







解释一个机器学习模型是一个困难的任务,因为我们不知道这个模型在那个黑匣子里是如何工作的。但是解释也是必需的,这样我们可以选择最佳的模型,同时也使其健壮。
Shap 是一个开源的 python 库,用于解释模型。它可以创建多种类型的可视化,有助于了解模型和解释模型是如何工作的。
在本文中,我们将会分享一些 Shap 创建的不同类型的机器学习模型可视化。我们开始吧…
技术提升
本文由技术群粉丝分享,项目源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:mlc2060,备注:来自CSDN +技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:加群
安装所需的库
使用pip安装Shap开始。下面给出的命令可以做到这一点。
pip install shap
导入所需库
在这一步中,我们将导入加载数据、创建模型和创建该模型的可视化所需的库。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import shap
from sklearn.model_selection import train_test_split
import xgboost as xgb
创建模型
在这一步中,我们将创建机器学习模型。在本文中,我将创建一个XGBoost模型,但是你可以选择任何模型。我们将用于此模型的数据集是著名的糖尿病数据集,可从Kaggle下载。
df = pd.read_csv('/content/Diabetes.csv')
features = ['Pregnancies', 'Glucose','BloodPressure','SkinThickness','Insulin','BMI','DiabetesPedigreeFunction','Age']
Y = df['Outcome']
X = df[features]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 1234)
xgb_model = xgb.XGBRegressor(random_state=42)
xgb_model.fit(X_train, Y_train)

创建可视化
现在我们将为shap创建解释程序,找出模型的shape值,并使用它们创建可视化效果。
explainer = shap.Explainer(xgb_model)
shap_values = explainer(X_test)
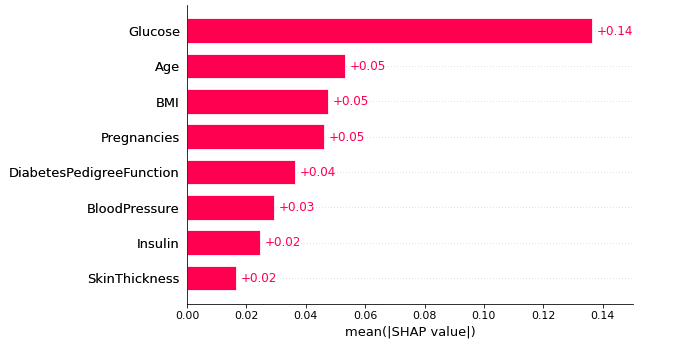
1、Bar Plot
shap.plots.bar(shap_values, max_display=10)
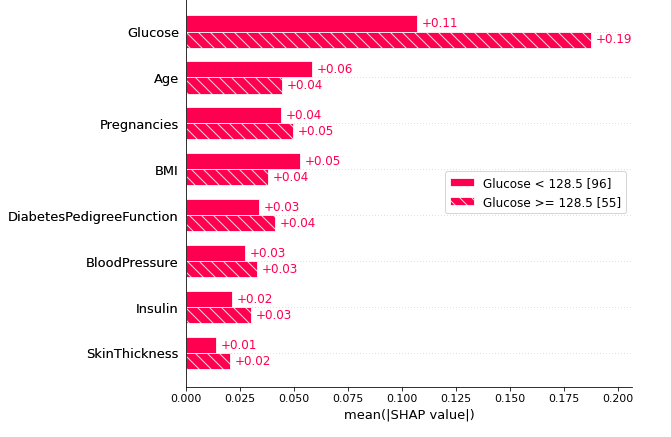
2、队列图
shap.plots.bar(shap_values.cohorts(2).abs.mean(0))
3、热图
shap.plots.heatmap(shap_values[1:100])

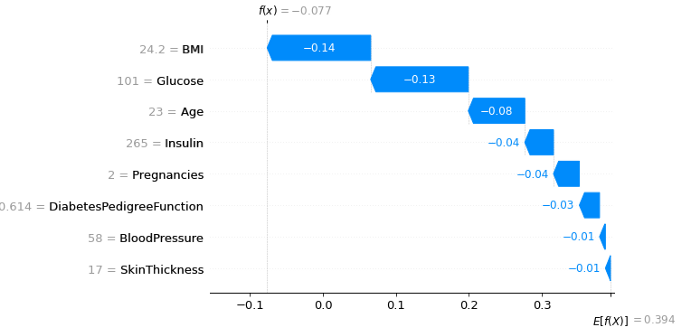
4、瀑布图
shap.plots.waterfall(shap_values[0]) # For the first observation
5、力图
shap.initjs()
explainer = shap.TreeExplainer(xgb_model)
shap_values = explainer.shap_values(X_test)
def p(j):
return(shap.force_plot(explainer.expected_value, shap_values[j,:], X_test.iloc[j,:]))
p(0)

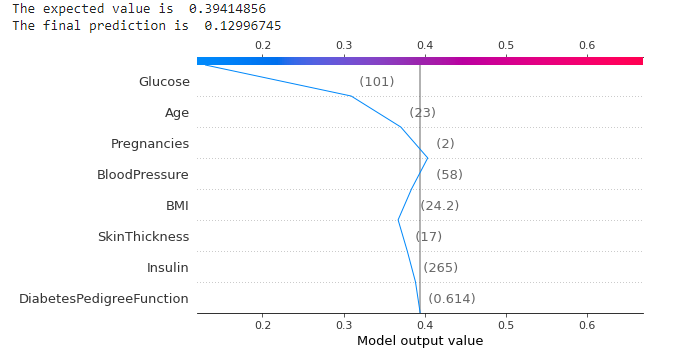
6、决策图
shap_values = explainer.shap_values(X_test)[1]
print("The expected value is ", expected_value)
print("The final prediction is ", xgb_model.predict(X_test)[1])
shap.decision_plot(expected_value, shap_values, X_test)
这就是如何使用 Shap 创建与机器学习模型相关的可视化并对其进行分析。


















 7646
7646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









