







code:https://llm-grounded-diffusion.github.io.
Abstract
文本到图像扩散模型的最新进展在生成逼真和多样化的图像方面取得了令人印象深刻的结果。然而,这些模型仍然难以处理复杂的提示,比如那些涉及计算和空间推理的提示。这项工作旨在提高对扩散模型的快速理解能力。我们的方法利用一个预训练的大型语言模型(大型语言模型)在一个新的两阶段过程中进行接地生成。在第一阶段,大型语言模型生成一个场景布局,该布局由描述所需图像的给定提示框组成。在第二阶段,一种新的控制器引导现成的扩散模型用于布图接地图像生成。这两个阶段都利用现有的预训练模型,没有额外的模型参数优化。我们的方法在根据需要各种功能的提示准确生成图像方面明显优于基本扩散模型和几个强基线,平均在四个任务中提高了一倍的生成精度。此外,我们的方法支持基于指令的多轮场景规范,并可以处理底层扩散模型不支持的语言提示。我们预计我们的方法将通过准确地遵循更复杂的提示来释放用户的创造力。
Introduction
即使是最新的SDXL (Podell et al., 2023),也经常无法生成一定数量的对象或理解提示中的否定。它还努力进行空间推理或将属性与对象正确地联系起来。


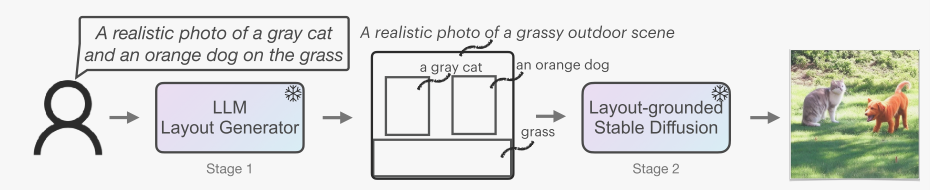
LMD通过一种新的两阶段生成过程增强了文本到图像扩散模型中的提示理解:
1)第一阶段:大型语言模型布局生成器从用户那里获得提示,并以带标题的边界框的形式输出图像布局。
2)第二阶段:由布图接地控制器引导的稳定扩散模型生成最终图像。这两个阶段都使用冷冻预训练模型,这使得我们的方法适用于现成的大型语言模型和其他扩散模型,而无需基于其训练目标。
这两个阶段都使用了预训练的模型---大预言模型和扩散模型
贡献:
- 两阶段无需训练的pipeline
- layout-grounded Stable Diffusion,新颖控制器,引导生成
- prompt 支持更广泛的语言
- 性能好
Related Work
Text-to-image diffusion models.
LLMs for visual grounding. 有些方法依赖CLIP text embedding文本嵌入来讲信息传递给大模型---空间控制力不足。
Spatially-conditioned image generation methods. poses, segmentation maps, strokes, and layouts.很多方法依赖于带有注释的外部数据集,如COCO来提供带有框和标题等注释的图像。此外,基于训练的自适应使得模型与LoRA权重等附加组件不兼容,并且很难从没有框注释的训练集中训练新的LoRA模型。本文提出了一种无需训练的生成控制器,它可以引导现有的文本到图像扩散模型,这些模型没有专门训练用于基于布局的图像生成,也不需要外部数据集。此外,我们的方法还可以与基于训练的方法相结合,以进一步改进。
有些工作基于区域语义生成图像,但对实例没有控制。instruction-based scene specification(基于指令的场景规范)是对图像像素的修改
LLM-grounded Diffusion(LMD)
LLM-based Layout Generation

在阶段1中,LMD根据用户提示生成图像布局。LMD将用户提示嵌入到带有指令和上下文示例的模板中。然后查询大型语言模型是否完成。最后,解析大型语言模型补全以获得一组带标题的边界框、一个背景标题和一个可选的否定提示符。
Layout representation. 1)每个前景对象的标题边界框,坐标以(x, y,宽度,高度)格式;2)描述图像背景的简单而简洁的标题,以及可选的否定提示,指示生成的图像中不应出现的内容。当布局没有对不应该出现的内容施加限制时,否定提示是一个空字符串。
Instructions. Our text instructions to the LLM consist of two parts:
1. 任务说明:您的任务是为标题中提到的对象生成边界框,以及描述场景的背景提示。
2. 支持细节:图片大小为512×512…每个边界框的格式应为…如果需要,你可以做出合理的猜测。
In-context learning. 
LLM completion.

Layout-grounded Stable Diffusion
引入控制器,将图像生成和LLM-ground上。
Per-box masked latents.
一次处理一个边框,对每个对象i![]() ,生成具有单个实例的图像
,生成具有单个实例的图像
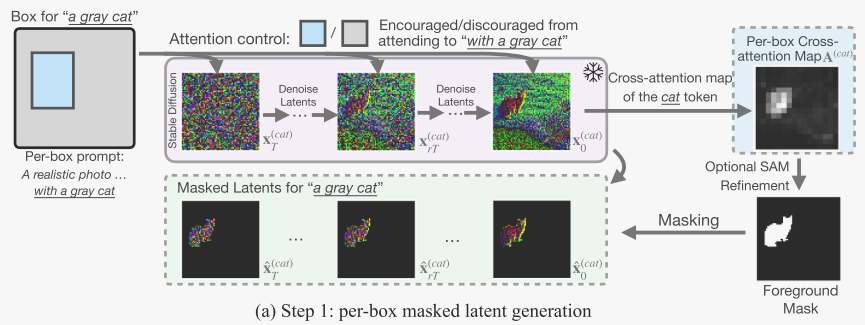
为了确保目标与边界框对齐,我们对噪声预测网络的交叉注意图A(i)进行了操作每个映射描述了从像素到文本标记:![]() 其中,qu和kv分别为提示符中空间位置u的图像特征和标记索引v的文本特征的线性变换。
其中,qu和kv分别为提示符中空间位置u的图像特征和标记索引v的文本特征的线性变换。
为了加强了框内像素对与框标题相关的标记的交叉注意,同时减弱了框外像素的交叉注意,设计了一个能量函数![]()
![]() ,b(i)为i框的二进制掩码(内部为1 外部为0),topku为top-k在空间维度u上的平均值,ω = 4.0,在每个步骤最小化能量函数:
,b(i)为i框的二进制掩码(内部为1 外部为0),topku为top-k在空间维度u上的平均值,ω = 4.0,在每个步骤最小化能量函数:
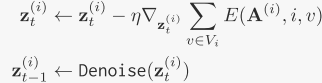 η为引导强度,Vi为第i个边界框的文本索引
η为引导强度,Vi为第i个边界框的文本索引
生成后会得到框与标题对应的交叉注意力图,前景实例的精确掩码表示为m(i)
![]()
Masked latents as priors for instance-level control. 潜特征的实例掩码![]() 为扩散模型提供实例级提示,组合成
为扩散模型提供实例级提示,组合成![]()
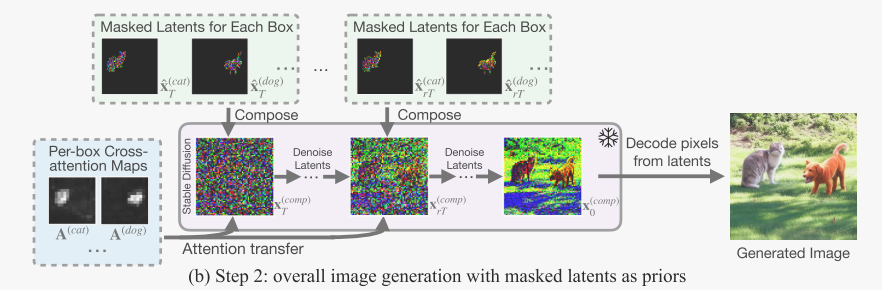
由于扩散模型倾向于在初始去噪步骤中生成目标位置,然后在后续步骤中生成目标细节。
为了使引导更具鲁棒性,进一步调整能量函数将交叉注意图从per-box生成转移到组合生成的相应区域(the corresponding regions in the composed)
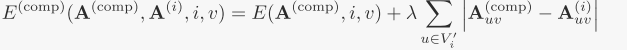
λ = 2.0,i表示整体去噪过程中文本提示框标题对应的token的索引
最后,我们通过扩散图像解码器将z(comp) 0解码为像素x0。有关布局接地的总体伪代码,请参阅附录B。
Integration with training-based methods. 我们的无训练控制器也可以与基于训练的方法(如GLIGEN)一起应用(Li等人,2023b),以便在可用时利用实例注释的外部数据集。由于GLIGEN训练适配器层接受框输入,因此与GLIGEN的集成(记为LMD+)涉及采用其适配器权值并将布局指导传递给适配器层。请注意,LMD+将适配器与上面介绍的实例级指导一起使用,这大大优于仅使用GLIGEN适配器,如表2所示。通过这种集成,我们无需额外的训练就可以实现进一步增强的实例和属性控制。
Additional Capabilities of LMD
Our LLM-grounded generation pipeline allows for two additional capabilities without additional training.
Instruction-based scene specification. 利用支持多轮对话的 LLM(如 GPT-3.5/4),LMD 使用户能够在初始提示后通过多个指令指定所需的图像(图 3)。具体来说,在生成初始图像后,用户只需向 LLM 提出说明或附加要求即可。有了来自 LLM 的更新布局,我们就可以再次利用 LMD 来生成具有更新布局的图像。如图 6 所示,更新布局而非原始图像给 LMD 带来了以下几个优势:1)我们的生成结果在多轮请求后保持一致,而不是逐渐偏离最初的图像。2) LMD 可以处理涉及空间推理的请求,而这正是之前基于指令的图像编辑方法 Brooks 等人(2023 年)的局限所在。相比之下,我们证明了为 ChatGPT 配备了 Brooks 等人(2023)等工具的 VisualChatGPT Wu 等人(2023)无法遵循图 6 中的指令,尤其是多次迭代对话的空间指令。有兴趣的读者可参阅附录 G 进行比较。这种能力适用于 LMD 和 LMD+。我们还在附录 C 的图 C.1 中展示了其他用例。我们的 LMD 可以处理开放式场景调整请求,为当前场景提供建议,在对话上下文中理解用户请求,并允许用户在保留整体图像风格和布局的情况下尝试不同的细节调整,从而促进细粒度内容创建。
Supporting more languages.
通过提供一个非英语用户提示和英语布局输出的内容示例4,LLM 布局生成器可以接受非英语用户提示,并输出带有英语标题的布局。这样就可以生成底层扩散模型不支持的语言提示,而无需额外的训练(图 I.1)。更多详情请参阅附录 I。
Appendix
LDM latent diffusion models
1. ![]() T is a hyperparameter.
T is a hyperparameter.
2. 然后从时间步长t参数化的高斯分布中采样噪声λ,并将其添加到潜在的z0中以获得有噪声的潜在的zt。带参数θ的神经网络通过最小化训练目标来学习预测前向过程的附加噪声ε:![]() 有注意力层的U-Net--扩散U-Net
有注意力层的U-Net--扩散U-Net
3. 推理过程中,有许多不同的采样方法,扩散模型ϵθ从zt中预测噪声向量ϵθ(zt, t)得到zt-1,t初始化为T,![]() ,
,![]() ,αt和σt由方差表
,αt和σt由方差表![]() 参数化,该方差表控制去噪步长的大小。
参数化,该方差表控制去噪步长的大小。
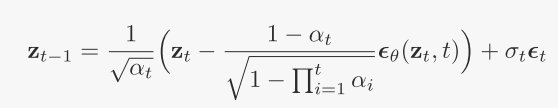
DDIM:
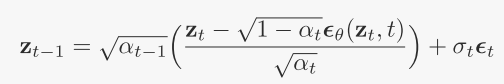 本工作结果是用σt = 0的DDIM得到的
本工作结果是用σt = 0的DDIM得到的
官方表示为:![]()
4. ![]()
Pseudo-code for layout-grounded image generation
- 随机采样高斯噪声zt
- 生成box和background
- 最小化能量函数
- 降噪
- 平均交叉注意力
- SAMRefine对注意图进行内部解码和精化。如果未启用SAM,则执行注意阈值。
- ComposedPrompt
- LatentCompose相对于相应的掩码m(i)在空间上组合每个潜伏z(i),替换掩码位置上目标潜伏的内容。在构成顺序上,先构成掩模后面积最大的掩模潜势。
- AttnTransfer反向引导最小化第3节中的能量函数方程(7),除了注意力控制外,还鼓励盒内整体生成的注意力与每盒生成的注意力相似。

Text-conditional generation through cross-attention.
Stable Diffusion等模型将文本作为输入并执行条件生成。条件生成过程和无条件生成过程的区别是将输入文本处理为文本特征,将token传递给扩散U-Net,并执行无分类器引导(Ho & Salimans, 2022),其描述如下。
条件扩散![]() 不只接受噪声输入xt和时间步长t,还有由文本编码器τθ(·)处理的附加文本条件y。文本编码器是Stable Diffusion中的CLIP文本编码器。在y被标记器标记为离散的标记后,它被Transformer处理为文本特征
不只接受噪声输入xt和时间步长t,还有由文本编码器τθ(·)处理的附加文本条件y。文本编码器是Stable Diffusion中的CLIP文本编码器。在y被标记器标记为离散的标记后,它被Transformer处理为文本特征![]() ,其中l是标记后y中的text tokens的数量,dtext是特征的维度。
,其中l是标记后y中的text tokens的数量,dtext是特征的维度。
文本特征τθ(y)然后由扩散U-Net中的交叉注意层处理,这样U-Net的输出也可以根据文本而变化。为简单起见,我们在本初步介绍中只考虑一个交叉注意头。
每个跨注意层将文本特征τθ(y)线性映射到键向量和值向量![]() 中,其中dattn是注意维度。每个交叉注意层也从U-Net的前一层获取平坦化的2D特征,并将该特征线性映射到查询向量
中,其中dattn是注意维度。每个交叉注意层也从U-Net的前一层获取平坦化的2D特征,并将该特征线性映射到查询向量![]() ,其中m为上一层平坦化的2D图像特征的维数。
,其中m为上一层平坦化的2D图像特征的维数。
![]()
其中,qu和kv分别是提示符中空间位置u的图像特征和标记索引v的文本特征的线性变换。
然后使用注意图计算值v的加权组合:
![]()
![]()
在训练时,以小概率将输入条件τθ(y)随机替换为可学习的空令牌τ∅。在推断时,无分类器指导使用以下项≈ϵθ(xt, t, τθ(y))代替无条件生成更新规则中的预测噪声ϵθ(xt, t):![]() w是引导强度参数,SD设为w=7.5
w是引导强度参数,SD设为w=7.5


















 1816
1816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











