




 YOLO是2016年提出的一种实时目标检测方法,它摒弃了区域提议步骤,将目标检测直接转化为回归问题,提高了检测速度。通过网络结构优化,YOLO能以高帧率运行,但在检测小物体时精度较低。尽管存在局限,YOLO为后续的SSD等方法奠定了基础,推动了目标检测领域的发展。
YOLO是2016年提出的一种实时目标检测方法,它摒弃了区域提议步骤,将目标检测直接转化为回归问题,提高了检测速度。通过网络结构优化,YOLO能以高帧率运行,但在检测小物体时精度较低。尽管存在局限,YOLO为后续的SSD等方法奠定了基础,推动了目标检测领域的发展。
You Only Look Once:Unified, Real-Time Object Detection
简介
YOLO是2016年CVPR的paper,这是RBG继RCNN,fast-RCNN,faster-RCNN以后,又一力作。针对目标检测中,无法实现实时性检测的问题,独辟蹊径,开创了目标检测的新思路。在RCNN中,作者将目标检测的问题转化到分类上来,提出了region proposal+cnn feature+ svm的思路。在以后的sppnet,fast-rcnn,faster-rcnn都沿袭了这个思路,对每个过程进行优化,检测精度也不断提升,但是这样做有一个很大的缺陷就是时间效率不高,无法达到实时性的检测,最快的faster-rcnn ZF网络也就能达到18fps的速度。所以,作者又提出了一种新的思路,直接将目标检测转化到回归上,直接用一张图片得到bounding box和所属类别。
YOLO 具体过程
YOLO具体过程如下图所示:
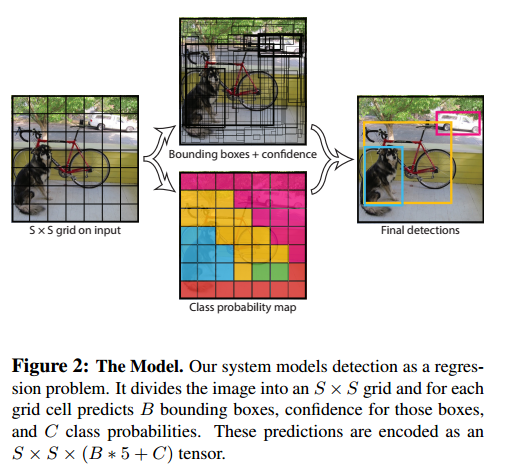
YOLO直接从一张图片中提取特征,来预测每一个Bounding box,最小化和ground turth的误差。由于YOLO是一个端到端的训练,并且中间没有region proposal生成,所以在速度上有了很大的提升。
首先 将图片划分为 S×S 的网格,每一个网格中预测B个Bounding box 和confidence score。如果每一个网格中有物体存在,那么confidence score 为 Pr(object)∗IOUtruthpred ,如果不存在物体,则为0。物体的位置用 (x,y,w,h) 表示, (x,y) 表示物体的中心位置。每个网格还会预测C类的可能性 Pr(Classi|Object) 。
Pr(Classi|Object)∗Pr(Object)∗IOUtruth
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









