






目录
引言
在机器学习领域中,聚类算法是一种非常重要的无监督学习方法。K-Means聚类算法因其简单、高效的特点,成为了最常用的聚类算法之一。本文将详细介绍K-Means聚类算法的原理、步骤、优缺点以及实际应用,并通过Python代码示例帮助读者更好地理解和掌握这一算法。
1. 什么是K-Means聚类?
K-Means聚类是一种无监督学习算法,用于将数据集划分为K个簇(cluster)。每个簇中的数据点彼此相似,而不同簇之间的数据点则尽可能不同。K-Means聚类算法的目标是最小化簇内数据点与簇中心(centroid)之间的距离平方和。
2. K-Means聚类算法的原理
K-Means算法的核心思想是通过迭代优化来找到K个簇的中心点,使得每个数据点到其所属簇中心的距离最小。具体来说,K-Means算法通过以下步骤实现聚类:
-
初始化:随机选择K个数据点作为初始簇中心。
-
分配:将每个数据点分配到距离最近的簇中心所在的簇。
-
更新:重新计算每个簇的中心点(即簇内所有数据点的均值)。
-
迭代:重复步骤2和步骤3,直到簇中心不再发生变化或达到预定的迭代次数。
3. K-Means算法的步骤
3.1 初始化
首先,随机选择K个数据点作为初始簇中心。K的值需要预先设定,通常通过经验或使用肘部法(Elbow Method)来确定。
3.2 分配
对于数据集中的每个数据点,计算其与K个簇中心的距离,并将其分配到距离最近的簇中心所在的簇。常用的距离度量方法包括欧氏距离、曼哈顿距离等。
3.3 更新
对于每个簇,重新计算其中心点。新的中心点是簇内所有数据点的均值。
3.4 迭代
重复分配和更新步骤,直到簇中心不再发生变化或达到预定的迭代次数。
4. K-Means算法的优缺点
4.1 优点
-
简单易懂:K-Means算法的原理和实现都非常简单,易于理解和实现。
-
高效:K-Means算法的时间复杂度为O(nkt),其中n是数据点的数量,k是簇的数量,t是迭代次数。对于大规模数据集,K-Means算法通常能够快速收敛。
-
可扩展性强:K-Means算法可以很容易地扩展到大规模数据集和高维数据。
4.2 缺点
-
需要预先设定K值:K-Means算法需要预先设定簇的数量K,而在实际应用中,K值往往难以确定。
-
对初始值敏感:K-Means算法的结果受初始簇中心的影响较大,不同的初始值可能导致不同的聚类结果。
-
对噪声和异常值敏感:K-Means算法对噪声和异常值较为敏感,可能导致聚类结果不准确。
-
只能处理凸形簇:K-Means算法假设簇是凸形的,对于非凸形簇或形状复杂的簇,K-Means算法的效果可能不理想。
5. K-Means算法的应用场景
K-Means聚类算法在许多领域都有广泛的应用,包括但不限于:
-
图像分割:将图像中的像素点聚类成不同的区域,用于图像分析和处理。
-
市场细分:将客户或用户划分为不同的群体,用于市场营销和个性化推荐。
-
文档聚类:将文档或文本数据聚类成不同的主题,用于文本挖掘和信息检索。
-
生物信息学:将基因或蛋白质数据聚类成不同的功能组,用于生物信息学分析。
6. Python实现K-Means聚类
# 导入必要的库
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import metrics
import matplotlib.pyplot as plt
# pandas:用于数据处理和分析,尤其是读取和操作表格数据。
# KMeans:来自scikit-learn,用于实现K-Means聚类算法。
# metrics:提供评估聚类效果的指标,如轮廓系数。
# matplotlib.pyplot:用于绘制图表,如折线图。
# 读取数据
beer = pd.read_table("data.txt", sep=' ', encoding="utf8", engine="python")
# pd.read_table:从文本文件data.txt中读取数据。
# sep=' ':指定数据的分隔符为空格。
# encoding="utf8":指定文件的编码格式为UTF-8。
# engine="python":使用Python引擎读取文件。
# 数据被加载到beer这个DataFrame中。
#选择特征
x = beer[["calories", "sodium", "alcohol", "cost"]]
# 从beer数据集中选择用于聚类的特征列:calories(卡路里)、sodium(钠含量)、alcohol(酒精含量)和cost(成本)。
# 这些特征将作为K-Means算法的输入。
#计算轮廓系数并选择最佳K值
scores = []
for k in range(2, 10):
labels = KMeans(n_clusters=k).fit(x).labels_
score = metrics.silhouette_score(x, labels)
scores.append(score)
# scores:用于存储不同K值对应的轮廓系数。
# for k in range(2, 10):遍历K值从2到9。
# KMeans(n_clusters=k):初始化K-Means模型,设置簇的数量为k。
# .fit(x):对数据集x进行聚类。
# .labels_:获取每个样本的聚类标签。
# metrics.silhouette_score(x, labels):计算轮廓系数,评估聚类效果。
# 轮廓系数的取值范围为[-1, 1],值越接近1表示聚类效果越好。
# scores.append(score):将当前K值的轮廓系数添加到scores列表中。
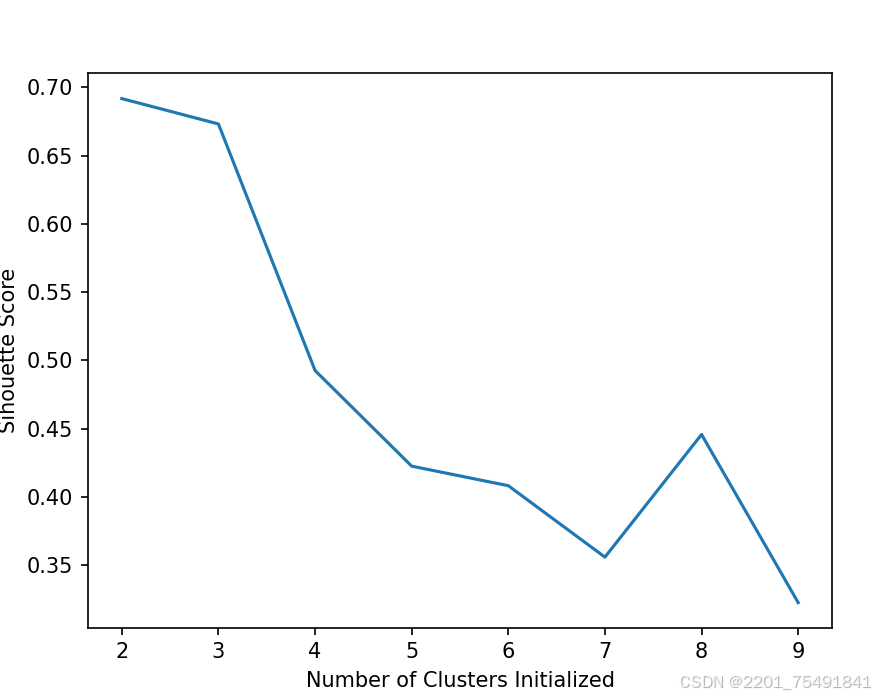
#绘制轮廓系数随K值变化的折线图
plt.plot(list(range(2, 10)), scores)
plt.xlabel("Number of Clusters Initialized")
plt.ylabel("Sihouette Score")
plt.show()
# plt.plot(list(range(2, 10)), scores)绘制K值(2到9)与轮廓系数的折线图。
# plt.xlabel和plt.ylabel:设置X轴和Y轴的标签。
# plt.show():显示图表。
# 通过观察轮廓系数的变化,可以选择最佳的K值(轮廓系数最大的K值)。
#使用最佳K值进行聚类
km = KMeans(n_clusters=2).fit(x)
beer['cluster'] = km.labels_
# KMeans(n_clusters=2):初始化K-Means模型,设置簇的数量为2(假设轮廓系数在K=2时最大)。
# .fit(x):对数据集x进行聚类。
# km.labels_:获取每个样本的聚类标签。
# beer['cluster'] = km.labels_:将聚类标签添加到beer数据集中,作为新的一列cluster。
#计算最终聚类结果的轮廓系数
score = metrics.silhouette_score(x, beer.cluster)
print(score)
# metrics.silhouette_score(x, beer.cluster):计算最终聚类结果的轮廓系数。
# print(score):输出轮廓系数。打印输出结果,得到轮廓系数随K值变化的折线图以及最终聚类结果的轮廓系数

7. 总结
K-Means聚类算法是一种简单而高效的聚类方法,广泛应用于各种领域。尽管K-Means算法存在一些局限性,如需要预先设定K值、对初始值敏感等,但通过合理的选择和优化,K-Means算法仍然能够取得良好的聚类效果。希望本文能够帮助读者更好地理解和掌握K-Means聚类算法,并在实际应用中发挥其强大的功能。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









