







最近这一两周看到不少互联网公司都已经开始秋招提前批面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结链接如下:
喜欢本文记得收藏、关注、点赞。
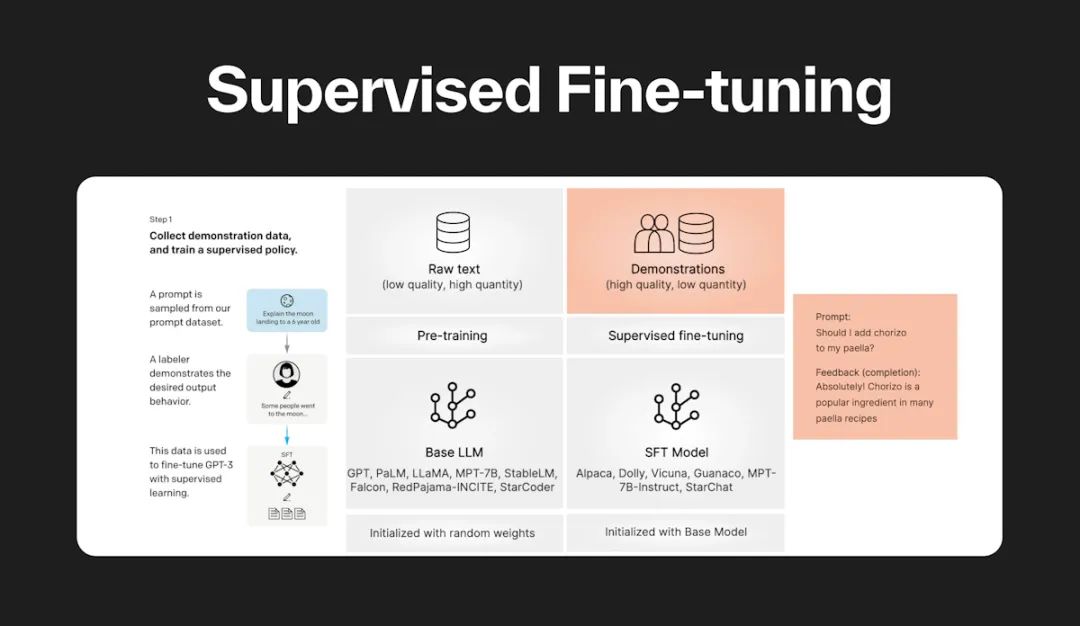
在生成式AI和大语言大模型(如GPT、LLaMA)的广泛应用中,微调(Fine-tuning)作为模型适应特定任务的关键步骤,其重要性不言而喻。以下将详细介绍三种流行的微调方式:Prompt-tuning、Prefix-tuning和LoRA,深入理解每种方法的原理、特点及应用场景。
方式一:Prompt-tuning
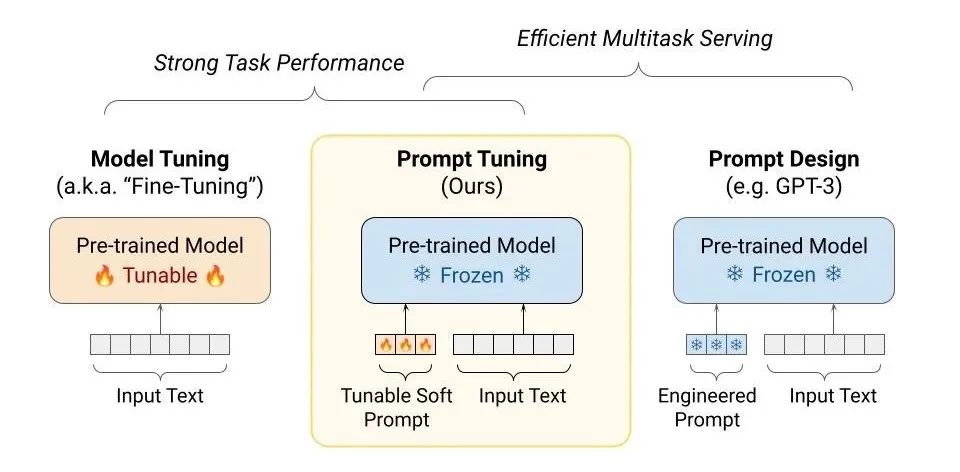
什么是Prompt-tuning?Prompt-tuning通过修改输入文本的提示(Prompt)来引导模型生成符合特定任务或情境的输出,而无需对模型的全量参数进行微调。
这种方法利用了预训练语言模型(PLM)在零样本或少样本学习中的强大能力,通过修改输入提示来激活模型内部的相关知识和能力。
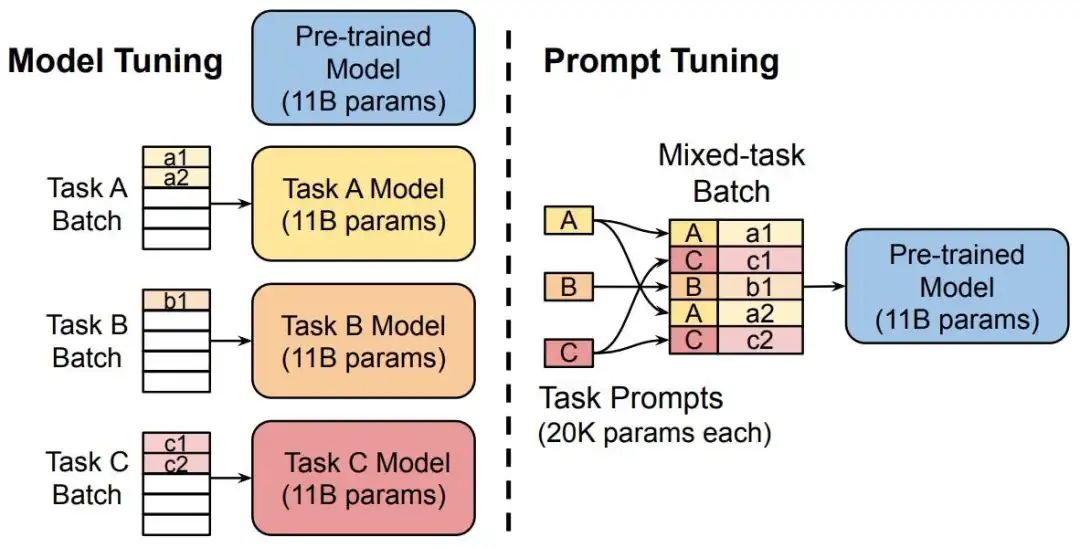
核心原理:PLM(预训练模型)不变,W(模型的权重)不变,X(模型输入)改变。
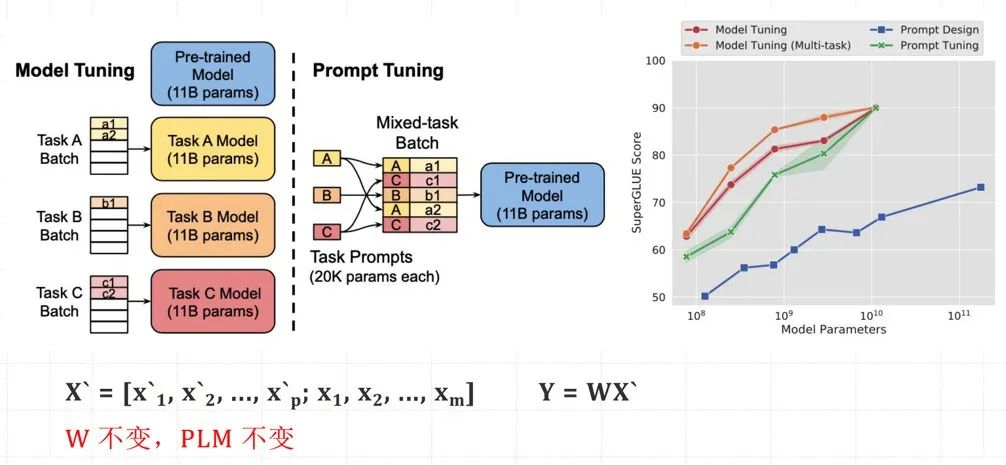
如何进行Prompt-tuning?小模型适配下游任务
设计任务相关提示模板,并微调提示嵌入以引导预训练模型适应特定任务。仅需微调少量提示嵌入(Prompt Embeddings),而非整个模型参数。
Prompt-tuning
- 设计提示模板:
- 模板中应包含任务描述、输入文本占位符、输出格式要求等元素。
- 准备数据集:
- 数据集应包括输入文本、真实标签(对于监督学习任务)或预期输出格式(对于生成任务)。
- 微调提示嵌入:
- 在预训练模型的输入层添加提示嵌入层,使用数据集对模型进行训练,特别是微调提示嵌入。
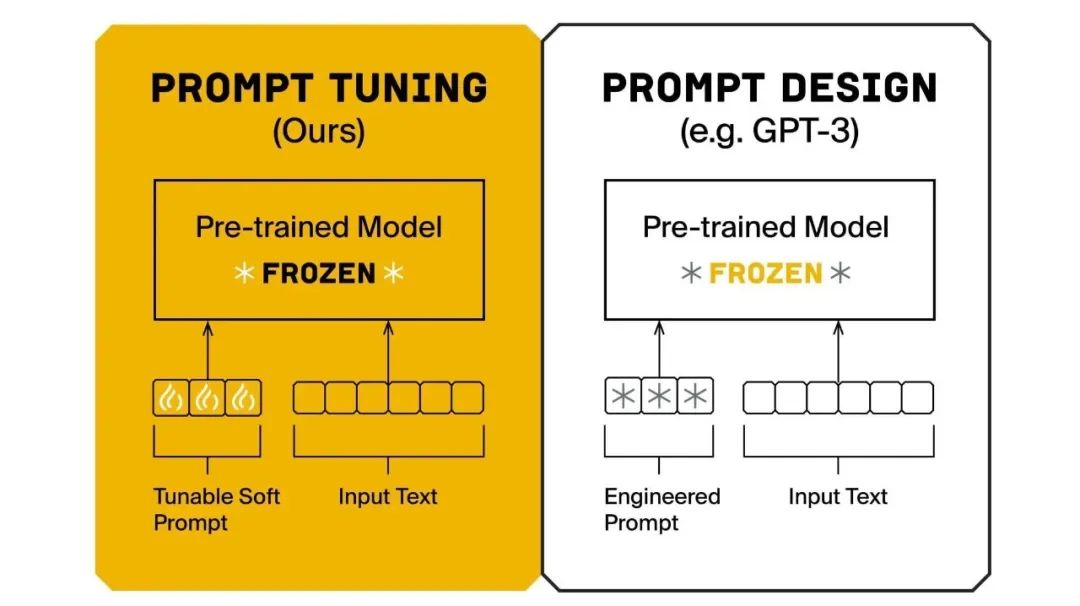
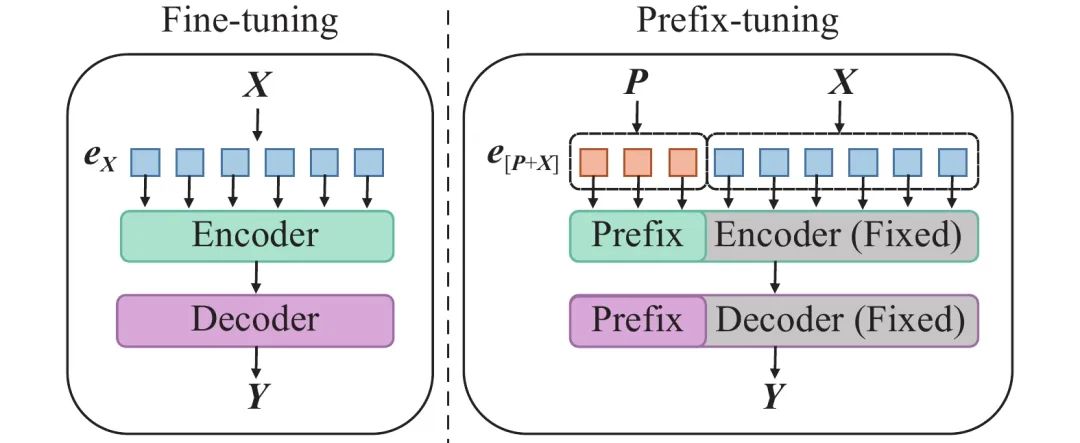
方式二:Prefix-tuning
什么是Prefix-tuning?Prefix-tuning是Prompt-tuning的一种变体,它通过在输入文本前添加一段可学习的“前缀”来指导模型完成任务。
这个前缀与输入序列一起作为注意力机制的输入,从而影响模型对输入序列的理解和表示。由于前缀是可学习的,它可以在微调过程中根据特定任务进行调整,使得模型能够更好地适应新的领域或任务。
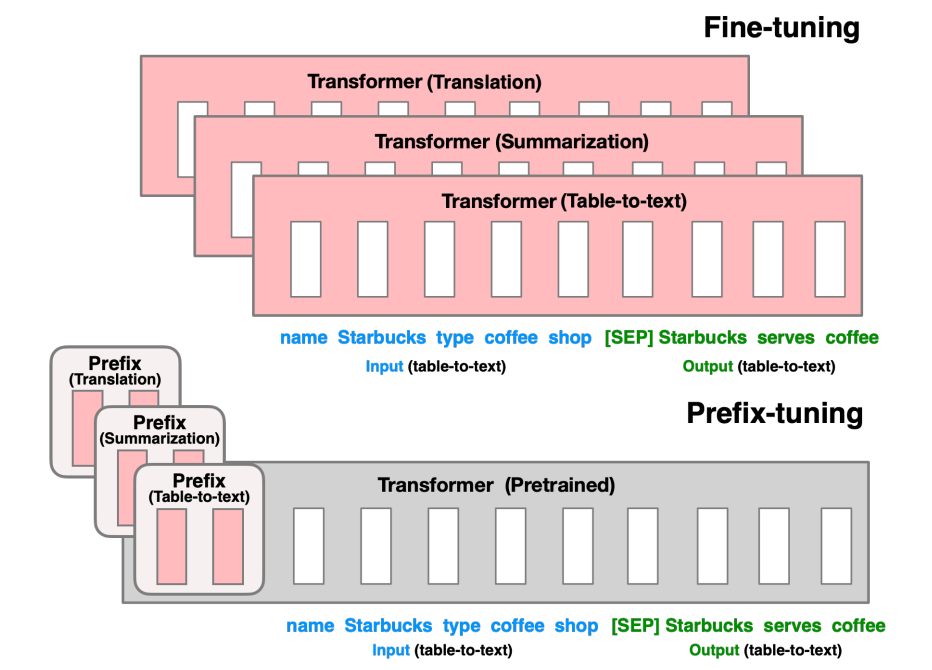
核心原理:PLM(预训练模型)不变,W(模型的权重)不变,X(模型输入)不变,增加W’(前缀嵌入的权重)。
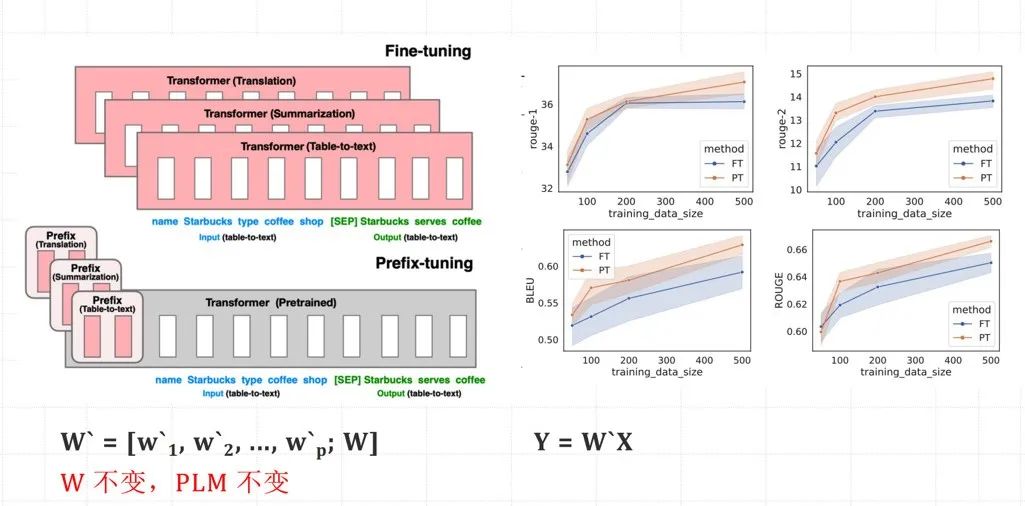
如何进行Prefix-tuning?在 Transformer 中适配下游任务
在Transformer模型的输入层或各层输入前添加可学习的前缀嵌入,并通过训练这些前缀嵌入来优化模型在特定任务上的表现。
- 初始化前缀嵌入
- 在Transformer模型的输入层之前,初始化一个固定长度的前缀嵌入矩阵。
- 将前缀嵌入与输入序列拼接
- 将初始化好的前缀嵌入与原始输入序列的词嵌入进行拼接,形成新的输入表示。这个新的输入表示将作为Transformer模型各层的输入。
- 训练模型
- 在训练过程中,模型会根据输入序列(包括前缀嵌入)和标签数据进行学习。通过反向传播算法,模型会更新前缀嵌入的参数。
方式三:LoRA
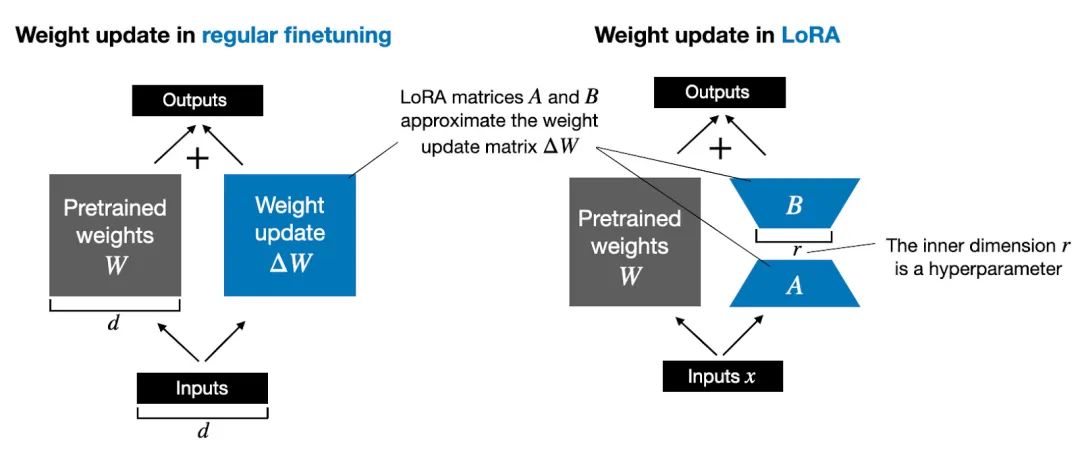
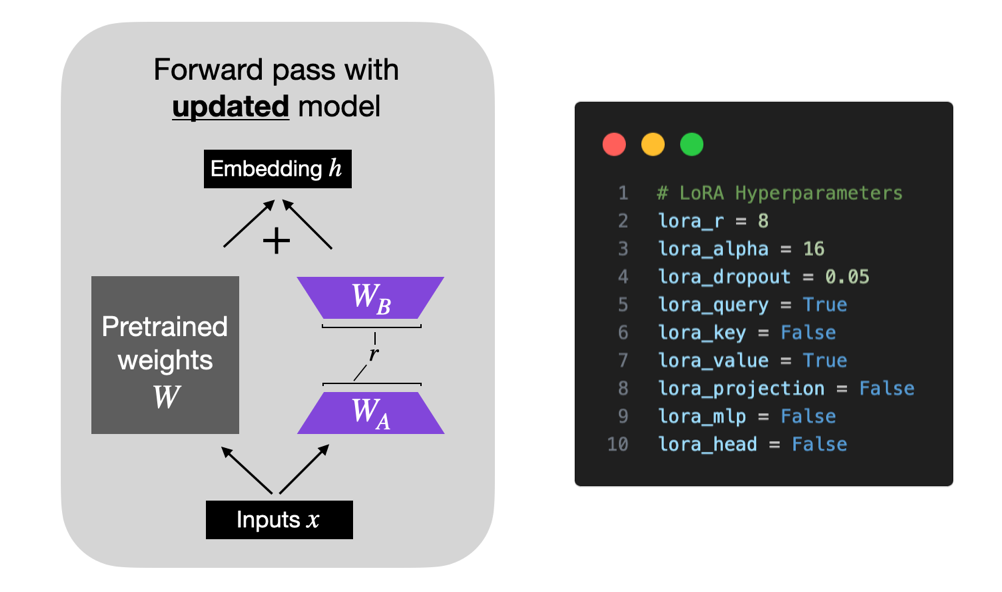
什么是LoRA?LoRA(Low-Rank Adaptation)通过分解预训练模型中的部分权重矩阵为低秩矩阵,并仅微调这些低秩矩阵的少量参数来适应新任务。
对于预训练权重矩阵W0∈Rd×d𝑊0∈𝑅𝑑×𝑑,LoRa限制了其更新方式,即将全参微调的增量参数矩阵ΔWΔ𝑊表示为两个参数量更小的矩阵A、B,即ΔW = AB。
其中,B∈Rd×r𝐵∈𝑅𝑑×𝑟和A∈Rr×d𝐴∈𝑅𝑟×𝑑为LoRA低秩适应的权重矩阵,秩r𝑟远小于d𝑑。
核心原理:W(模型的权重)不变,X(模型输入)不变,分解ΔW(分解为两个低秩矩阵A、B)。
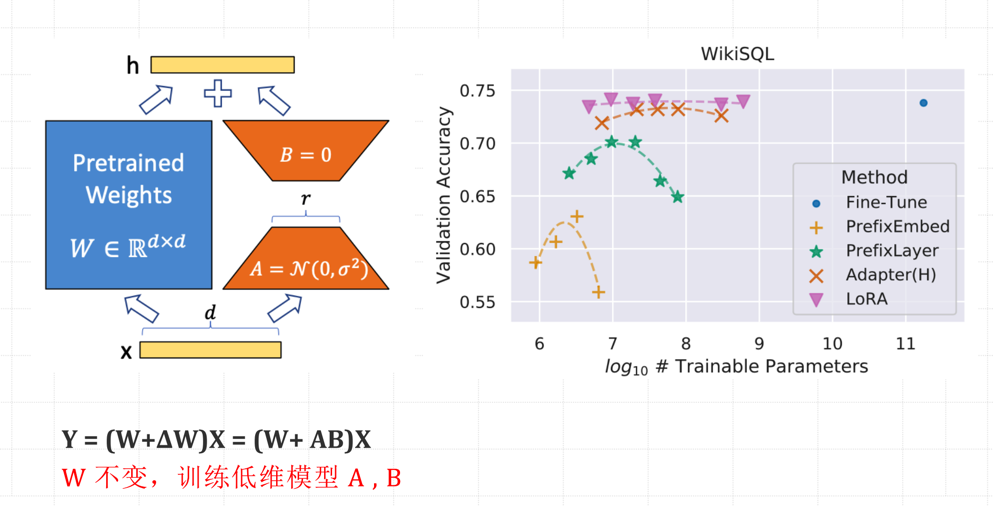
如何进行LoRA微调?在冻结预训练模型权重的基础上,通过优化算法训练低秩矩阵A和B以近似增量参数,最小化下游任务损失,从而实现高效的模型微调。
- 设置LoRA模块
-
在预训练模型的基础上,添加LoRA模块。LoRA模块通常包含两个参数量较少的矩阵A和B,它们的乘积用于近似全参数微调中的增量参数。
-
初始化矩阵A和B,通常使用高斯函数进行初始化,以确保训练开始时LoRA的旁路(即BA)为0,从而与全参数微调有相同的起始点。
- 训练LoRA模块
-
在训练过程中,冻结预训练模型的权重,仅训练LoRA模块中的矩阵A和B。
-
通过优化算法(如Adam)更新矩阵A和B的参数,以最小化下游任务的损失函数。
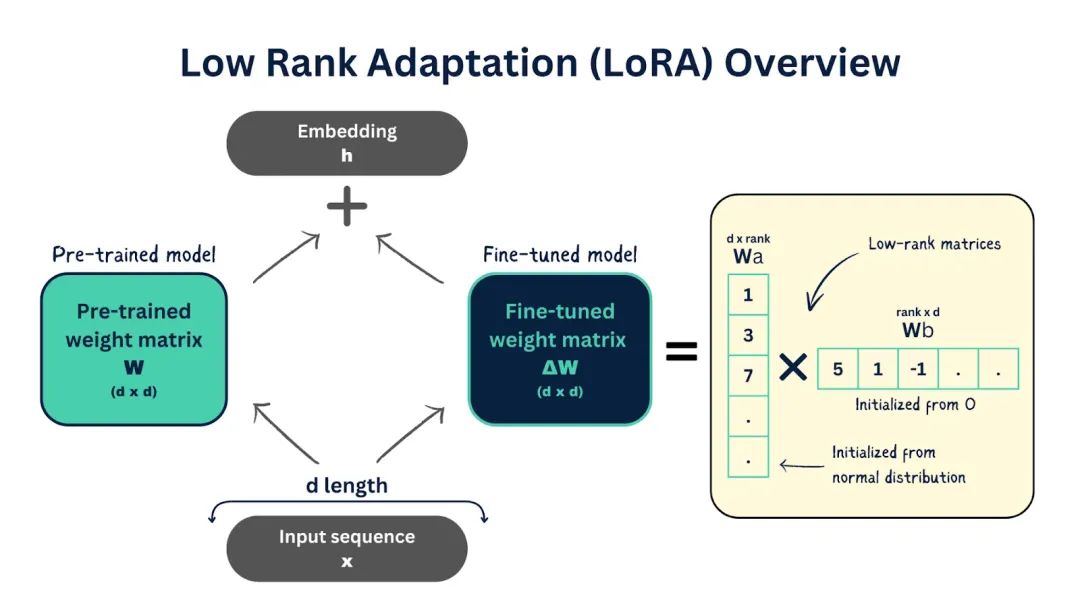
LoRA
LLaMA-Factory通过集成LoRA微调方法,为大型语言模型提供高效、低成本的微调方案,支持多模型、多算法和实时监控,仅训练低秩矩阵实现快速适应新任务。

LoRA参数主要包括秩(lora_rank,影响性能和训练时间)、缩放系数(lora_alpha,确保训练稳定)和Dropout系数(lora_dropout,防止过拟合),它们共同影响模型微调的效果和效率。

1. 秩(Rank)
-
参数名称:
lora_rank -
描述:秩是LoRA中最重要的参数之一,它决定了低秩矩阵的维度。
-
常用值:对于小型数据集或简单任务,秩可以设置为1或2;对于更复杂的任务,秩可能需要设置为4、8或更高。
2. 缩放系数(Alpha)
-
参数名称:
lora_alpha -
描述:缩放系数用于在训练开始时对低秩矩阵的更新进行缩放。
-
常用值:缩放系数的具体值取决于秩的大小和任务的复杂度。
3. Dropout系数
-
参数名称:
lora_dropout -
描述:Dropout系数决定了在训练过程中随机丢弃低秩矩阵中元素的概率。
-
常用值:Dropout系数的常用值范围在0到1之间。
参考资料
-
《The Power of Scale for Parameter-Efficient Prompt Tuning》
-
《Prefix-Tuning: Optimizing Continuous Prompts for Generation》
-
《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》

















 3175
3175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









