







节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学.
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集:
T5模型介绍
T5(Text-to-Text Transfer Transformer)是谷歌提出的一种通用的预训练语言模型,旨在统一自然语言处理任务的输入和输出。
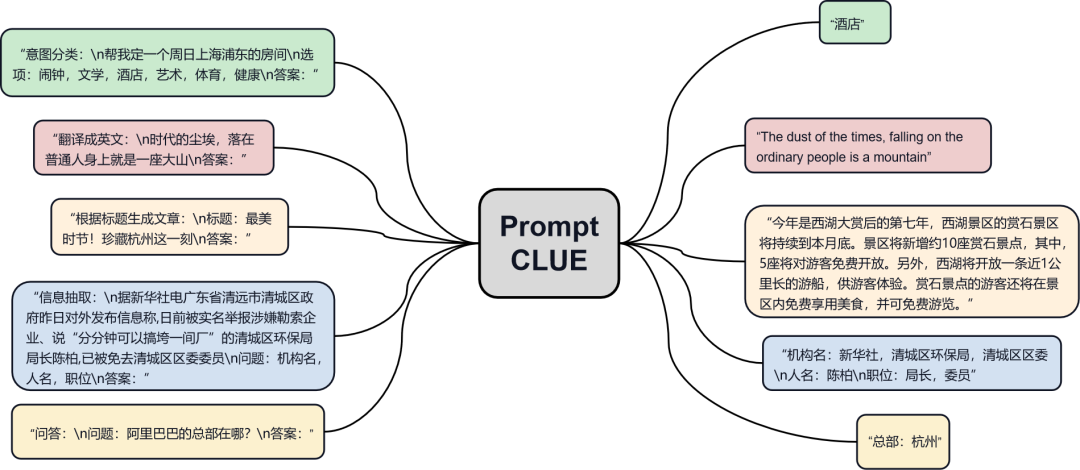
T5模型特点
相比于以往的预训练语言模型,T5的一个显著特点是不需要添加非线性层,也不需要对模型进行额外的改动,只需在输入数据前加上任务声明前缀即可。这意味着在处理各种自然语言处理任务时,可以大大简化模型的使用和微调过程。
T5将所有任务都转化为文本到文本的形式,并使用一个统一的模型来解决。其核心理念是使用前缀任务声明及文本答案生成,这样在微调过程中就无需对模型进行改动,只需要提供相应任务的微调数据。
T5使用方法
在T5中,输入是一个带有任务前缀声明的文本序列,这个前缀声明指定了模型应该执行的任务。输出则是相应任务的结果,以文本序列的形式呈现。这种一致的输入输出格式使得T5在处理各种自然语言处理任务时更加方便和统一。
T5模型加载与预测
- 模型加载
import torch
from transformers import T5Tokenizer, T5Config, T5ForConditionalGeneration
# load tokenizer and model
pretrained_model = "IDEA-CCNL/Randeng-T5-784M-MultiTask-Chinese"
special_tokens = ["<extra_id_{}>".format(i) for i in range(100)]
tokenizer = T5Tokenizer.from_pretrained(
pretrained_model,
do_lower_case=True,
max_length=512,
truncation=True,
additional_special_tokens=special_tokens,
)
config = T5Config.from_pretrained(pretrained_model)
model = T5ForConditionalGeneration.from_pretrained(pretrained_model, config=config)
model.resize_token_embeddings(len(tokenizer))
model.eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = 'cpu'
model.to(device)
- 模型预测(意图识别任务为例)
text = "意图识别任务:还有双鸭山到淮阴的汽车票吗13号的 这篇文章的类别是什么?Travel-Query/Music-Play/FilmTele-Play/Video-Play/Radio-Listen/HomeAppliance-Control/Weather-Query/Alarm-Update/Calendar-Query/TVProgram-Play/Audio-Play/Other"
encode_dict = tokenizer(text, max_length=512, padding='max_length',truncation=True)
inputs = {
"input_ids": torch.tensor([encode_dict['input_ids']]).long().to(device),
"attention_mask": torch.tensor([encode_dict['attention_mask']]).long().to(device),
}
# generate answer
logits = model.generate(
input_ids = inputs['input_ids'],
max_length=100,
do_sample= True
)
logits=logits[:,1:]
predict_label = [tokenizer.decode(i,skip_special_tokens=True) for i in logits]
T5模型微调
- 处理训练集
max_input_length = 60
max_target_length = 20
def preprocess_function(examples):
model_inputs = tokenizer(head_prefix + examples["document"], max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
labels = tokenizer(text_target=examples["summary"], max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
train_tokenized_id = train_ds.map(preprocess_function, remove_columns=train_ds.column_names)
eval_tokenized_id = eval_ds.map(preprocess_function, remove_columns=train_ds.column_names)
- 定义模型训练参数
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
batch_size = 4
args = Seq2SeqTrainingArguments(
"t5-finetuned",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
gradient_accumulation_steps=10,
do_eval=True,
evaluation_strategy="steps",
eval_steps=50,
num_train_epochs=5,
save_steps=50,
save_on_each_node=True,
gradient_checkpointing=True,
load_best_model_at_end=True
)
trainer = Seq2SeqTrainer(
model=model,
args=args,
train_dataset=train_tokenized_id,
eval_dataset=eval_tokenized_id,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer),
)
trainer.train()
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了大模型算法岗技术与面试交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2040,备注:技术交流
用通俗易懂方式讲解系列
- 用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
- 用通俗易懂的方式讲解:1.6万字全面掌握 BERT
- 用通俗易懂的方式讲解:NLP 这样学习才是正确路线
- 用通俗易懂的方式讲解:28张图全解深度学习知识!
- 用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
- 用通俗易懂的方式讲解:实体关系抽取入门教程
- 用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
- 用通俗易懂的方式讲解:图解 Transformer 架构
- 用通俗易懂的方式讲解:大模型算法面经指南(附答案)
- 用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
- 用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
- 用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
- 用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
- 用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
- 用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
- 用通俗易懂的方式讲解:面了 5 家知名企业的NLP算法岗(大模型方向),被考倒了。。。。。
- 用通俗易懂的方式讲解:NLP 算法实习岗,对我后续找工作太重要了!。
- 用通俗易懂的方式讲解:理想汽车大模型算法工程师面试,被问的瑟瑟发抖。。。。
- 用通俗易懂的方式讲解:基于 Langchain-Chatchat,我搭建了一个本地知识库问答系统
- 用通俗易懂的方式讲解:面试字节大模型算法岗(实习)
- 用通俗易懂的方式讲解:大模型算法岗(含实习)最走心的总结
- 用通俗易懂的方式讲解:大模型微调方法汇总


















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









