







摘要
CLIP(Contrastive Language-Image Pre-training)模型是由OpenAI在2021年提出的一种多模态预训练神经网络。该模型通过对比学习的方式,将图像和文本映射到同一个嵌入空间中,使得相关联的图像和文本在向量空间中彼此接近。CLIP模型因其出色的零样本学习能力和跨模态检索能力,在多个领域展现出了巨大的潜力和应用价值。
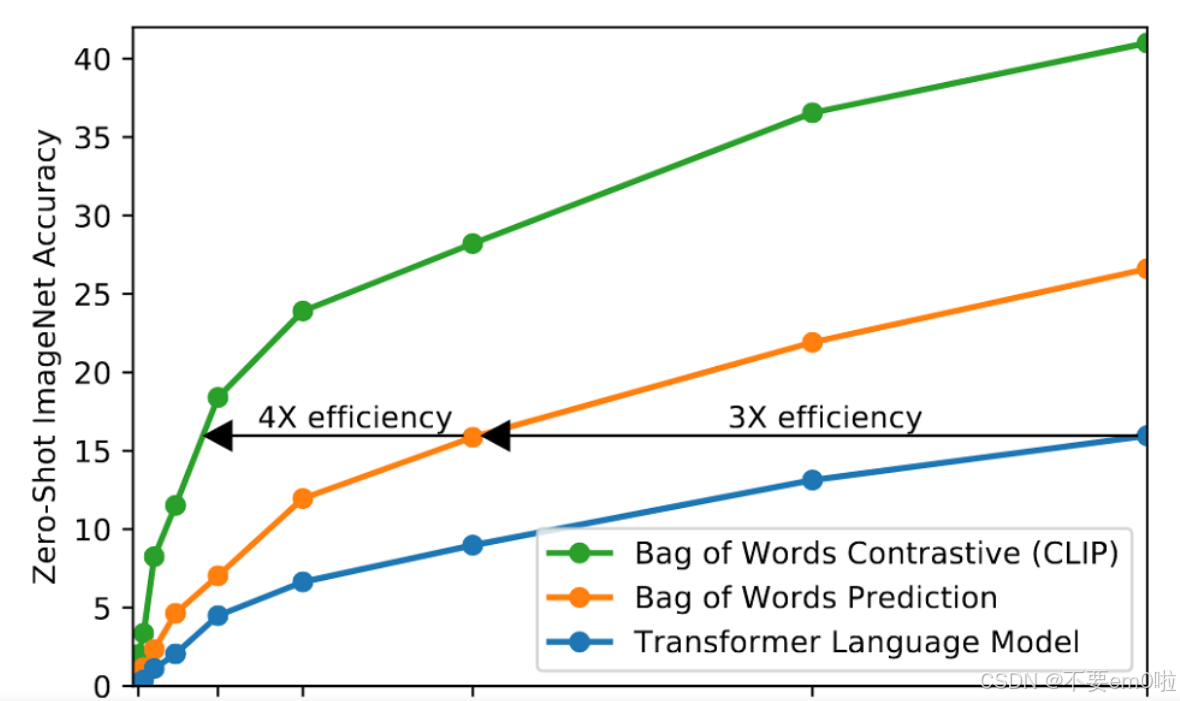
CLIP模型的架构设计
CLIP模型的核心架构包括两个子模块:一个文本编码器和一个图像编码器。文本编码器通常采用基于Transformer的结构,用于处理自然语言文本。而图像编码器则负责将图像转换为相应的向量表示。在CLIP的原始实现中,图像编码器可以是ResNet也可以是Vision Transformer (ViT),而文本编码器则基于Transformer。这两种编码器通过对比学习将图像和文本的特征对齐。
CLIP模型的训练过程
CLIP模型的训练过程基于对比学习的方法,通过大规模的图像和文本数据进行预训练。在训练时,模型将图像和文本分别嵌入到相同的向量空间中,然后通过对比学习的方法,使正确的图像-文本对之间的相似度最大化,错误的图像-文本对之间的相似度最小化。这个过程在大规模数据集上进行预训练,使模型能够在无监督的情况下学习到有效的特征表示。
CLIP模型的应用场景
CLIP模型的应用场景非常广泛,涵盖了计算机视觉和自然语言处理的多个方面。主要应用场景包括:
1. 图像搜索:通过给定的文本描述,CLIP可以在大量图像中找到与该描述最相关的图像。
2. 图像分类:CLIP可以通过文本描述直接对图像进行分类,减少了人工标注的工作。
3. 跨模态检索:CLIP可以实现文本到图像、图像到文本的检索,适用于需要同时处理多模态数据的应用。
4. 生成式AI:CLIP也为图像生成模型提供了支持,例如结合DALL-E等模型生成符合文本描述的图像。
CLIP模型的局限性与挑战
尽管CLIP模型在多模态学习领域取得了显著的成果,但它仍面临着一些挑战和局限性。例如,CLIP模型的规模极大,训练和推理过程中需要消耗大量的计算资源。此外,CLIP在细粒度视觉理解上存在不足,限制了其在多模态大型语言模型中的感知能力。
CLIP模型的未来发展
CLIP模型的未来发展可能会朝以下几个方向前进:
1. 更大规模和多样化的预训练:未来的多模态模型将通过更多元化的数据进行预训练,以实现更全面的感知和理解。
2. 模型轻量化与优化:如何在不损失模型性能的前提下进行优化,减少计算资源消耗,是重要的发展方向。
3. 生成式AI与多模态模型的深度融合:随着生成式AI的发展,未来的多模态模型有望在图像、视频、语音等多领域实现复杂内容生成。
结论
CLIP模型作为OpenAI推出的突破性多模态模型,在图像和文本的对齐、跨模态检索、零样本学习等领域做出了重要贡献。它开创性地将对比学习应用于大规模图像-文本对,并成功地训练了能够处理多个任务的通用模型。未来,CLIP的影响不仅局限于学术研究,还将在工业应用中发挥重要作用。


















 1909
1909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









