







课程概要:
1.最优间隔分类器
2.原始/对偶问题
3.svm的对偶问题
在上篇中,我们提到了函数间隔与几何间隔,这两个定义是 svm 的基本定义,因为svn比较复杂,这里先简要介绍一下svn的几个部分。首先是函数间隔与几何间隔,由它们
引出最优间隔分类器;为了多快好的解决最优间隔分类器问题,使用了拉格朗日对偶性性质,于是,先要理解原始优化问题与对偶问题及它们在什么条件(KKT 条件)下最优解等价,然后写出最优间隔分类器的对偶形式;通过对最优间隔分类器对偶问题求解,发现求解时目标函数中存在内积形式的计算,据此引入了核技法;引入核技法后就得到了完完全全的 svm求解问题,使用序列最小化算法(SMO)进行求解。这就是公开课中对svm的全部介绍,这里先写出来有个大致的了解。
一、最优间隔分类器
在开始之前,仍然要强调一下本篇所讲的内容仍然是假设数据集是线性可分的。 首先,回顾一下讲述函数间隔时对目标函数的表示方法所做的变化:
类别y可取值由{0,1}变为{-1,1},假设函数变为:

由公式2,我们得知,w,b可以唯一的确定一个超平面。
回顾一下上篇笔记中介绍的函数间隔的缺点,只要成倍的增大 w,b,就可以使函数间隔
变大。而几何间隔不会遇到这个问题,究其原因,是成倍增大 w,b后,决策面的位置不会发
生改变。本节会利用这个性质,对 w,b进行缩放,从而简化问题。
最优间隔分类器(optimal margin classifier),是指在对数据分类时,得到的决策面的一
个性质,即决策面距离数据点的几何间隔最大。可以使用置信度对它来进行解释,对于线性
可分数据,我们可以得到无数个决策面,直观上看,数据点距离决策面越远,决策面对数据
点的预测可信度就越高。最优间隔分类器即是寻找一个决策面,使之对数据点的预测的置信
度达到最高(即找到一个离数据点最远的决策面)。最优间隔分类器可以看做是支撑向量机的前身,是一种学习算法,
通过选择特定的w和b,使几何间隔最大化(离数据点最远即为使集合间隔最大)。
使用数学语言描述即为:
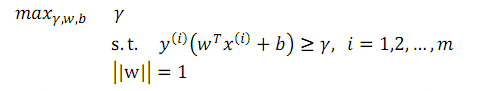
上式的含义是通过改变w,b,寻找一个最大的γ值,使得对于训练集中所有的点,点到决策面的几何距离都大于γ。
其中, ||w||=1保证了目标值是几何间隔。但是这个约束本身是一个非常糟糕的非凸性约束。要求解的参数w在一个球体表面,如果想得到一个凸优化问题,必须保证如梯度下降算法这种局部最优值搜索算法不会找到局部最优值,而非凸性约束不能满足这个条件,所以需要改变优化问题。
为了解决上述问题,提出下面的最优化问题:
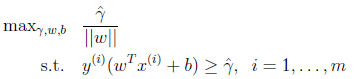
上述两式描述的是同一个问题,即寻找一个最大的值(几何间隔),使得训练集中所有的点到决策面的几何距离(函数间隔)都大于该值。上式通过将非凸性的约束条件转移到目标函数中,使问题变成凸性问题。
对于上式,还可以再做一次变换,使之更为简单。我们知道,等比例对 w,b 进行缩放,不会改变决策面的位置。假设已经得到 w,b,那么就能求出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3843
3843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









