







AI大模型学习
原文转自知乎:叫我Alonzo就好了
在当前技术环境下,AI大模型学习不仅要求研究者具备深厚的数学基础和编程能力,还需要对特定领域的业务场景有深入的了解。通过不断优化模型结构和算法,AI大模型学习能够不断提升模型的准确性和效率,为人类生活和工作带来更多便利。
前言
自2022年Stable Diffusion和ChatGPT诞生以来,扩散模型(diffusion models)和大语言模型(Large Language Models, LLMs)就逐渐成为计算机视觉(CV)和自然语言处理(NLP)两大深度学习主流社区的研究焦点。一方面,在以CLIP为代表的多模态学习迅猛发展之下,加上诸如LAION的大规模图像-文本对训练数据加持下,diffusion models重新定义了图像生成的研究范式;另一方面,LLMs基于GPT的无监督训练范式,在超大规模的语料数据加持下,涌现出了出色的理解和生成能力。
相信对二者都有所了解的朋友,不难想到:**如果我们做一个简单的A+B会怎样?**事实上,近期也确实涌现出了很多“Diffusion + LLMs” 范式的工作,也是笔者一直在思考的idea,今天就借这篇文章就跟大家分享一下个人的一些解读和思考。
Why LLMs?
说到大语言模型,我们首先要理解大语言模型“大”在什么地方。个人的理解是,训练数据规模大、模型参数量大。
一方面,GPT为“训练数据规模大”提供了理论基础,GPT于2017年在《Improving Language Understanding by Generative Pre-Training》一文中提出,标志着language models的训练不再依赖于标注数据,可以通过无监督的方式进行,而正是因为这样,数据量才能提上去。 再在后续Supervised Fine-Tuning(SFT)和Reinforcement Learning Human Feedback(RLHF)的加持下,LLMs在一系列的下游任务上有出色的表现。
另一方面,GPT-3,也就是《Language Models are Few-Shot Learners》一文中已经证明,scaled up之后的language models有出色的few-shot能力,换言之,即拥有大规模参数量的语言模型的应用范围被进一步拓宽。而这一点在前述大规模数据的加持下,充足的模型参数量进一步赋予了模型强大的应用能力。
正是如此,在前述技术背景的支持下,大语言模型“涌现智能”的现象也逐渐被大家所发现。从技术层面上来讲,个人认为具体体现在in-context learning和instruction-following两个方面。首先,GPT“预测下文”的预训练范式,决定了LLMs对于上文信息有着强大的处理和表征能力;其次,通过做SFT或者是RLHF,LLMs的生成结果能够与下游应用进一步对齐,换言之,我们可以通过prompt engineering去定制任意文本的A→B过程。
现在我们了解了LLMs的强大所在,那么为什么要选择LLMs呢? 基于前面说的两个技术要点,现有方法的做法可以总结为文本编码和Text Prompt数据增强两种。
文本编码
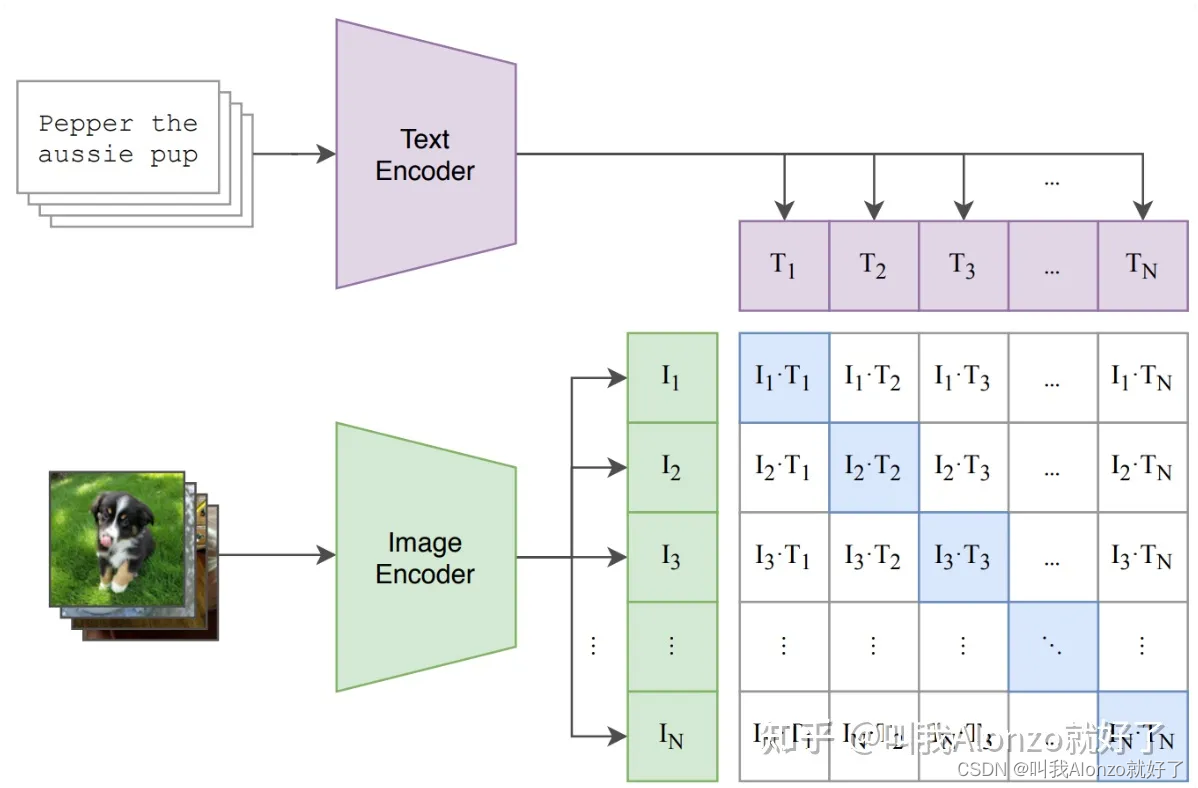
自从Stable Diffusion诞生以来,如果我们对text encoder的选择进行回顾的话,我们会发现text-to-image diffusion models最常采用的模型,一般是CLIP或T5-XXL。
其中,CLIP采用的是无监督训练范式,通过400M个图片-文本对进行训练,通过在隐空间对跨模态特征对齐的方式来获得image-text alignment。但是,值得注意的是,CLIP训练中采用的caption大多为简单、不完整的图片描述,这样的方式决定了CLIP中text encoder编码文本信息的能力是有限的。
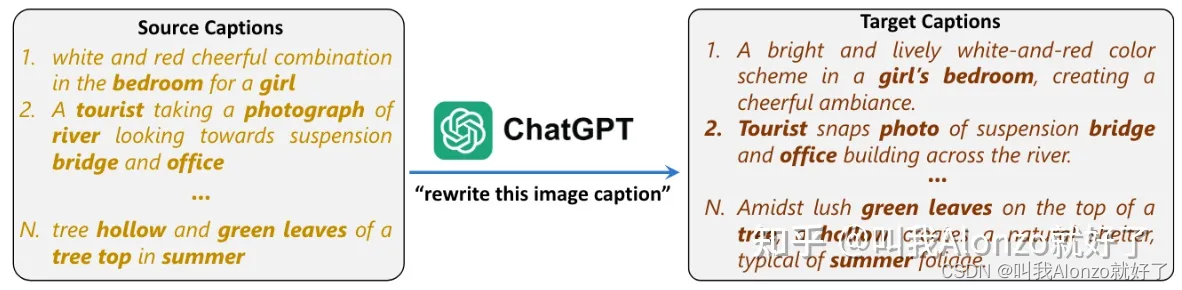
在text-to-image generation这一任务之外,也有其他工作关注了CLIP训练范式的这一局限性。例如LaCLIP在《Improving CLIP Training with Language Rewrites》一文中提出通过让LLMs对文本信息进行rewrite,从而增强image-text pairs中文本信息的丰富程度,进而减少CLIP训练范式中的过拟合问题,并且进一步提升性能。
另外,T5-XXL作为text-to-text generation的统一解决方案,其成功的原因也似乎与in-context learning有着异曲同工之妙。其在text-to-image diffusion models上的应用,证明了text-to-image diffusion models中,文本编码的能力并不一定需要CLIP中所携带的image-text alignment,即纯language models也可以用于编码文本信息。
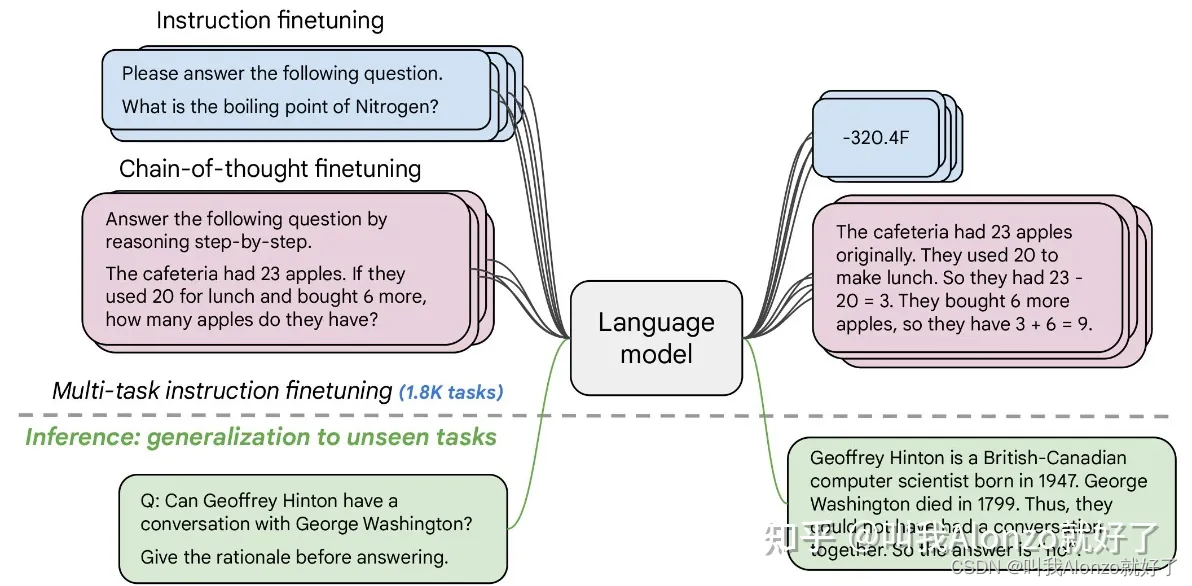
前文说到,LL
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











