






一.源码块
以下每个代码块都是.ipynb文件的单元格部分,将每个代码块放入自己新建的ipynb文件中依次运行即可
from docx import Document
# 读取word中表格,处理成表头加行的形式
def read_table_from_word(file_path):
all_rows = []
doc = Document(file_path)
for i, table in enumerate(doc.tables):
for row in table.rows:
cells_text = [cell.text.replace('\n', '') for cell in row.cells]
all_rows.append(cells_text)
new_all_rows=[]
i = 0
# 合并跨页的表格行
while i<len(all_rows):
if i==len(all_rows)-1:
new_all_rows.append(all_rows[i])
break
if all_rows[i+1][0]!='':
new_all_rows.append(all_rows[i])
i+=1
else:
new_all_rows.append([a+b for a, b in zip(all_rows[i],all_rows[i+1])])
i+=2
final_rows=[]
flag = []
# 合并表头
for row in new_all_rows:
if row[0]=='序号':
flag = row
merge_now = '|'.join(flag)+'\n' + '|'.join(row)
final_rows.append(merge_now)
return final_rowsfrom langchain_core.documents import Document as doc
import os
file_path = 'imgs/化妆品.docx'
def get_docs(file_path):
text_chunks = read_table_from_word(file_path)
file_name = os.path.basename(file_path)
# 加入元数据
docs = [doc(page_content=chunk, metadata={'source':file_name}) for chunk in text_chunks]
return docssplits = get_docs(file_path)print(splits[2].page_content)from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name='extracted_files/bge-large-zh-v1.5', model_kwargs = {'device': 'cuda:0'})
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.messages import HumanMessage
# 设置环境变量
os.environ["QIANFAN_AK"] = "" //your api key
os.environ["QIANFAN_SK"] = "" //your secret key
# 初始化聊天端点
llm = QianfanChatEndpoint(streaming=True)
vectorstore = FAISS.from_documents(splits, embeddings)retriever = vectorstore.as_retriever(search_kwargs={'k':3})recall_text = retriever.get_relevant_documents('滋润保湿面霜的产品描述')
text = ''
for i in recall_text:
text += i.page_content
text += '\n\n'print(text)prompt = '''任务目标:根据给定的知识,回答用户提出的问题。
任务要求:
1、不得脱离给定的知识进行回答。
2、如果给定的知识不包含问题的答案,请回答我不知道。
知识:
{}
用户问题:
{}
'''query = '滋润保湿面霜的产品描述'
print(llm.invoke(prompt.format(text,query)).content)下面代码是另一个实例,只有最后调用了千帆大模型的实例(llm),其余与下面代码无关
import mammoth
with open("imgs/化妆品.docx", "rb") as docx_file:
result = mammoth.convert_to_html(docx_file)
html = result.value
print(html)with open('tmp.html', 'w', encoding='utf-8') as f:
f.write(html)from langchain_text_splitters import HTMLSectionSplitter
from langchain_text_splitters import RecursiveCharacterTextSplitter
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
("thead","tablehead"),
("tr","fenkuai"),
]
html_splitter = HTMLSectionSplitter(headers_to_split_on)
html_header_splits = html_splitter.split_text(html)
for i in html_header_splits:
print(i)
print("=======================================================")
# chunk_size = 500
# chunk_overlap = 50
# text_splitter = RecursiveCharacterTextSplitter(
# chunk_size=chunk_size, chunk_overlap=chunk_overlap
# )
# # Split
# splits = text_splitter.split_documents(html_header_splits)vectorstore = FAISS.from_documents(html_header_splits, embeddings)retriever = vectorstore.as_retriever(search_kwargs={'k':1})recall_text = retriever.get_relevant_documents('滋润保湿面霜的产品描述')
text = ''
for i in recall_text:
text += i.page_content
text += '\n\n'query = '滋润保湿面霜的产品描述'
print(llm.invoke(prompt.format(text,query)).content)二.运行前提
1.导入文件所需的包
可以新建一个ipynb文件,输入以下命令
pip install mammoth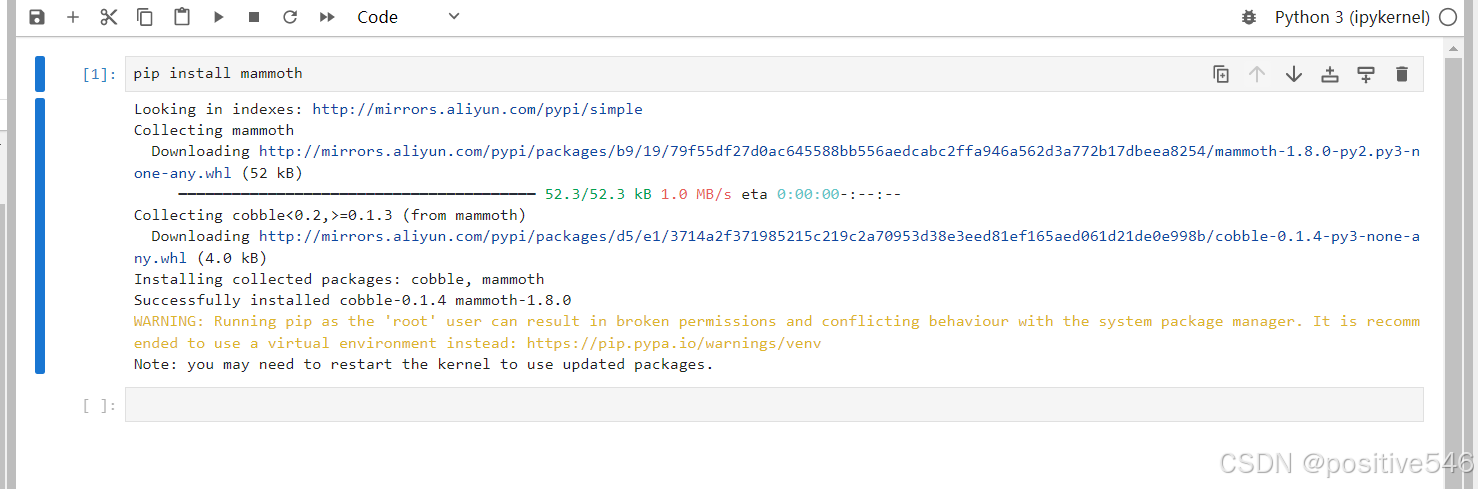
在运行期间文件导包问题仅出现过这一个,可能是我之前用过这个文件所需的包,因此没有提示让我下载其他包,若在运行期间遇到name' ' not found 之类的基本就是没导入相应包,重新导入后,重启内核即可
2.上传所需要读取的docx文件
在文件中,我使用的docx文件路径为‘imgs/化妆品.docx’,保存到了imgs目录下
这里表格自己可以随便找一个,或者直接让gpt生成一个有关化妆品的word表格,复制到word文件中上传即可
步骤:1.在主目录下新建一个文件夹,起名为imgs
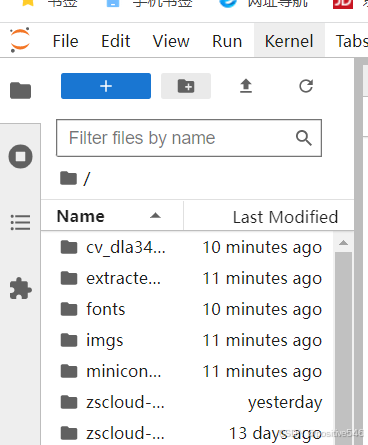
2.点击imgs目录,单击上传按钮,上传自己的docx文件即可
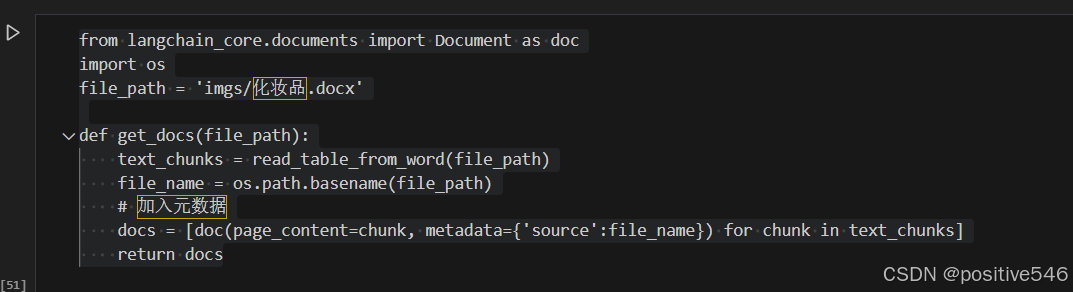
3.修改文件路径
(1)第二个代码块中的file——path修改为自己的docx路径
(2) 第五个代码块中的bge-large-zh-v1.5模型路径修改为自己的大模型路径
(3)第十二个代码块中的open打开路径修改为自己的docx路径
4.获取模型
该模型可自定义,能根据回答问题即可,若使用千帆大模型,获取自己的api key和secret key填入即可运行
步骤:
- 登录百度云搜索进入千帆大模型控制台
- 没有应用则创建应用
- 获取APIKey、SecretKey

三.代码解析
1.从一个 .docx 格式的 Word 文件中读取表格内容,并将其处理为表头加行的格式。
from docx import Document
# 读取word中表格,处理成表头加行的形式
def read_table_from_word(file_path):
all_rows = []
doc = Document(file_path)
for i, table in enumerate(doc.tables):
for row in table.rows:
cells_text = [cell.text.replace('\n', '') for cell in row.cells]
all_rows.append(cells_text)
new_all_rows=[]
i = 0
# 合并跨页的表格行
while i<len(all_rows):
if i==len(all_rows)-1:
new_all_rows.append(all_rows[i])
break
if all_rows[i+1][0]!='':
new_all_rows.append(all_rows[i])
i+=1
else:
new_all_rows.append([a+b for a, b in zip(all_rows[i],all_rows[i+1])])
i+=2
final_rows=[]
flag = []
# 合并表头
for row in new_all_rows:
if row[0]=='序号':
flag = row
merge_now = '|'.join(flag)+'\n' + '|'.join(row)
final_rows.append(merge_now)
return final_rows(1)具体步骤
1. 导入 docx 模块:
from docx import Document使用 python-docx 库来读取 .docx 格式的 Word 文件。
2. 定义 read_table_from_word 函数:
def read_table_from_word(file_path):该函数接受一个参数 file_path,表示 Word 文件的路径。
3. 读取 Word 文件中的所有表格:
doc = Document(file_path)
for i, table in enumerate(doc.tables):
for row in table.rows:
cells_text = [cell.text.replace('\n', '') for cell in row.cells]
all_rows.append(cells_text)使用 Document(file_path) 加载 Word 文件。
遍历文件中的所有表格 (doc.tables)。
遍历每个表格的每一行 (table.rows)。
获取每一行的单元格文本,使用 replace('\n', '') 移除文本中的换行符。
将每一行的单元格文本作为一个列表 cells_text 添加到 all_rows 列表中。
4. 合并跨页的表格行:
new_all_rows=[]
i = 0
while i<len(all_rows):
if i==len(all_rows)-1:
new_all_rows.append(all_rows[i])
break
if all_rows[i+1][0]!='':
new_all_rows.append(all_rows[i])
i+=1
else:
new_all_rows.append([a+b for a, b in zip(all_rows[i],all_rows[i+1])])
i+=2new_all_rows 用于存储处理后的行数据。
循环遍历 all_rows 中的每一行,处理可能存在跨页的表格(即表格的某一行分布在不同页面中,后续行的第一个单元格为空)。
如果下一行的第一个单元格非空,则直接将当前行添加到 new_all_rows,并移动到下一行。
如果下一行的第一个单元格为空,表示当前行和下一行属于同一行,使用 zip 函数将两行合并(逐个单元格拼接),然后跳过下一行(i+=2)。
5. 合并表头:
final_rows=[]
flag = []
for row in new_all_rows:
if row[0]=='序号':
flag = row
merge_now = '|'.join(flag)+'\n' + '|'.join(row)
final_rows.append(merge_now)final_rows 用于存储最终格式化后的表格数据。
flag 用于保存表头行。
遍历 new_all_rows 中的每一行:
如果当前行的第一个单元格内容为 '序号'(通常是表头的标志),则将该行赋值给 flag。
使用 '|' 符号将 flag(表头)和当前行的数据合并,并将其作为字符串添加到 final_rows 中。
6. 返回最终的表格行:
return final_rows最终返回的 final_rows 是一个包含表头和每一行内容的列表,每行内容通过 '|' 分隔。
(2)总结
该代码的主要功能是:
- 从 Word 文档中提取表格内容。
- 处理表格可能出现的跨页问题,将跨页的表格行合并为一行。
- 将表格转换为表头加每行的格式,其中表头与每行内容之间通过
'|'符号分隔。
此代码的输出是一个包含合并后的表格数据的列表,进一步用于分析。
2.从指定路径的 .docx 文件中提取表格内容,将其转换为 Document 对象,并为每个提取的内容添加元数据。
(1)具体步骤
1. 导入模块:
from langchain_core.documents import Document as doc
import osDocument 类从 langchain_core.documents 模块导入,并给它起了一个别名 doc,便于后续使用。
os 模块用于处理文件路径相关操作。
2. 定义 get_docs 函数:
def get_docs(file_path):get_docs 是一个函数,接受一个参数 file_path,表示 .docx 文件的路径。
3. 提取表格内容:
text_chunks = read_table_from_word(file_path)这行代码调用了 read_table_from_word 函数
read_table_from_word(file_path) 将 .docx 文件中的表格数据提取出来,返回一个包含表头和每一行内容的列表,每行内容通过 '|' 分隔
4. 获取文件名:
file_name = os.path.basename(file_path)使用 os.path.basename(file_path) 获取 .docx 文件的文件名,不包括文件路径。例如,如果文件路径是 'imgs/化妆品.docx',则 file_name 将是 '化妆品.docx'。
5. 创建 Document 对象:
docs = [doc(page_content=chunk, metadata={'source': file_name}) for chunk in text_chunks]这行代码使用了列表推导式,遍历从 .docx 文件中提取的每一块文本 text_chunks。
每一块文本(即每一行或表格的一个部分)都被封装成一个 Document 对象,page_content 用来存储表格内容,metadata 是一个字典,用来存储文件的元数据。这里 metadata 包含了一个键 'source',它的值是文件名,即 '化妆品.docx'。
6. 返回结果:
return docs最后,函数返回一个 docs 列表,这个列表包含了多个 Document 对象,每个对象代表了从 .docx 文件中提取的一部分内容,并且附带了元数据。
(2)总结
-
提取文件内容:
get_docs函数从给定路径的.docx文件中提取表格数据,并将其分割成多个文本块(text_chunks)。 -
封装为 Document 对象:每个文本块被封装为
Document对象,并附带元数据,其中元数据包含了源文件的名称。 -
返回 Document 列表:返回一个包含所有
Document对象的列表。
3,4.调用get_docs函数,并打印测试page_content的结果
这里我仅仅测试了第二行的数据
splits = get_docs(file_path)
print(splits[2].page_content)输出结果:
5.加载模型
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name='extracted_files/bge-large-zh-v1.5', model_kwargs = {'device': 'cuda:0'})
(1)引入FAISS向量数据库的包
(2)引入HuggingFaceEmbeddings包,并加载所需的大模型(bge-large-zh-v1.5),实例化 embeddings 对象
6.配置和使用 langchain聊天模型和向量数据库进行自然语言处理任务
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.messages import HumanMessage
# 设置环境变量
os.environ["QIANFAN_AK"] = "" //输入自己的api key
os.environ["QIANFAN_SK"] = "" //输入自己的secret key
# 初始化聊天端点
llm = QianfanChatEndpoint(streaming=True)
vectorstore = FAISS.from_documents(splits, embeddings)- 通过设置环境变量来配置聊天模型的 API 密钥。
- 初始化一个聊天模型端点
QianfanChatEndpoint,并通过流式传输进行实时对话。 - 使用
FAISS向量数据库来存储和检索文本嵌入,用于后续实现文本相似度信息检索任务。
7. 将一个已经创建好的向量数据库 (vectorstore) 转换为一个检索器(retriever),并配置该检索器的搜索参数。
retriever = vectorstore.as_retriever(search_kwargs={'k':3})将向量数据库转换为一个可以执行检索操作的对象,k=3 表示每次检索时返回前 3 个最相关的文档或数据项。这个检索器是执行基于语义的搜索的关键组件,能够从向量化的文本数据库中找到与用户查询相关的信息。
8,9使用检索器从向量数据库中获取与查询“滋润保湿面霜的产品描述”相关的文档,并将检索到的文档内容拼接成一个完整的文本。
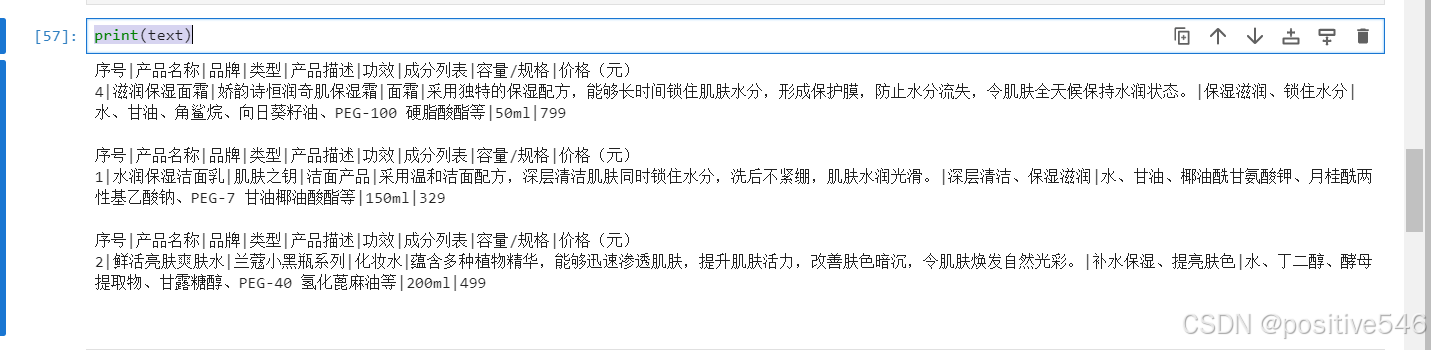
recall_text = retriever.get_relevant_documents('滋润保湿面霜的产品描述')
text = ''
for i in recall_text:
text += i.page_content
text += '\n\n'
print(text)-
recall_text = retriever.get_relevant_documents('滋润保湿面霜的产品描述'):- 这行代码调用了
retriever对象的get_relevant_documents()方法,传入查询字符串“滋润保湿面霜的产品描述”。 get_relevant_documents()方法会根据给定的查询,从数据库中返回与之最相关的文档列表。返回值recall_text是一个包含3个文档对象的列表(因为之前设置了参数为3)。- 每个文档对象通常会包含诸如
page_content(文档的实际内容)、metadata(如文档的元数据)等信息。 -
设置一个text变量,初始化为空字符串,循环拼接每个文档对象的
page_content值,并拼接两个换行符在后面
- 这行代码调用了
输出结果:
10,11根据给定的知识内容,利用自然语言模型回答用户提出的问题
prompt = '''任务目标:根据给定的知识,回答用户提出的问题。
任务要求:
1、不得脱离给定的知识进行回答。
2、如果给定的知识不包含问题的答案,请回答我不知道。
知识:
{}
用户问题:
{}
'''
query = '滋润保湿面霜的产品描述'
print(llm.invoke(prompt.format(text,query)).content)输出结果;
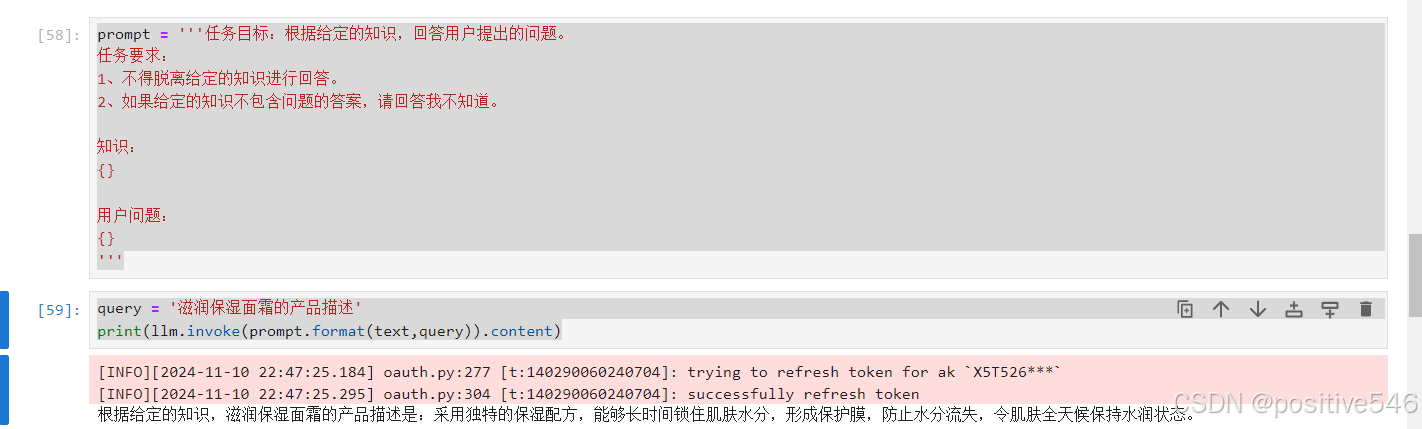
可以看到回答还是可以的
注:下面代码是另一个实例,与前面代码无关(只有调用千帆大模型的llm实例在最后会用到,其余无关),是对文本进行分块操作,并根据这个分完块的知识库进行问答:
将表格文本内容转成html标签格式内容进行分块并根据大模型回答问题
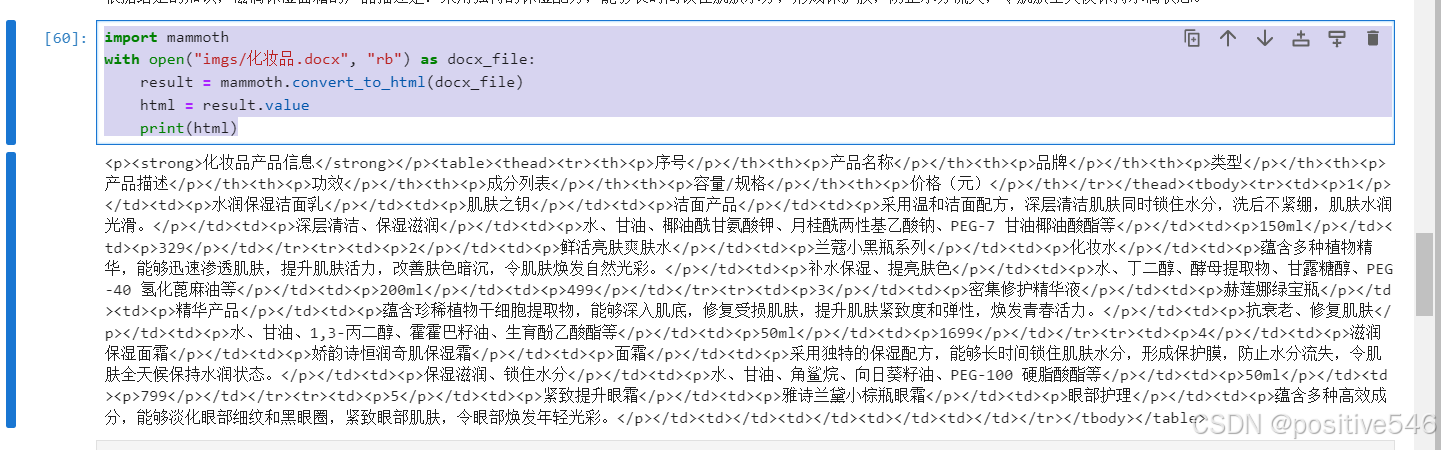
12.将 Word 文档转换为 HTML
import mammoth
with open("imgs/化妆品.docx", "rb") as docx_file:
result = mammoth.convert_to_html(docx_file)
html = result.value
print(html)- 读取
.docx文件:打开指定路径的 Word 文档化妆品.docx。 - 转换为 HTML:通过
mammoth.convert_to_html()将 Word 文件的内容转换为 HTML 格式。这个函数尽量保留文档的结构,比如标题、段落、列表等,而忽略复杂的样式(如字体、颜色等),目的是生成干净的、易于阅读的 HTML。 - 获取转换结果:通过
result.value获取转换后的 HTML 内容。 - 打印 HTML:最后,输出生成的 HTML 代码,用于下一步的网页呈现、存储
输出结果:
 13.写入html文件
13.写入html文件
with open('tmp.html', 'w', encoding='utf-8') as f:
f.write(html)将提取的html内容写入到一个html文件中,并保存到tmp.html文件中,运行后即可在自己的主目录下看到,方便查看

可以看到格式还是比较完整的
14.对文档内容进行标签分块操作
from langchain_text_splitters import HTMLSectionSplitter
from langchain_text_splitters import RecursiveCharacterTextSplitter
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
("thead","tablehead"),
("tr","fenkuai"),
]
html_splitter = HTMLSectionSplitter(headers_to_split_on)
html_header_splits = html_splitter.split_text(html)
for i in html_header_splits:
print(i)
print("=======================================================")
# chunk_size = 500
# chunk_overlap = 50
# text_splitter = RecursiveCharacterTextSplitter(
# chunk_size=chunk_size, chunk_overlap=chunk_overlap
# )
# # Split
# splits = text_splitter.split_documents(html_header_splits)这里我采用了通过h1,h2,h3,thead,tr标签进行分块,即会筛选文档里的上述标签进行分块
部分分块结果如下:

将表头分为一块,将每一行的内容分为一块
15,16,17实现基于文本的高效检索,通过 FAISS 和向量嵌入来检索最相关的文档,并将结果合并展示
vectorstore = FAISS.from_documents(html_header_splits, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={'k':1})
recall_text = retriever.get_relevant_documents('滋润保湿面霜的产品描述')
text = ''
for i in recall_text:
text += i.page_content
text += '\n\n'与前面类似:
- 构建 FAISS 向量存储:通过
FAISS.from_documents(),根据预先处理的文档和嵌入模型创建一个 FAISS 向量存储。 - 创建检索器:将向量存储转换为检索器,使用
k=1来指定每次查询返回最相关的一个文档(这里也可以根据自己的需要设置需要返回几个最相关的文档)。 - 检索相关文档:使用
get_relevant_documents()方法,查询'滋润保湿面霜的产品描述',从 FAISS 向量存储中返回相关文档。 - 处理检索结果:遍历相关文档,提取其
page_content并拼接成一个最终的文本text,该文本包含了查询的相关信息。
18.根据知识库和问题进行问答
query = '滋润保湿面霜的产品描述'
print(llm.invoke(prompt.format(text,query)).content)调用千帆大模型实例llm,大模型根据问题和提供的知识库进行回答
输出结果:

可以看到大模型检索出了这一个块的内容,并进行更贴切的回答,相较于文本不分块回答应该会更好

















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









