






目录
用for循环去获取dict的key, value, (key, value)
DICT(字典)
定义方法:
dict_data = {key:value}
字典中的元素必须具备两个部分:key和value
{元素1, 元素2, 元素3, ......} :可以有多个元素, 元素之间用逗号隔开
元素分解:key(关键字)和value(元素值)
特性:
1.根据关键字去获取内容 2.关键字不能重复 3.关键字必须是不可变的数据类型
目前接触过的不可变数据类型(整形, 浮点型, 复数, 空类型, 字符串,字节, bool型, 元组)【可变:列表,字典】
访问字典:
dict_data[下标]
如果下标存在打印dict_data[下标]对应的值就是下标对应的value值
dict_data[下标] = value
如果下标存在新的值就会覆盖value的值
如果下标不存在下标就会成为新的key值, value就会成为value值
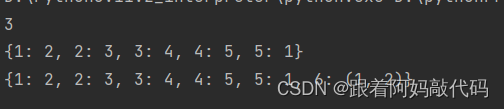
data_dict2 = {1: 2, 2: 3, 3: 4, 4: 5, 5: 6}
print(data_dict2[2])
data_dict2[5] = 1
print(data_dict2)
data_dict2[6] = 1, 2
print(data_dict2)结果如图所示
DICT功能及其用法:
.clear
D.clear() -> None. Remove all items from D.删除字典内所有的值,返回值为空。
此操作是直接在源字典的基础上进行
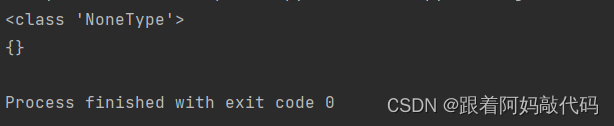
data_dict2 = {1: 2, 2: 3, 3: 4, 4: 5, 5: 6}
data_dict2.clear()
print(type(data_dict2.clear()))
print(data_dict2)结果如下图所示
.copy
D.copy() -> a shallow copy of D. 浅拷贝字典
我会通过两个层面带大家理解字典中的深拷贝于浅拷贝
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
#浅拷贝
data_dict3 = data_dict2.copy()
#深拷贝
data_dict4 = copy.deepcopy(data_dict2)
print(f"{data_dict2.keys()} {id(data_dict2.keys())} {data_dict2[1]} {id(data_dict2[1])} {data_dict2[1][0]} \
{id(data_dict2[1][0])} {data_dict2[1][1]} {id(data_dict2[1][1])} {data_dict2[2]} {id(data_dict2[2])} {data_dict2[3]} \
{id(data_dict2[3])}")
print(f"{data_dict3.keys()} {id(data_dict3.keys())} {data_dict3[1]} {id(data_dict3[1])} {data_dict3[1][0]} \
{id(data_dict3[1][0])} {data_dict3[1][1]} {id(data_dict3[1][1])} {data_dict3[2]} {id(data_dict3[2])} {data_dict3[3]} \
{id(data_dict3[3])}")
print(f"{data_dict4.keys()} {id(data_dict4.keys())} {data_dict4[1]} {id(data_dict4[1])} {data_dict4[1][0]} \
{id(data_dict4[1][0])} {data_dict4[1][1]} {id(data_dict4[1][1])} {data_dict4[2]} {id(data_dict4[2])} {data_dict4[3]} \
{id(data_dict4[3])}")
print("--------深拷贝修改子对象--------")
data_dict2[1].append(111)
print(f"{data_dict4.keys()} {id(data_dict4.keys())} {data_dict4[1]} {id(data_dict4[1])} {data_dict4[1][0]} \
{id(data_dict4[1][0])} {data_dict4[1][1]} {id(data_dict4[1][1])} {data_dict4[2]} {id(data_dict4[2])} {data_dict4[3]} \
{id(data_dict4[3])}")
print("--------浅拷贝修改子对象--------")
data_dict2[1].append(222)
print(f"{data_dict3.keys()} {id(data_dict3.keys())} {data_dict3[1]} {id(data_dict3[1])} {data_dict3[1][0]} \
{id(data_dict3[1][0])} {data_dict3[1][1]} {id(data_dict3[1][1])} {data_dict3[2]} {id(data_dict3[2])} {data_dict3[3]} \
{id(data_dict3[3])}")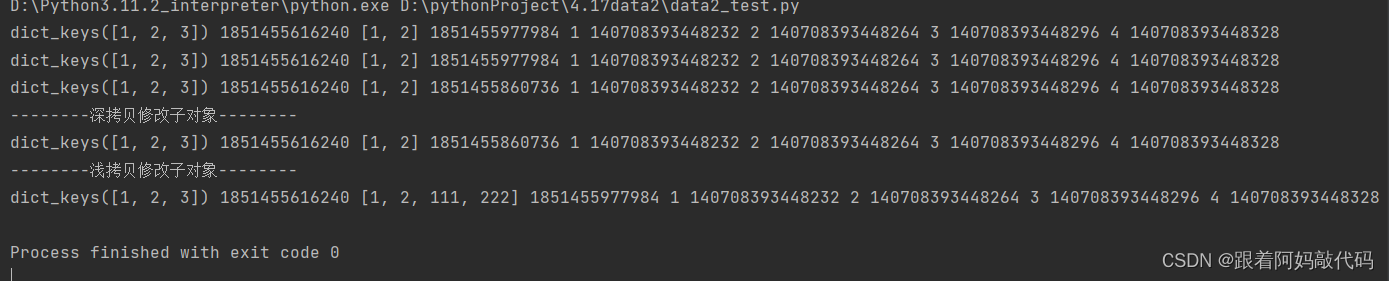
通过输出的结果我们不难发现,
深拷贝中list1于原字典中的list1id不同,但浅拷贝的list1的id于原字典中的list1相同
而且我们在修改子类对象的时候深拷贝中的list1不会发生改变但浅拷贝中的list1发生改变了这是为什么,我通过图像给大家解释一下

这样深拷贝和浅拷贝的区别就显而易见了
.get
get(self, key, default=None, /)
Return the value for key if key is in the dictionary, else default.(如果字典中存在此key值则返回key值对应的value值,如果key不存在则返回默认值,默认值为None)
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
key_dict2 = data_dict2.get(3)
print(key_dict2)
print(data_dict2.get(1))所示代码都可以获取到关键字对应的value值
.items
D.items() -> a set-like object providing a view on D's items一个类似集合的对象,提供字典的视图
这个操作会让你的字典内容更清晰的展现,key值和value值会以一个元组的形式呈现
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
print(data_dict2.items()) 结果展示
.keys
a set-like object providing a view on D's keys(以一个类似集合的对象,提供字典中所有key的视图)此操作的返回值就是以一个类似列表的对象提供所有key值
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
print(data_dict2.keys())

.pop
D.pop(k[,d]) -> v 删除指定的key并返回相应的value值,如果未找到key,则返回默认值(如果给定);否则引发key值删除错误。
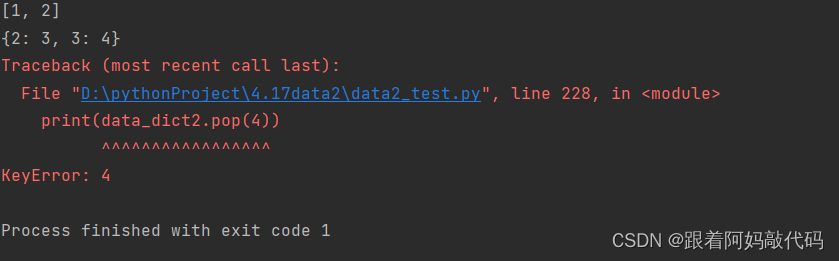
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
print(data_dict2.pop(1))
print(data_dict2)如图结果所示如果key值存在则返回key值对应的value值,如果不存在且没有设置默认值的话就会提示keyError:4 指的是4这个key值不存在
.popitem
popitem(self, /)删除并返回(key,value)对作为两个数值的一个元组。此操作默认从最后一个元素。
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
print(data_dict2.popitem())
print(data_dict2)
print(data_dict2.popitem())
print(data_dict2)通过结果不难看出

.setdefault
setdefault(self, key, default=None, /)如果 key 不在字典中,则插入的key值和对应的value值为默认值。如果键在字典中,则返回键的值,否则为默认值。
根据·一个例子会更好的理解
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
print(data_dict2.setdefault(1, False))
print(data_dict2.setdefault(4, 5))
print(data_dict2)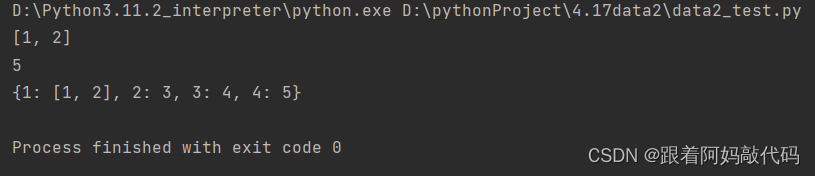
.updata
D.update([E, ]**F) -> None.updata就是更新的意思,后面要跟一个可迭代对象或者一个字典,进行这歌操作中,如果遇到原字典没有的key:value值则添加,遇到有的key:value值则进行重新赋值。
此操作会产生一个None的返回值,但其操作是直接在原字典上进行的哦
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
data_dict3 = {4: 5, 5: 6, 1: 2}
data_dict2.update(data_dict3)
print(data_dict2)如图所示就很显而易见了
.values
D.values() -> an object providing a view on D's values(为字典中的val值通过一个类似集合的形式展示出来)
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
print(data_dict2.values())
拓展训练
用for循环去获取dict的key, value, (key, value)
data_dict2 = {1: [1, 2], 2: 3, 3: 4}
# 获取key, 和value的值
for key, value in data_dict2.items():
print(key, value)
# 获取key的值
for key in data_dict2.keys():
print(key)
# 获取value的值
for value in data_dict2.values():
print(value)
用for循环获取列表的下标以及对应的数值
引入一个操作
enumerate(object)枚举,返回枚举对象,object需要为可迭代对象,通常搭配for循环来使用更加方便
# 获取列表的下标以及下标对应的值
list_data2 = ["a", "b", "c", "d", "e"]
for i in enumerate(list_data2):
print(i)
















 647
647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









