







1、KNN
简介:knn算法是监督学习中分类方法的一种。它又被叫k近邻算法,是一个概念极其简单而分类效果又很优秀的分类算法。
核心思想:在训练集中选出离输入的数据最近的k个数据,根据这k个数据的类别判断输入数据的类别,k个数据的类别判断方法可以是k个中出现次数最多的类别,也可以根据距离计算权重,再选出权重最大的类别,等等。
准确率的制约:k值的大小和判断类别的方法
2、数据源
分别给出两类由正太分布随机的200个点,并将两类一前一后合并,最后以矩阵的形式存放入dataset;
x1 = numpy.round(numpy.random.normal(115, 10, 100),2)
y1 = numpy.round(numpy.random.normal(95, 6,100),2)
x2 = numpy.round(numpy.random.normal(70, 10, 100),2)
y2 = numpy.round(numpy.random.normal(99, 6, 100),2)
a=[]
b=[]
for i in range(100):
a.append([x1[i],y1[i]])
for i in range(100):
b.append([x2[i],y2[i]])
c=a+b
dataset=array(c)
给出两类正太分布数据分别分成'*'和'o'两类,以列表形式存放入labels;
labels=[]
for i in range(100):
labels.append('*')
for i in range(100):
labels.append('o')x=[82,94]
x=array(x)
y=[90,100]
y=array(y)
*以完整代码展示算法实现
# -*- coding:utf-8 -*-
import numpy
from numpy import *
import random
import pylab as pl
import operator
pl.figure(1)
pl.figure(2)
#计算样本的距离,预测类别
def classify(testdata,traindata,labels,k):
#testdate:待分类数集;traindate:分好类的数集;
#tile(a,(b,c)):将a的内容在行上复制b遍,列上复制c遍
trasize=traindata.shape[0] #得到其维数
tradis1=tile(testdata,(trasize,1))-traindata
tradis2=tradis1**2
tradis3=tradis2.sum(axis=1)
tradis=tradis3**0.5 #计算样本与训练数据的距离
sortdis=tradis.argsort()#排序
classcount={}#建立空字典
for i in range(k):#通过循环寻找k个近邻
votelabel=labels[sortdis[i]]
classcount[votelabel]=classcount.get(votelabel,0)+1
sortedclasscount=sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
return sortedclasscount[0][0]#返回占最大比例的类别
x1 = numpy.round(numpy.random.normal(115, 10, 100),2)
y1 = numpy.round(numpy.random.normal(95, 6,100),2)
x2 = numpy.round(numpy.random.normal(70, 10, 100),2)
y2 = numpy.round(numpy.random.normal(99, 6, 100),2)
a=[]
b=[]
for i in range(100):
a.append([x1[i],y1[i]])
for i in range(100):
b.append([x2[i],y2[i]])
c=a+b
dataset=array(c) #将列表转化为矩阵
labels=[]
for i in range(100):
labels.append('*')
for i in range(100):
labels.append('o')
x=[82,94]
x=array(x)
y=[90,100]
y=array(y)
k=10
labelX=classify(x,dataset,labels,k)
labelY=classify(y,dataset,labels,k)
pl.figure(1)
pl.plot(x1,y1,'*')
pl.plot(x2,y2,'o')
pl.plot(82,94,'.')
pl.plot(96,100,'.')
pl.xlabel('X')
pl.ylabel('Y')
pl.figure(2)
pl.plot(x1,y1,'*')
pl.plot(x2,y2,'o')
pl.plot(82,94,labelX)
pl.plot(96,100,labelY)
pl.show()
未分类钱前的图像如下,
一类正态分布的点用星表示,另一类用圆表示,待分类的两点用点表示;
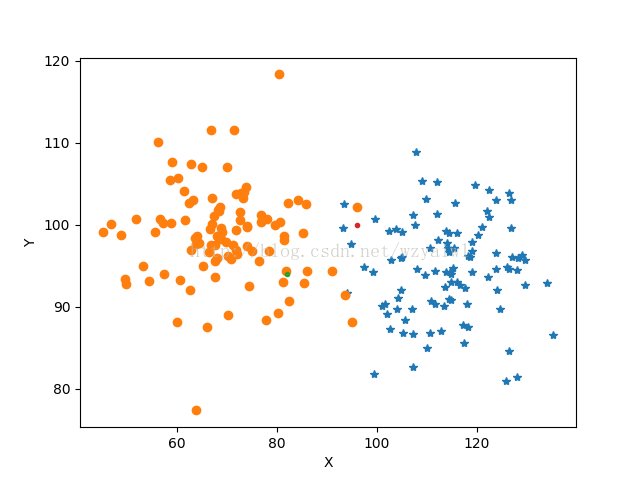
分类后的图像如下,两点归类看其形状改变;
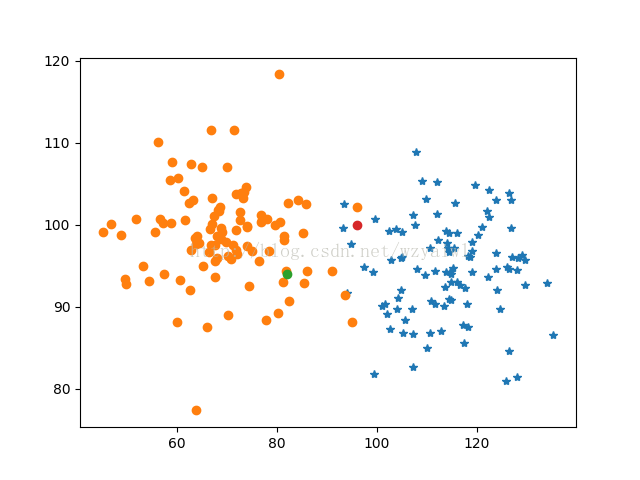
5、写代码后的心得
- 引入的数据一定要看清其类别,在这里就要注意列表与矩阵的转化;
- append([x1[i],y1[i]])括号里又加中括号是因为append一次只能添入一个元素
- 将列表转化为矩阵用array
- 矩阵的平方是将矩阵内每个元素平方,与线性代数不同














 8390
8390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









