








一、时间序列分析简介
1. 时间序列的定义
所谓时间序列就是按照一定的时间间隔排列的一组数据,其时间间隔可以是任意的时间单位,如小时、日、周、月等。这一组数据可以表示各种各样的含义,如经济领域中每年的产值、国民收入、商品在市场的销量、股票数据的变化情况等;社会领域中某一地区的人口数、医院患者人数、铁路客流量等,自然领域的太阳黑子数、月降水量、河流流量等,这些数据都形成了一个时间序列。人们希望通过对这些时间序列的分析,从中发现和揭示现象的发展变化规律,或从动态的角度描述某一现象和其它现象之间的内在数量关系及其变化规律,从而尽可能多地从中提取出所需要的准确信息,并将这些知识和信息用于预测,以掌握和控制未来行为。研究时间序列,通常也是希望根据历史数据预测未来数据。对于时间序列的预测,由于很难确定它与其它因变量的关系,或收集因变量的数据非常困难,这时我们就不能采用回归分析方法进行预测,而是使用时间序列分析来进行预测。
采用时间序列分析进行预测时需要用到一系列的模型,这种模型统称为时间序列模型。在使用这种时间序列模型时,总是假定某一种数据变化模式或某一种组合模式总是会重复发生的。因此需要首先识别出这种模式,然后采用外推的方式进行预测。采用时间序列模型时,显然其关键在于辨识数据的变化模式(样式);同时,决策者所采取的行动对这个时间序列的影响是很小的,因此这种方法主要用来对一些环境因素,或不受决策者控制的因素进行预测,如宏观经济情况、就业水平、某些产品的需求量等。时间序列分析法常常用于中短期预测,因为在相对短的时间内,数据变化的模式不会特别显著。
时间序列分析法的主要用途如下:①系统描述,根据对系统进行观测得到的时间序列数据,用曲线拟合方法对系统进行客观的描述;②系统分析,当观测值取自两个以上变量时,可用一个时间序列中的变化去说明另一个时间序列中的变化,从而深入了解给定时间序列产生的机理;③预测未来,一般用ARMA模型拟合时间序列,预测该时间序列未来值;④决策和控制,根据时间序列模型可调整输入变量使系统发展过程保持在目标值上,即预测到过程要偏离目标时便可进行必要的控制。
2. 时间序列的组成因素
时间序列的变化受许多因素的影响,有些起着长期的、决定性的作用,使其呈现出某种趋势和一定的规律性;有些则起着短期的、非决定性的作用,使其呈现出某种不规则性。在分析时间序列的变动规律时,事实上不可能对每个因素都一一划分开来,分别去做精确分析。但我们能将众多影响因素,按照对现象变化影响的类型,划分成若干时间序列的构成因素,然后对这几类构成要素分别进行分析,以揭示时间序列的变动规律性。影响时间序列的构成因素可归纳为以下四种:
1)趋势性(Trend),指现象随时间推移朝着一定方向呈现出持续渐进地上升、下降或平稳地变化或移动。这一变化通常是许多长期因素的结果。
2)周期性(Cyclic),指时间序列表现为循环于趋势线上方和下方的点序列并持续一段时间的有规则变动。这种因素具有周期性的变动,比如高速通货膨胀时期后紧接的温和通货膨胀时期将会使许多时间序列表现为交替地出现于一条总体递增趋势线的上下方。
3)季节性变化(SeasonalVariation),指现象受季节性影响,按一固定周期呈现出的周期波动变化。尽管我们通常将一个时间序列中的季节认为是以1年为期的,但是季节因素还可以被用于表示时间长度小于1年的有规则重复形态。比如,每日交通量数据表现出为期1天“季节性”变化,即高峰期到达高峰水平,而一天的其它时期车流量较小,从午夜到次日清晨最小。
4)不规则变化(IrregularMovement),指现象受偶然因素影响而呈现出的不规则波动。这种因素包括实际时间序列值与考虑了趋势性、周期性、季节性变动的估计之间的偏差,它用于解释时间序列的随机变动。不规则因素是由短期的未被预测到以及不重复发现的那些印象时间序列的因素引起的。
时间序列一般以上面几种变化的叠加或组合形式出现。
3. 时间序列分析方法
时间序列分析是一种广泛应用的数据分析方法,它研究的是代表某一现象的一串随时间变化而又相关联的数字系列(动态数据),从而描述和探索该现象随时间发展变化的规律性。时间序列分析利用的手段可以是直接简便的数据图法、指标法、模型法等。而模型法相对来说更具体也更深入,能更本质地了解数据的内在结构和复杂特征,以达到控制与预测的目的。总的来说,时间序列分析方法包括以下两类:
1)确定性时序分析:它是暂时过滤掉随机性因素(如季节因素、趋势变动)进行确定性分析的方法,其基本思想是用一个确定的时间函数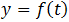
2)随机性时序分析:其基本思想是通过分析不同时刻变量的相关关系,揭示其相关结构,利用这种相关结构建立自回归、滑动平均、自回归滑动平均混合模型来对时间序列进行预测。
无论采用哪种方法,时间序列的一般分析流程基本固定,如图1所示。

图1 时间序列分析流程
二、ARIMA模型
1. 移动平均法
(1)一次移动平均法
一次移动平均法指收集一组观察值,计算这组观察值的均值,并利用这一均值作为下一期的预测值的预测方法。其模型为:
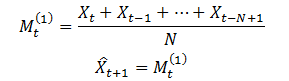
其中,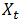
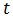
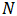
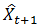
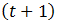
(2)二次移动平均法
二次移动平均法的线性模型为:
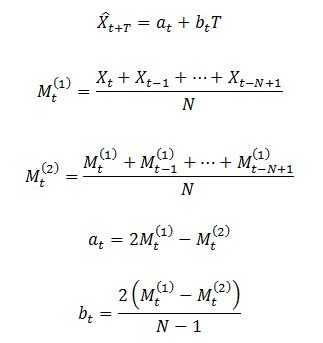
其中,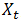
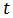
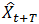
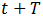
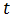
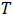
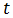
采用移动平均法进行预测,用来求平均数的时期数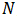
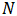
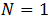
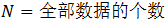
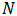
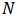
不存在一个确定时期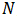
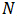
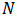
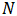
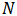
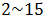
2. ARMA模型
ARMA模型的全称是自回归移动平均(Auto Regression Moving Average)模型,它是目前最常用的拟合平稳时间序列的模型。ARMA模型又可细分为AR模型、MA模型和ARMA模型三大类:
1)AR(p)(p阶自回归模型):
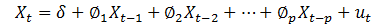
其中,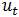
2)MA(q)(q阶移动平均模型):
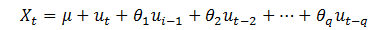
其中,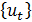
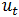
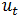
3)ARMA(p,q)(自回归移动平均过程):
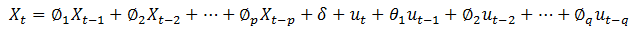
其中的参数含义同AR、MA模型,ARMA模型相当于AR模型和MA模型的叠加。
3. ARIMA模型
ARIMA模型的全称为差分自回归移动平均模型(Autoregression Integrated Moving Average),是由博克思(Box)和詹金斯(Jenkins)于70年代初提出的一著名时间序列预测方法,所以又称为Box-Jenkins模型、博克思-詹金斯法。ARIMA模型是ARMA模型的拓展,可以表示为ARIMA(p,d,q),其中AR是自回归,p为自回归项;MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。所谓ARIMA模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。
ARIMA模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似描述这个序列。这个模型一旦被识别后,就可以从时间序列的过去值及现在值来预测未来值。
由于ARIMA模型是ARMA模型的拓展,ARIMA包含ARMA模型的三种形式,即AR、MA、ARMA模型,另外一种是经过差分的ARMA模型形式,即:
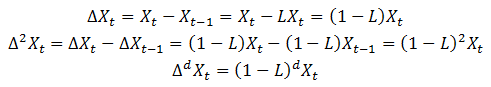
对于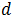
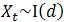
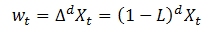
则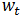
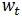
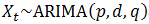
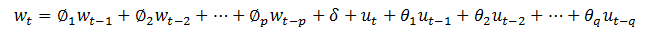
三、MADlib中ARIMA相关函数
1. 训练函数
(1)语法
ARIMA训练函数具有以下语法:
arima_train(input_table,
output_table,
timestamp_column,
timeseries_column,
grouping_columns,
include_mean,
non_seasonal_orders,
optimizer_params
)(2)参数
参数名称 | 数据类型 | 描述 |
input_table | TEXT | 包含时间序列数据的表的名称。 |
output_table | TEXT | 用于存储ARIMA模型的表的名称。会创建三个表,名称基于训练函数中output_table参数的值。三个输出表列分别如表2-表4所示。 |
timestamp_column | TEXT | 包含时间戳(或索引)数据的列的名称。可以一个序列索引(INTEGER)或日期/时间值(TIMESTAMP)。 |
timeseries_column | TEXT | 包含时间序列数据的列的名称。这些数据目前仅限于DOUBLE PRECISION类型。 |
grouping_columns(可选) | TEXT | 缺省值为NULL,当前未实现,任何非NULL值都会被忽略。逗号分隔的列名,与SQL中的GROUP BY子句类似,用于将输入数据集划分为离散组,每组训练一个ARIMA模型。当此值为空时,不使用分组,并生成单个结果模型。 |
include_mean(可选) | BOOLEAN | 缺省值为FALSE。如果此变量为True,则数据序列的平均值将添加到ARIMA模型中。 |
non_seasonal_orders(可选) | INTEGER[] | 缺省值为‘ARRAY[1,1,1]’。ARIMA模型中按[p, d, q]顺序的值。其中参数p、d和q是非负整数,分别表示模型的自回归、差分和移动平均部分的参数值。 |
optimizer_params(可选) | TEXT | ‘name = value’形式的优化器特定参数的逗号分隔值列表,参数无顺序。识别以下参数: l max_iter:缺省值为100。运行学习算法的最大迭代次数。 l tau:缺省值为0.001。计算梯度算法的初始步长。 l e1:缺省值为1e-15。算法特定的收敛阈值。 l e2: 缺省值为1e-15。算法特定的收敛阈值。e3: 缺省值为1e-15。算法特定的收敛阈值。 l hessian_delta:缺省值为1e-6。用于计算黑塞矩阵近似值的Delta参数。 |
表1 arima_train函数参数说明
主输出表包含ARIMA模型,具有以下列:
列名 | 数据类型 | 描述 |
mean | FLOAT8[] | 模型均值(仅当‘include_mean’为TRUE时)。 |
mean_std_error | FLOAT8[] | 均值的标准误差(仅当‘include_mean’为TRUE时)。 |
ar_params | FLOAT8[] | ARIMA模型的自回归参数。 |
ar_std_errors | FLOAT8[] | AR参数的标准误差。 |
ma_params | FLOAT8[] | ARIMA模型的移动平均参数。 |
ma_std_errors | FLOAT8[] | MA参数的标准误差。 |
表2 arima_train函数主输出表列说明
概要输出表包含ARIMA模型描述性统计信息,具有以下列:
列名 | 数据类型 | 描述 |
input_table | TEXT | 源数据表名。 |
timestamp_col | TEXT | 源表中包含数据的时间戳索引的列名。 |
timeseries_col | TEXT | 包含数据值的源表中的列名称。 |
non_seasonal_orders | INTEGER[] | 非季节性ARIMA模型的[p, d, q]参数数组。 |
include_mean | BOOLEAN | ARIMA模型中是否包含均值。 |
residual_variance | FLOAT8 | 残差的方差。 |
log_likelihood | FLOAT8 | 使用极大似然估计方法(Maximum Likelihood Estimate,MLE)时的对数似然值。 |
iter_num | INTEGER | 执行的迭代次数。 |
exec_time | FLOAT8 | 训练模型所用的总时间。 |
表3 arima_train函数概要输出表列说明
残差输出表包含‘input_table’中每个数据点的残差,具有以下列:
列名 | 数据类型 | 描述 |
timestamp_col | INTEGER | 与‘timestamp_col’参数相同(除了第一个d元素外,源表中的所有索引都包含在其中,d是来自‘non_seasonal_orders’的差异顺序值) |
residual | FLOAT8 | 每个数据表的残差值。 |
表4 arima_train函数残差输出表列说明
2. 预测函数
(1)语法
ARIMA预测函数具有以下语法:
arima_forecast(model_table,
output_table,
steps_ahead
)(2)参数
参数名称 | 数据类型 | 描述 |
model_table | TEXT | 包含在时间序列数据集上训练出来的ARIMA模型的表名。 |
output_table | TEXT | 用于存储预测值的表的名称。预测函数生成的输出表包含以下列: l group_by_cols:分组列的值(如果提供了分组参数)。 l step_ahead:预测的时间步长。 l forecast_value:对当前时间步长的预测 |
steps_ahead | INTEGER | 在时间序列末尾预测的步长数。 |
表5 arima_forecast函数参数说明
四、示例
本节我们使用MADlib的ARIMA模型函数演示一个经典的案例——预测裙子下摆直径。
1. 查看ARIMA模型训练函数的联机帮助。
selectmadlib.arima_train();
selectmadlib.arima_train('usage');
2. 创建源表并加载数据
我们以从1866年到1911年,每年裙子边缘的直径形成的时间序列数据为例。该数据集合可以从https://robjhyndman.com/tsdldata/roberts/skirts.dat地址得到。
-- 创建表
drop table if exists arima_skirts;
create table arima_skirts (time_id integer not null, value double precision not null );
-- 插入数据
insert into arima_skirts values
(1866,608), (1867,617), (1868,625), (1869,636), (1870,657), (1871,691), (1872,728), (1873,784),
(1874,816), (1875,876), (1876,949), (1877,997), (1878,1027), (1879,1047), (1880,1049), (1881,1018),
(1882,1021), (1883,1012), (1884,1018), (1885,991), (1886,962), (1887,921), (1888,871), (1889,829),
(1890,822), (1891,820), (1892,802), (1893,821), (1894,819), (1895,791), (1896,746), (1897,726),
(1898,661), (1899,620), (1900,588), (1901,568), (1902,542), (1903,551), (1904,541), (1905,557),
(1906,556), (1907,534), (1908,528), (1909,529), (1910,523), (1911,531);从图2可知,裙子边缘的直径形成的时间序列数据,从1866年到1911年在平均值上是不平稳的。 随着时间增加,数值变化很大。
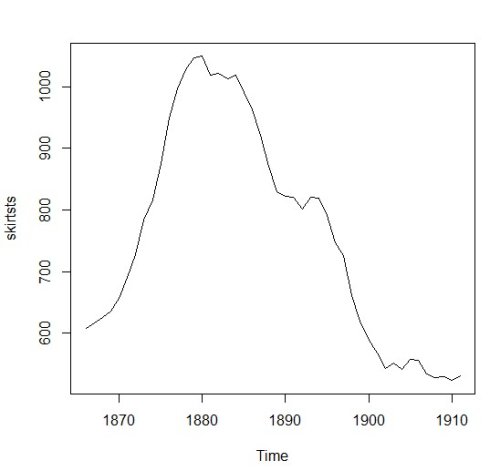
图2 裙子边缘直径时序数据图
3. 训练ARIMA模型
-- 训练ARIMA模型
-- ‘grouping_columns’=NULL, ‘include_mean’=TRUE, ‘non_seasonal_orders’=[1,2,5]
drop table if exists arima_skirts_output, arima_skirts_output_summary, arima_skirts_output_residual;
select madlib.arima_train( 'arima_skirts',
'arima_skirts_output',
'time_id',
'value',
null,
true,
array[1, 2, 5]
);说明:
ARIMA模型最主要的参数是ARIMA(p,d,q)中p、d和q值。然而MADLib的ARIMA模块并没有提供自动获取最佳模型参数的函数,如R语言中提供的auto.arima()函数,因此只能根据相关公式手工推算,这无疑让MADlib的ARIMA可用性大打折扣。函数调用里给出的(1,2,5) 是用R语言时间序列分析得出的最佳值。在R中通常的做法如下(参考“用ARIMA模型做需求预测”):
- 如果从一个非平稳的时间序列开始,首先就需要做时间序列差分直到得到一个平稳时间序列。如果必须对时间序列做d阶差分才能得到一个平稳序列,那么就使用ARIMA(p,d,q)模型,其中d是差分的阶数。
- 如果时间序列是平稳的,或者通过做n次差分转化为一个平稳时间序列,接下来就是要选择合适的 ARIMA模型,这意味着需要寻找ARIMA(p,d,q)中合适的p值和q值。为了得到这些值,通常需要检查平稳时间序列的自相关图和偏相关图。
4. 查看输出表
-- 查看ARIMA模型输出表
\x on
select * from arima_skirts_output;结果:
-[ RECORD 1 ]-+---------------------------------------------------------------------------------
ar_params | {-0.184652871018}
ar_std_errors | {0.156016122664}
ma_params | {-0.123007604302,0.0596510223511,-0.207811632539,0.0634092433453,-1.05886325787}
ma_std_errors | {0.0512000816653,0.0459036325616,0.0545197993978,0.0553368540779,0.059235144951}可以看到,即使‘include_mean’=TRUE,但输出模型中并没有包含mean和mean_std_error列。
-- 查看概要输出表
\x on
select * from arima_skirts_output_summary;结果:
-[ RECORD 1 ]-------+---------------
input_table | arima_skirts
timestamp_col | time_id
timeseries_col | value
non_seasonal_orders | {1,2,5}
include_mean | f
residual_variance | 218.520602147
log_likelihood | -180.944662041
iter_num | 72
exec_time (s) | 39.72类似的,include_mean列的值为f,也是错的。
-- 查看残差输出表
\x off
select * from arima_skirts_output_residual order by time_id;结果:
time_id | residual
---------+-------------------
1866 | 0
1867 | 0
1868 | 0
1869 | 2.815347128982
1870 | 10.9002677186686
1871 | 16.0194061939868
1872 | 7.3058458712154
1873 | 21.5837426526686
1874 | -12.6535232922353
1875 | 32.7687135142343
1876 | 43.9403322046431
1877 | -15.4114713044971
1878 | 3.33316657360179
1879 | -18.3393148804516
1880 | 6.40744982689161
1881 | 13.755076087944
1882 | 8.87510603075912
1883 | 0.573191100344981
1884 | -4.64139016554569
1885 | -23.0785601501065
1886 | 3.46557722913678
1887 | -2.16971047805747
1888 | -15.5842057919877
1889 | 1.81955757619692
1890 | 12.5229761005766
1891 | 13.4633061523254
1892 | -15.0987737140209
1893 | 17.3706905273975
1894 | -7.20003760226595
1895 | -22.5308287154289
1896 | -5.31991471812138
1897 | 3.96524755955299
1898 | -25.4110176681293
1899 | 5.02760869308011
1900 | -7.1298141723989
1901 | 1.31975183663332
1902 | 3.6582185908861
1903 | 5.55609879266714
1904 | -6.02201756591708
1905 | 14.5464521731418
1906 | -7.73038779906717
1907 | -23.6879061013042
1908 | 18.9575450832238
1909 | 4.79403878358361
1910 | 4.72169571860917
1911 | 10.2584720523074
(46 rows)
5. 预测后5年裙子的边缘直径
drop table if exists arima_skirts_forecast_output;
select madlib.arima_forecast( 'arima_skirts_output',
'arima_skirts_forecast_output',
5
);
select * from arima_skirts_forecast_output order by steps_ahead;结果:
steps_ahead | forecast_value
-------------+----------------
1 | 560.722723702
2 | 566.295527579
3 | 569.419021291
4 | 568.645638996
5 | 557.729506905
(5 rows)













 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









