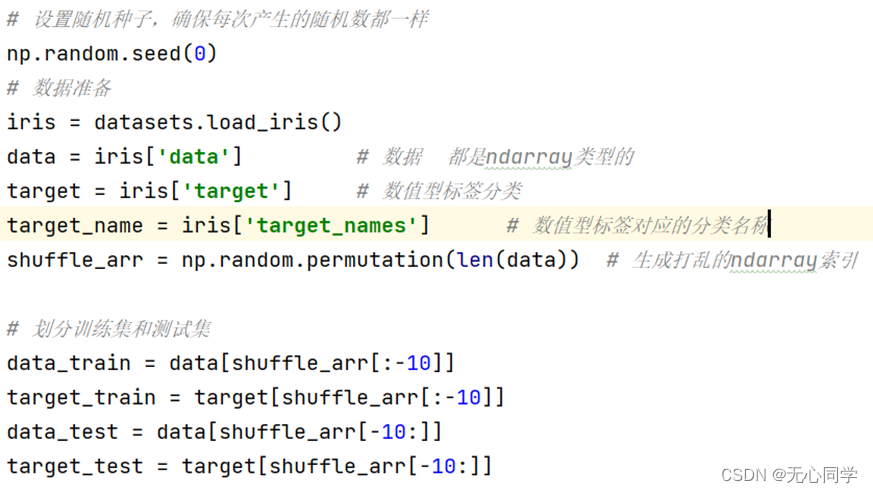
注意:这里的训练数据和测试数据的形状如果不是(n,1)的,要reshape(-1,1),标签则不需要,直接一行即可
3、实例化KNN分类器并用训练数据进行训练

4、使用模型对测试数据进行预测并计算准确率

运行结果如下:

完整代码:
# coding=utf8
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
def KNN(data,target):
# 设置随机种子,确保每次产生的随机数都一样
np.random.seed(0)
shuffle_arr = np.random.permutation(len(data)) # 生成打乱的ndarray索引
ratio = 0.8
num = int(ratio*len(data))
# 划分训练集和测试集
data_train = data[shuffle_arr[:num]] # 注意:训练数据的形状如果不是(n,1)的,要reshape(-1,1)
target_train = target[shuffle_arr[:num]]
data_test = data[shuffle_arr[num:]] # 注意:测试数据的形状如果不是(n,1)的,要reshape(-1,1)
target_test = target[shuffle_arr[num:]]
# 定义KNN分类器对象,k值为5
knn = KNeighborsClassifier(n_neighbors=5)
# 调用fit方法进行训练,接受训练集数据和标签
knn.fit(data_train, target_train)
# 调用预测方法,对数据进行预测
predict = knn.predict(data_test)
print('正确标签:', target_test)
print('预测标签:', predict)
# 计算准确率
score = knn.score(data_test, target_test, sample_weight=None)
print('准确率:', score)
# 计算出预测属于每个分类的概率
probility = knn.predict_proba(data_test)
print(probility)
print(knn.predict(np.array([[1.6]])))
if __name__ == '__main__':
# 数据准备
# iris = datasets.load_iris()
# data = iris['data'] # 数据 都是ndarray类型的
# target = iris['target'] # 数值型标签分类
# target_name = iris['target_names'] # 数值型标签对应的分类名称
example = np.array([
[1.6, 1],
[2, 2],
[1.9, 3],
[1.88, 3],
[1.7, 1],
[1.85, 3],
[1.6, 1],
[1.7, 1],
[2.2, 2],
[2.1, 2],
[1.8, 3],
[1.95, 3],
[1.9, 3],
[1.8, 3],
[1.75, 3]
])
data = example[:,0].reshape(-1,1)
target = example[:,1]
KNN(data,target)
5、KNN的特点总结
- 是一种基于实例的学习,需要一个邻近性度量来确定实例间的相似性或距离
- 不需要建立模型,但分类一个测试样例开销很大,需要计算域所有训练实例之间的距离
- 基于局部信息进行预测,对噪声非常敏感
- 最近邻分类器可以生成任意形状的决策边界,决策树和基于规则的分类器通常是直线决策边界
- 需要适当的邻近性度量和数据预处理,防止邻近性度量被某个属性左

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











