




 本文详细介绍了机器学习中用于评估分类模型性能的度量标准,包括混淆矩阵、精确率、召回率、准确率和F值。重点讲解了ROC曲线及其相关概念FPR和TPR,强调了在正负样本不平衡的情况下,仅依赖准确率可能带来的误导,而ROC曲线和AUC能提供更全面的评估。
本文详细介绍了机器学习中用于评估分类模型性能的度量标准,包括混淆矩阵、精确率、召回率、准确率和F值。重点讲解了ROC曲线及其相关概念FPR和TPR,强调了在正负样本不平衡的情况下,仅依赖准确率可能带来的误导,而ROC曲线和AUC能提供更全面的评估。
这一部分总结分类问题常用的性能度量手段,这里涉及到的概念有混淆矩阵,正确率,召回率,ROC,AUC等等.这些概念都是比较简单,同时也是非常非常常用的.需要仔细理解.
一.混淆矩阵(Confusion Matrix)
一开始需要说一下的就是混淆矩阵啦,混淆矩阵是一个很简单很基础的东西.可以作为分类问题一个比较基本的可视化工具.
通常来说混淆矩阵的行代表的是实际类别,列代表的是预测的类别.要是这样说有一些抽象的话,通过一个例子可以直观秒懂.这里使用维基百科上面的例子:https://en.wikipedia.org/wiki/Confusion_matrix
假设一共有27只动物,其中有8只猫,6条狗,13只兔子.最终的分类的结果如下图:
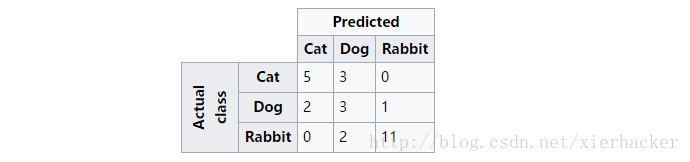
上面这幅图可以这么看,比如第一行,可以看做是猫中有5只预测为猫(即预测正确),有3只预测为狗,0只预测为兔子. 同样第二行可以理解为狗中有2只预测为猫,有3只预测为狗,1只预测为兔子…..依次类推.
可以看出来,对角线上面的是每一类别被正确预测的数量(概率),意味着,一个好的分类器得到的结果的混淆矩阵应该是尽可能的在对角线上面”成堆的数字”,而在非对角线区域越接近0越好,意味着预测正确的要多,预测错误的要少.
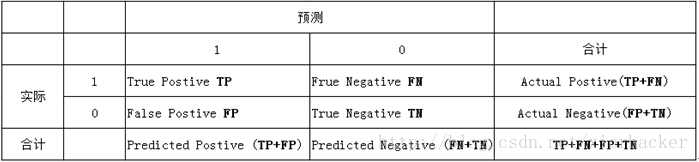
然后就是大多数人都更加熟悉的另外一种混淆矩阵的形式了.(维基百科上面叫做混淆表格(Table of confusion)),就是把一个二类分类问题下面的方式来表示:
真正例(True Positive;TP):将一个正例正确判断成一个正例
伪正例(False Positive;FP):将一个反例错误判断为一个正例
真反例(True Negtive;TN):将一个反例正确判断为一个反例
伪反例(False Negtive;FN):将一个正例错误判断为一个反例
上面这个概念很多初学者应该会反应比较难记下来,简写啊什么的.其实你可以把前面的那个字母看做是否判断正确,后面那个字母看做预测的类型.
比如,TN,看到T,说明预测是正确的,后面那个是预测的类型,是N(反例),也就是说,是正确的把反例预测为了反例.同样可以用这个方式来判断上面其他三个概念.你可以一个一个试一下,加深理解.
下面给出一个图片来直观的加深理解,实际上,很多地方也就是这么用的.结合上面讲过的,这幅图应该是很容易懂了对吧.
那么到这里,混淆矩阵的基本概念就结束了,接下来是更加基于混淆矩阵的更多的概念.
二.常见概念
这里会根据上面所示的混淆矩阵的概念,来理一下常见的性能度量概念.
Ⅰ.精确率(Precision)
精确率(有人也叫做正确率)的定义:
预测为正例的样本中,真正为正例的比率.
其实这句话并不难理解,预测为正例的样本有哪些呢?没错,有TP和FP,看后面的那个字母就行了,那么预测为正例的样本的总数为TP+FP,其中TP是真正为正例的样本.
那么有:
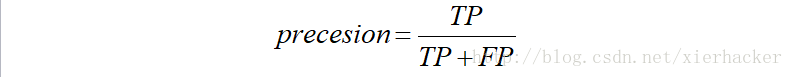
也就是说,精确率本质来说是对于预测结果来说的.表示对于结果来说,我对了多少.
Ⅱ.召回率(Recall)
找回率的定义:
预测为正例的真实正例(TP)占所有真实正例的比例.
这句话也不难理解.预测为正例的真实正例,其实就是TP,那么所有的真实正例由什么构成呢?首先肯定有TP,同样还有FN(FN表示错误预测为了反例,即本身为正例.)
那么有:
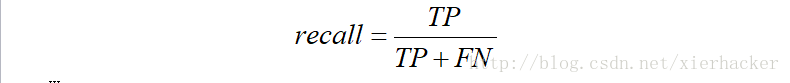
也就是说,召回率是对于原来的样本而言的.表示在原来的样本中,我预测中了其中的多少.
Ⅲ.准确率(Accuracy)
准确率的定义为:
在所有样本里面预测对了的比率.
这句话就更好理解了.所以样本,那就是TP+FN+FP+TN,预测对的就两个,一个是TP,一个是TN.
那么有:
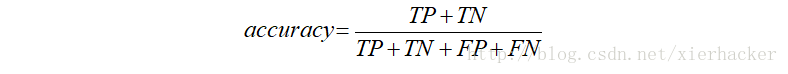
那么这里要插一句嘴,就上面两个概念总结一下了.
首先来看准确率,注意是准确率,别弄成其他的了.准确率这个度量方法基本上是我们经常使用的方式,也是最直观的方式.预测对的样本占所有样本的比率,比如说,在100张图片中,人脸识别对了99张,那么得到99%的正确率,还有比这个更加直观简单的度量方式吗?那为什么还要其他的那么多的性能度量方式呢?
因为,这个指标也是有缺陷的.他对与正负样本不平衡的问题无法给出客观的预测.
比如,在广告的点击预估里面,你知道,你生活中见到了广告一般是不点击的.除非偶尔手滑或者真的对那样产品超级感兴趣才点击了一下下.也就是说,在点击的案例里面,负样本(设不点击是负样本)占了巨大多数,也许几百次几千次里面才会有一次正样本(点击).
假如你现在还是仅仅同准确率来度量的话,那你的分类器直接把所有样本都预测为负就行了.因为1000个样本,其中有两次点击.剩下998都是不点击.你会发现,你的准确率是98%,但是这样有意义吗?没有意义.所以仅仅靠准确率有时候是行不通的.
Ⅳ.F值
表示精确率和召回率的调和均值,即:

三.ROC曲线
ROC曲线的全称是Receiver Operating Characteristic curve,接受者操作特征曲线.要说ROC曲线的话,这里又要引进两个概念,说是概念,其实就是前面提到过的方法改变一下形成的指标罢了,没有什么难理解的.
Ⅰ.FPR
首先是伪正类率(False Positive Rate,FPR),定义为:
预测为正但实际为负的样本占所有负样本的比例.
这句话有点小绕口,首先,预测为正但是实际为负的样本,可以写出来是FP,所有负样本,可以写出来是FP和TN,那么有:
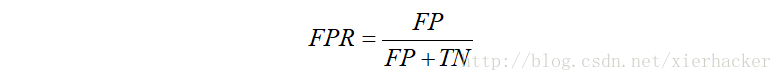
Ⅱ.TPR
真正类率(Ture Positive Rate,TPR),定义为:
预测为正且实际为正的样本占所有正样本的比例.
你会发现,这个不就是召回率吗?
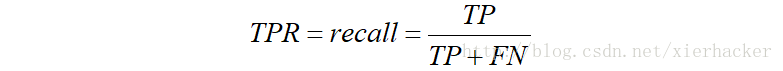
Ⅲ.ROC
ROC就是对于一个分类器,给定一些阈值,每一个阈值都可以得到一组(FPR,TPR),以FPR作为横坐标,TPR作为纵坐标,就能够画出ROC图啦.比如你经常会看见的如下面形式的
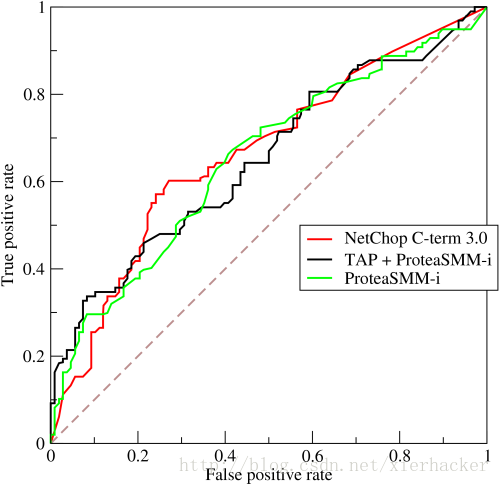
更多的讨论,可以到下面这些地址:
http://zhwhong.ml/2017/04/14/ROC-AUC-Precision-Recall-analysis/
https://www.52ml.net/19370.html
http://www.cnblogs.com/dlml/p/4403482.html
http://www.tuicool.com/articles/ZRzIRbB
http://blog.csdn.net/garfielder007/article/details/51050195
http://blog.csdn.net/godenlove007/article/details/8970419
https://cos.name/tag/%E6%B7%B7%E6%B7%86%E7%9F%A9%E9%98%B5/
http://www.dataguru.cn/thread-461647-1-1.html
https://www.zhihu.com/question/36883196?from=profile_question_card
http://blog.csdn.net/vesper305/article/details/44927047
http://www.jianshu.com/users/3337ad178f65/timeline
http://www.jianshu.com/u/38cd2a8c425e
http://www.jianshu.com/p/c61ae11cc5f6
http://alexkong.net/2013/06/introduction-to-auc-and-roc/
http://www.cnblogs.com/dlml/p/4403482.html
https://www.zhihu.com/question/30643044
http://zhwhong.ml/2017/04/14/ROC-AUC-Precision-Recall-analysis/

















 4456
4456


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








