







最近已有不少大厂都在秋招宣讲,也有一些已在 Offer 发放阶段了。
节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。
总结链接如下:
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们星球
去面试大模型岗位,百度面试官一脸严肃地问:“Sparse Attention 如何与长文本进行结合?你心里一慌,这题超纲啦!
突然你灵机一动,回答:“就像给长文本找个“保姆”,Sparse Attention 负责挑重点照顾,让长文本不再“任性乱跑”。
面试官忍不住笑了,你却心里慌得一比…现在咱们正式来探讨这个问题~
01
面试官心理
这是一道经典的面试题,Sparse Attention 如何与长文本进行结合?
面试官问这个问题,主要是想看看,你有没有关注过相关的 paper,了不了解相关的算法?以及能不能说清楚其核心思想?
同时这道题目还可以做多个 follow up,看看候选人的横向思考和实际解决问题的能力。
02
面试题解析
所以针对这个问题呢,你可以给面试官介绍一种通过稀疏注意力机制,为更长的序列构建 Transformer 的算法,叫做 BigBird 稀疏 Attention。
然后详细讲讲它是怎么做到和长文本结合的?
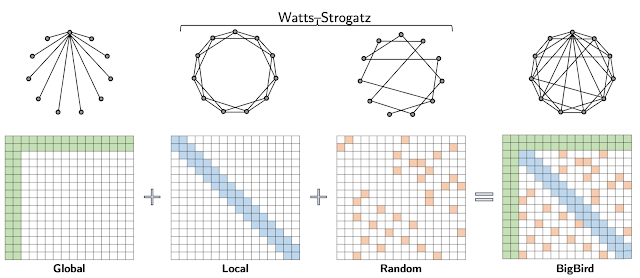
我们结合图来看,BigBird 主要包含三部分:
-
Attention 输入序列的全局标记
-
Attention 局部相邻 token 的标记
-
Attention 随机 token 的标记
从注意力矩阵可以看到,输入长度所需的计算量,从平方降低到了线性。无论是对于结构化和非结构化的任务,这种设计都可以扩展到更长的序列长度。
并且还可以通过 gradient checkpoint,用序列长度来换取训练时间,以实现进一步的扩展。
好,这个问题其实回答到这里就 OK 了,不过一些头铁的面试官可能会继续深挖:那后续如何改进呢?能不能说下你的思路呢?
这个问题就比较 open 了,面试官问这个呢,主要是看你的一个横向思考和解决问题的能力。
我们知道,上下文扩展其实一直都是业界研究的一个热点问题,Sparse Attention 只是从注意力计算层面,降低了长上下文带来的计算复杂度。
除此之外呢,像位置编码的设计好坏,其实也是影响长下文性能的一个关键因素。
比如通过修改位置编码,比如结合 ROPE,AliBi 等编码算法,也可以使大模型支持更长的上下文。
除了节省计算,我们还可以从硬件架构层面考虑,和稀疏注意力技术结合。因为长上下文带来的,不仅仅是计算的增加,还会带来显存的显著增加,如果单卡 GPU 放不了,这时候就要考虑分布式多卡的解决方案。
所以我们可以怎么做呢?把 Sparse Attention 和 Ring Attention 结合起来,其中 Ring Attention 是一种利用分布式注意力的计算方法。
我们希望的是,上下文能够随卡数线性扩展.卡越多,上下文越长,这样就可以利用硬件,实现超长的上下文。
举个例子,假设有 N 张卡,那么一个自然的思路,就是让每张卡去算 1/N 的上下文 ,Ring Attention 就是基于这种切分方法。
它的思路是,将单卡内部做的分块优化扩展到多卡上,通过跨卡点对点的传递 K,V 向量,来实现完整注意力,在不做近似地情况下完成超长上下文的计算。
这样我们通过 Ring Attention 解决了显存瓶颈,通过 Sparse Attention 解决了计算瓶颈,二者结合,就实现了线性内存扩展与序列长度的匹配优化,从而完成了高效的实现。
所以当被问到这类开放性的问题时,大家应该多从不同的角度思考,给面试官展现出你解决问题的能力。















 7443
7443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









