







一、解决方案架构
| 项目/产品 |
类型 |
介绍 |
| 云原生一站式机器学习/深度学习/大模型AI平台 |
AI训练开发平台 |
云原生一站式机器学习/深度学习/大模型AI平台,支持sso登录,多租户,大数据平台对接,notebook在线开发,拖拉拽任务流pipeline编排,多机多卡分布式训练,超参搜索,推理服务VGPU,边缘计算,serverless,标注平台,自动化标注,数据集管理,大模型微调,vllm大模型推理,llmops,私有知识库,AI模型应用商店,支持模型一键开发/推理/微调,支持国产cpu/gpu/npu芯片,支持RDMA,支持pytorch/tf/mxnet/deepspeed/paddle/colossalai/horovod/spark/ray/volcano分布式,私有化部署。 |
| 华为云HCCDA-AI认证 |
每位学生一次考试认证 |
面向AI初学者,培训与认证AI基础理论及基于华为云EI服务的AI应用开发能力。包括理论学习、实验学习和理论考试和实验考试,考试通过后发放HCCDA-AI认证。 根据实际学生人数安排。 |
| AI/数据挖掘实战课程 |
数据挖掘与深度学习体系化实战课程 |
AI课程: 数据挖掘与深度学习体系化实战课程,一共16章的内容,共96课时。 交付物 课程设计与实训材料:每个课程一套详细的课程大纲、教案、实训指导书和代码文档,真实项目案例和实战项目。每个课程包含2课时的导学视频。 交付形式 所有课程材料、技术指南和实验说明均以PDF、word、PPT等通用格式提供,部分提供在线访问权限,确保学生可以随时查阅最新资料。 |
| AI训练服务器 |
学校自备 |
考虑到现在大部分学校已经有自有的本地AI训练服务器或云服务器,所以本方案暂未给出AI训练服务器,如有需求可另行给出。 |
1.1 来自产业的实战项目
课程中的实战项目全部是基于产业的商业化项目,经过角色拆解、任务拆解、代码拆解、部署流程拆解等过程,讲其标准化为教师可以带领学生完成的实训内容,真正帮助学生接触产业前沿技术和工作内容,提升就业竞争力。
1.2 创新的AI训练实训平台
云原生一站式机器学习/深度学习/大模型AI平台可以大大提高带领学生完成AI实训和项目开发的效率,区别于市场上现有的实训平台,完整的平台包含:
- 1、机器的标准化
- 2、分布式存储(单机可忽略)、k8s集群、监控体系(prometheus/efk/zipkin)
- 3、基础能力(tf/pytorch/mxnet/valcano/ray等分布式,nni/katib超参搜索)
- 4、平台web部分(oa/权限/项目组、在线构建镜像、在线开发、pipeline拖拉拽、超参搜索、推理服务管理等)
二、云原生一站式机器学习/深度学习/大模型AI平台
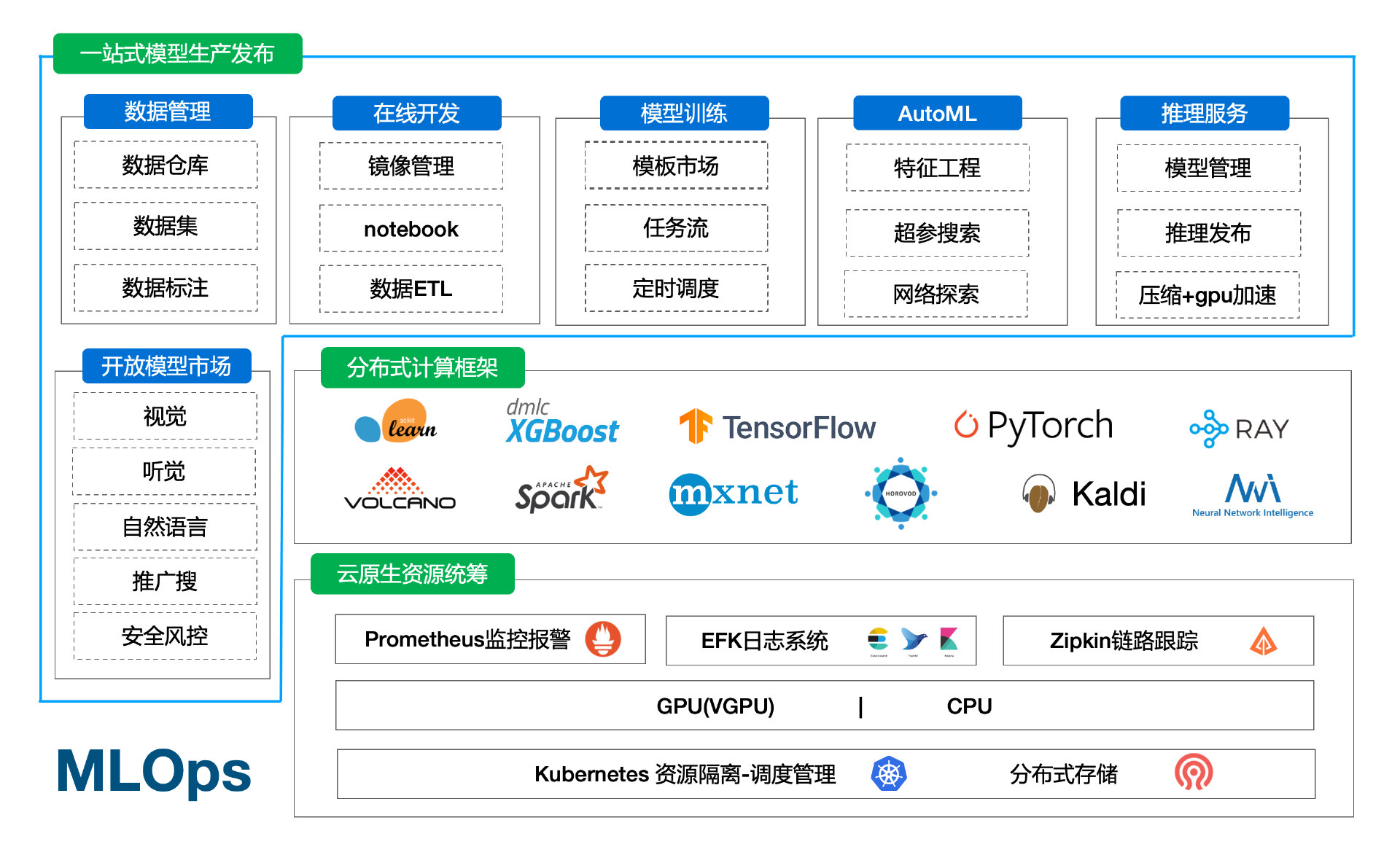
3.1 功能介绍
算力/存储/用户管理
算力:
- 云原生统筹平台cpu/gpu等算力
- 支持划分多资源组,支持多k8s集群,多地部署
- 支持T4/V100/A100/昇腾/dcu/VGPU等异构GPU/NPU环境
- 支持边缘集群模式,支持边缘节点上开发/训练/推理
- 支持鲲鹏芯片arm64架构,RDMA
存储:
- 自带分布式存储,支持多机分布式下文件处理
- 支持外部存储挂载,支持项目组挂载绑定
- 支持个人存储空间/组空间等多种形式
- 平台内存储空间不需要迁移
用户权限:
- 支持sso登录,对接公司账号体系
- 支持项目组划分,支持配置相应项目组用户的权限
- 管理平台用户的基本信息,组织架构,rbac权限体系
多集群管控
cube支持多集群调度,可同时管控多个训练或推理集群。在单个集群内,不仅能做到一个项目组内对在线开发、训练、推理的隔离,还可以做到一个k8s集群下多个项目组算力的隔离。另外在不同项目组下的算力间具有动态均衡的能力,能够在多项目间共享公共算力池和私有化算力池,做到成本最低化。
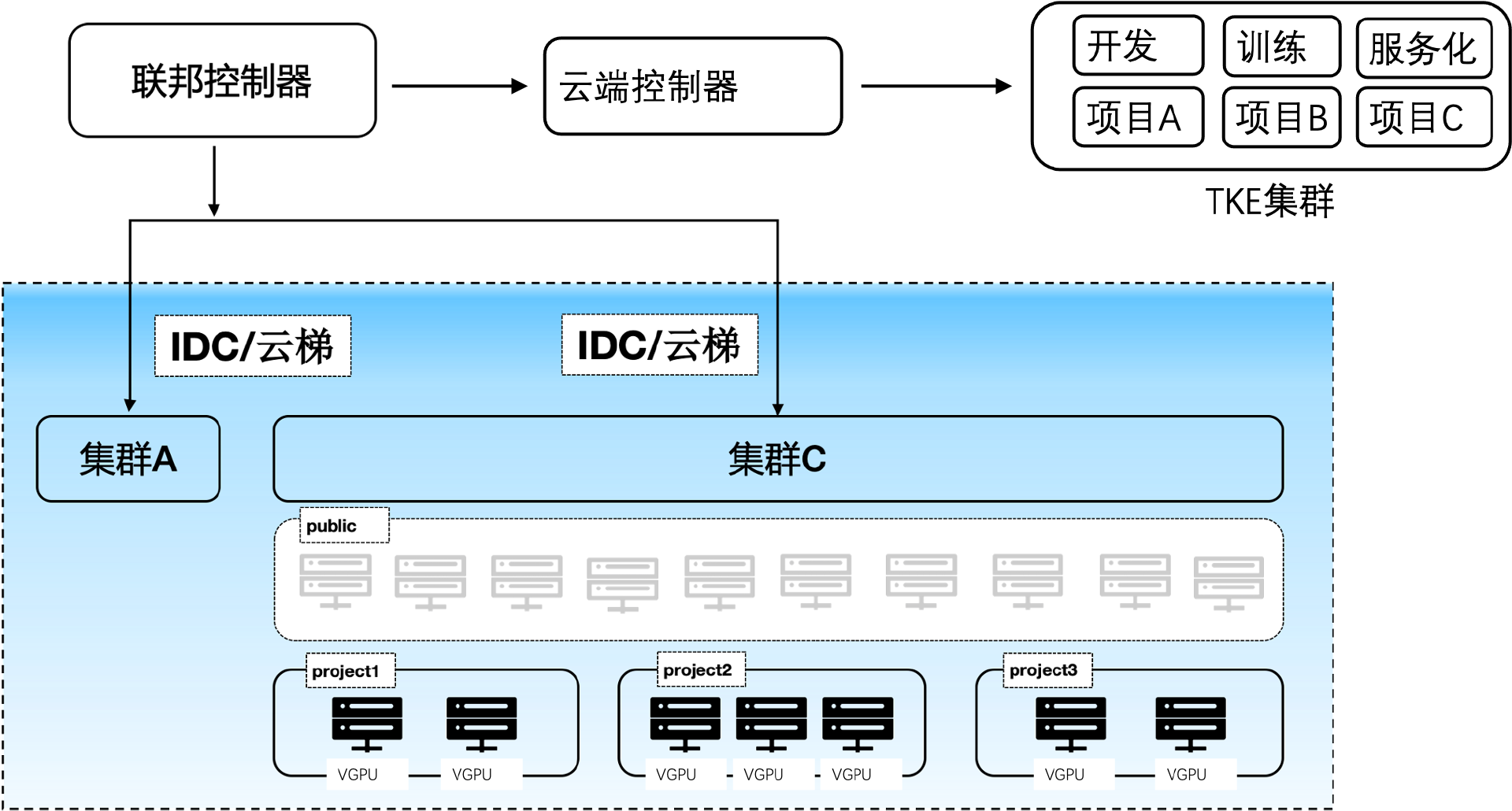
分布式存储
自动为用户挂载用户的个人目录,同一个用户在平台任何地方启动的容器,其用户个人子目录均为/mnt/$username。可以将pvc/hostpath/memory/configmap等挂载成容器目录。同时可以在项目组中配置项目组的默认挂载,进而实现一个项目组共享同一个目录等功能。

在线开发
- 系统多租户/多实例管理,在线交互开发调试,无需安装三方控件,只需浏览器就能完成开发。
- 支持vscode,jupyter,Matlab,Rstudio等多种在线IDE类型
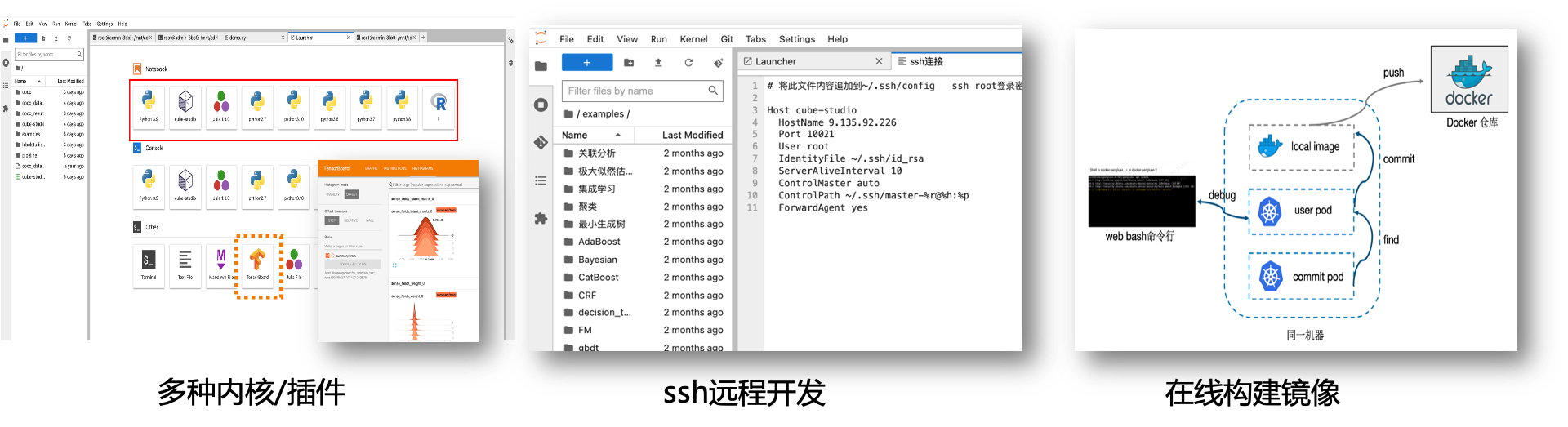
- Jupyter支持cube-studio sdk,Julia,R,python,pyspark多内核版本,
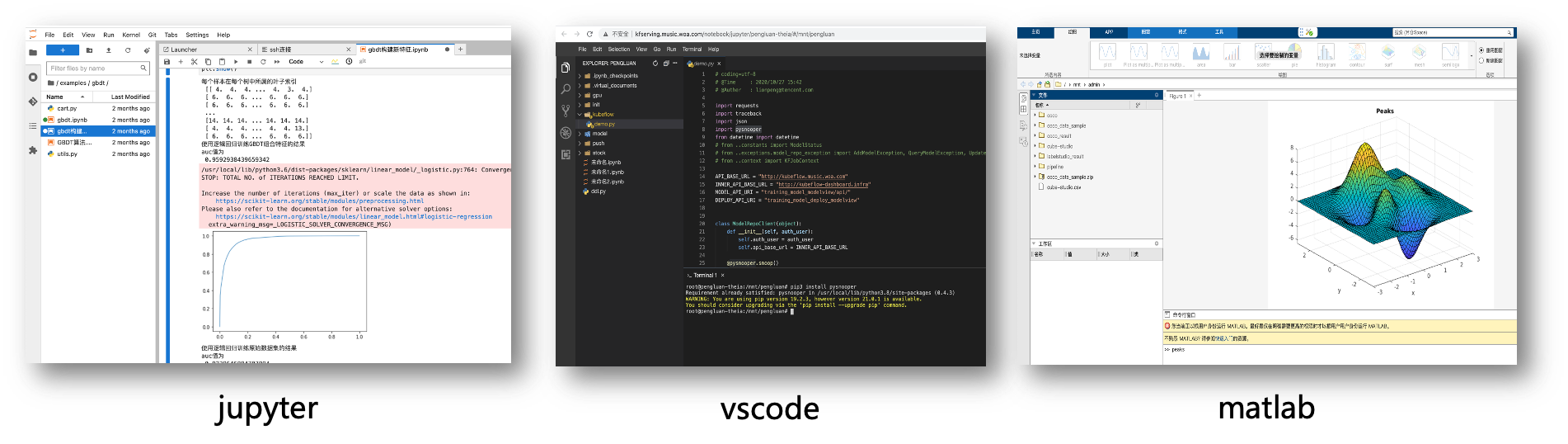
- 支持c++,java,conda等多种开发语言,以及tensorboard/git/gpu监控等多种插件
- 支持ssh remote与notebook互通,本地进行代码开发
- 在线镜像构建,通过Web Shell方式在浏览器中完成构建;并提供各种版本notebook,inference,gpu,python等基础镜像
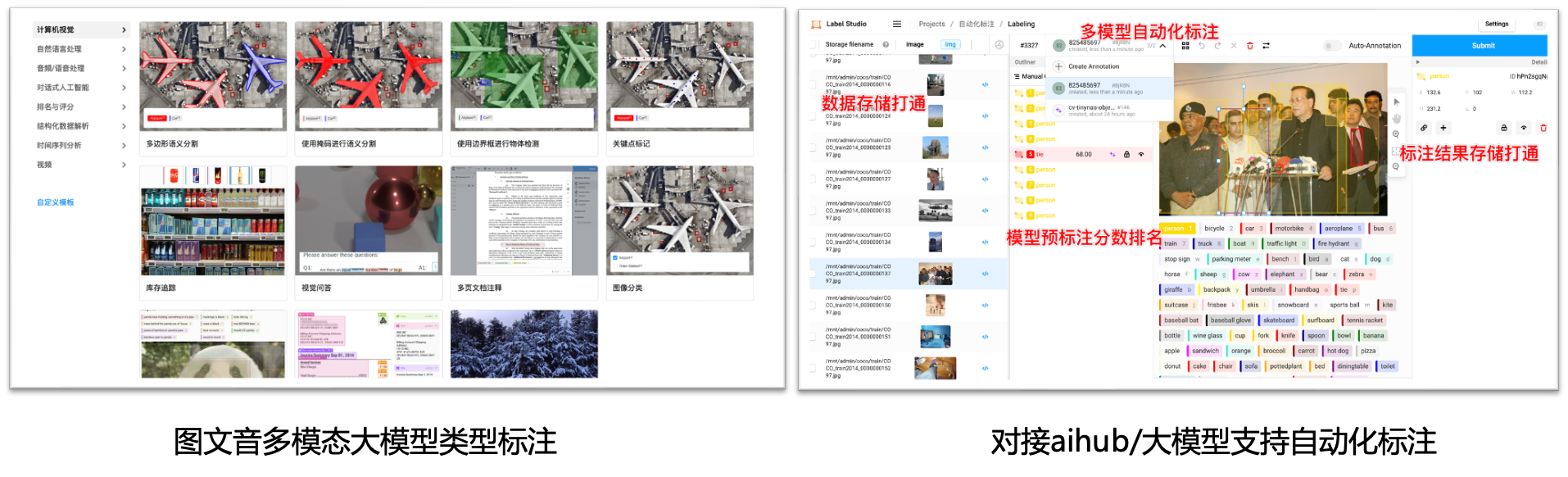
标注平台
- 支持图/文/音/多模态/大模型多种类型标注功能,用户管理,工作任务分发
- 对接aihub模型市场,支持自动化标注;对接数据集,支持标注数据导入;对接pipeline,支持标注结果自动化训练
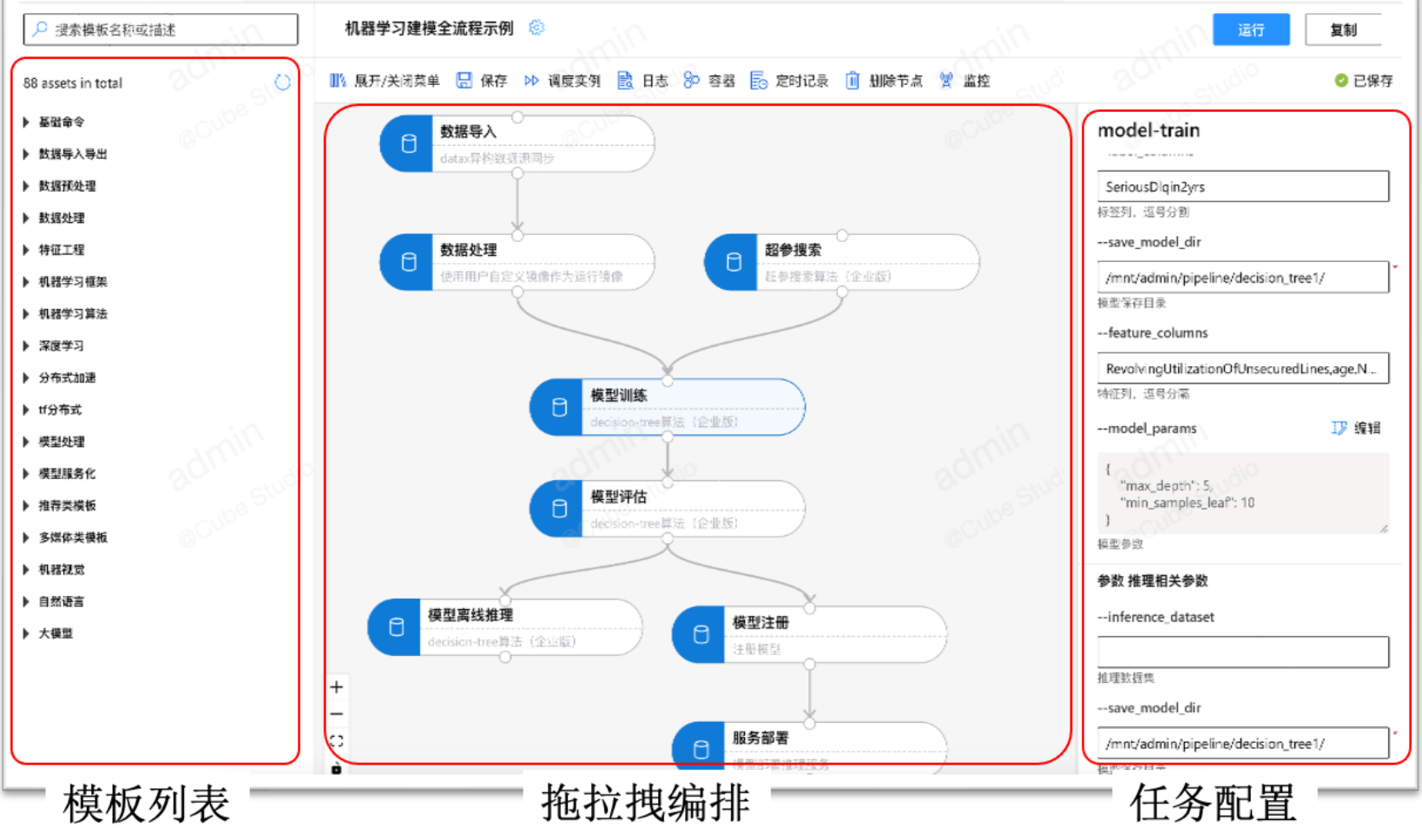
拖拉拽pipeline编排
1、Ml全流程
数据导入,数据预处理,超惨搜索,模型训练,模型评估,模型压缩,模型注册,服务上线,ml算法全流程
2、灵活开放
支持单任务调试、分布式任务日志聚合查看,pipeline调试跟踪,任务运行资源监控,以及定时调度功能(包含补录,忽略,重试,依赖,并发限制,过期淘汰等功能)
分布式框架
1、训练框架支持分布式(协议和策略)
2、代码识别分布式角色(有状态)
3、控制器部署分布式训练集群(operator)
4、配置分布式训练集群的部署(CRD)
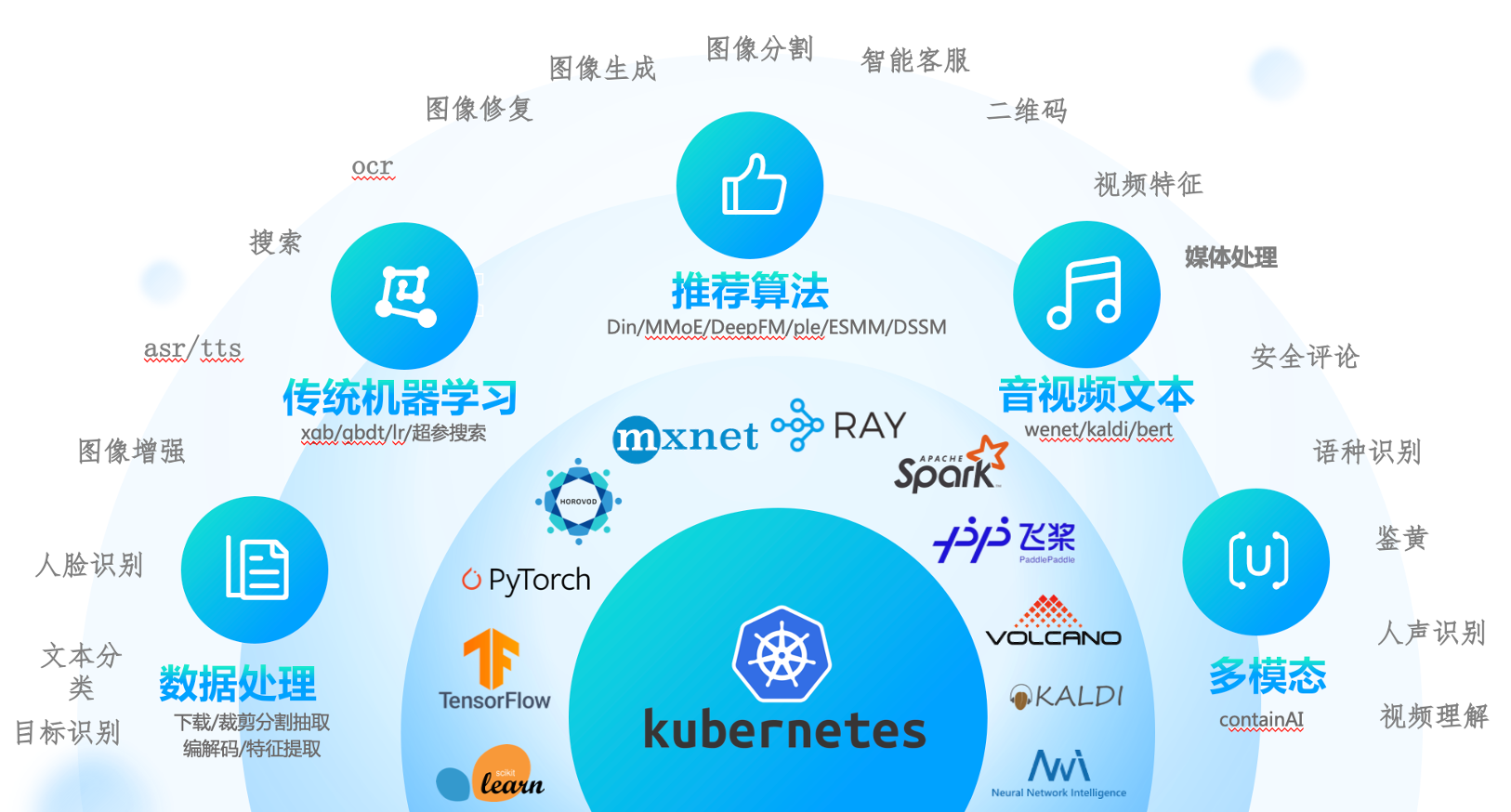
多层次多类型算子
以k8s为核心,
1、支持tf分布式训练、pytorch分布式训练、spark分布式数据处理、ray分布式超参搜索、mpi分布式训练、horovod分布式训练、nni分布式超参搜索、mxnet分布式训练、volcano分布式数据处理、kaldi分布式语音训练等,
2、 以及在此衍生出来的分布式的数据下载,hdfs拉取,cos上传下载,视频采帧,音频抽取,分布式的训练,例如推荐场景的din算法,ComiRec算法,MMoE算法,DeepFM算法,youtube dnn算法,ple模型,ESMM模型,双塔模型,音视频的wenet,containAI等算法的分布式训练。
功能模板化
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4001
4001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











