






DeepSeek-R1已经发布超过一周,我也第一时间发布了关于基于vLLM部署DeepSeek-R1以及DeepSeek-R1-Distill-Qwen-32B的相关文章。我的文章主要介绍了在构建企业RAG系统时,如何将DeepSeek-R1作为大模型模块进行部署,企业在业务发展中使用这一方案完全足够。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
然而,我发现将AI集成到个人设备、甚至口袋的需求正在迅速增长。因此,除了编写DeepSeek-R1操作手册外,这几天我还深入探索了不同参数模型的部署方式,总结出一套适合个人与企业同时使用的部署方案。
关于基于DeepSeek-R1蒸馏的六款子模型是否适合个人部署,我特别关注了其中一些模型文件非常庞大的版本,比如DeepSeek-R1-Distill-Qwen-32B和DeepSeek-R1-Distill-Llama-70B。为此,我专门向DeepSeek进行了咨询。
我的提问是:
个人部署DeepSeek-R1-Distill-Qwen-32B合适吗?如果你觉得合适,你能给出一个特别特别的原因吗?使用大白话回答
DeepSeek的回答:
合适! 但有个特别特别简单的原因:这模型是个“学霸精简版”——就像你让一个考满分的学霸把课本重点全总结成小抄,虽然它脑子还是很大(32B参数),但运行起来比原版省劲,适合个人用电脑硬刚,勉强能跑起来!(当然,显卡最好是3090/4090级别,否则还是卡成PPT)
行吧,那我们今天就来讲讲个人部署DeepSeek-R1蒸馏模型的操作方法。
了解模型的大小
DeepSeek-R1模型参数:671B(6710亿),模型大小:约720G。
DeepSeek-R1-Distill-Qwen-1.5B模型参数1.5B(15亿),模型大小:约4G
DeepSeek-R1-Distill-Qwen-7B模型参数7B (70亿),模型大小:约15G
DeepSeek-R1-Distill-Llama-8B模型参数8B(80亿),模型大小:约16G
DeepSeek-R1-Distill-Qwen-14B模型参数14B(140亿),模型大小:约30G
DeepSeek-R1-Distill-Qwen-32B模型参数32B(320亿),模型大小:约75G
DeepSeek-R1-Distill-Llama-70B模型参数70B(70亿),模型大小:约140G
这些模型的原始大小如上所示,其中DeepSeek-R1和DeepSeek-R1-Distill-Llama-70B显然不适合在个人电脑上部署,而其余五个模型则完全可以在个人电脑上进行部署。
模型运行框架的选择
目前市面上有许多开源模型框架可供选择,但大多数框架主要面向企业级部署,通常通过各种模型加速技术提升性能。
DeepSeek-R1官方推荐的几款框架包括:vLLM、SGLang、TensorRT-LLM等。
那么,是否有适合个人部署的框架呢?
Ollama是一个开源框架,专为简化在本地机器上部署和运行大型语言模型(LLM)而设计。
特点如下:
易于使用:提供简洁的命令行界面和类似OpenAI的API,便于用户轻松管理和运行大型语言模型。
跨平台支持:支持MacOS、Linux和Windows(预览版)系统,并提供Docker镜像,方便在不同环境下部署。
模型管理:支持多种大型语言模型,如Llama、Mistral等,用户可从模型仓库下载或自行导入模型。
资源高效:优化资源占用,支持GPU加速,提升模型运行效率。
可扩展性:支持同时加载多个模型和处理多个请求,可与Web界面结合使用,方便构建应用程序。
Ollama的另一个显著优势是,它原生支持DeepSeek-R1的所有模型。同时,Ollama通过量化技术和剪枝技术对DeepSeek-R1的模型进行了优化,显著减小了模型的体积,从而更加适合个人部署使用。
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

采用Ollama实现个人部署
Winsows环境部署
1、Ollama的下载与安装
地址:https://ollama.com/download

选择与自己操作系统兼容的Ollama应用进行安装,具体的安装步骤这里不再赘述。不过,需要注意的是,Ollama的安装盘最好有50GB以上的可用空间。
2、DeepSeek-R1模型的选择
地址:https://ollama.com/
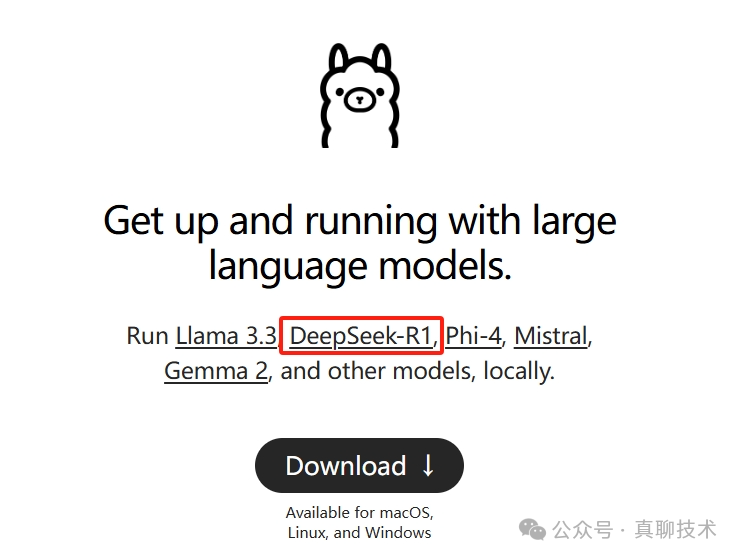
在官网主页可以看到DeepSeek-R1在醒目的位置,点击后就进入下载页面。
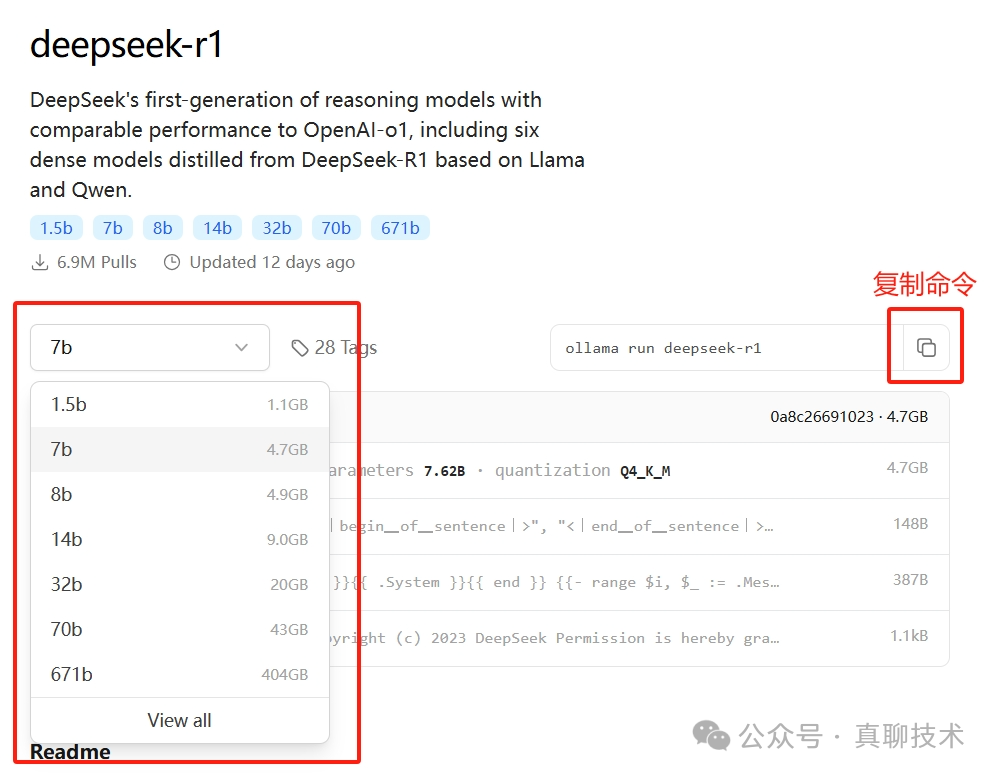
在左侧的下拉列表中,可以选择不同参数的模型,并查看每个模型的大小,这些大小都是经过优化后的。例如:32B模型的大小为20GB。个人用户可以根据自己电脑的配置选择合适的模型进行部署。选择好模型后,点击右侧的“复制”按钮,即可复制下载模型和运行模型的命令。
例如:选择7B模型,命令如下
ollama run deepseek-r1:7b
3、下载模型并运行
搜索框中输入:cmd,打开命令提示符窗口,输入刚才拷贝的命令。

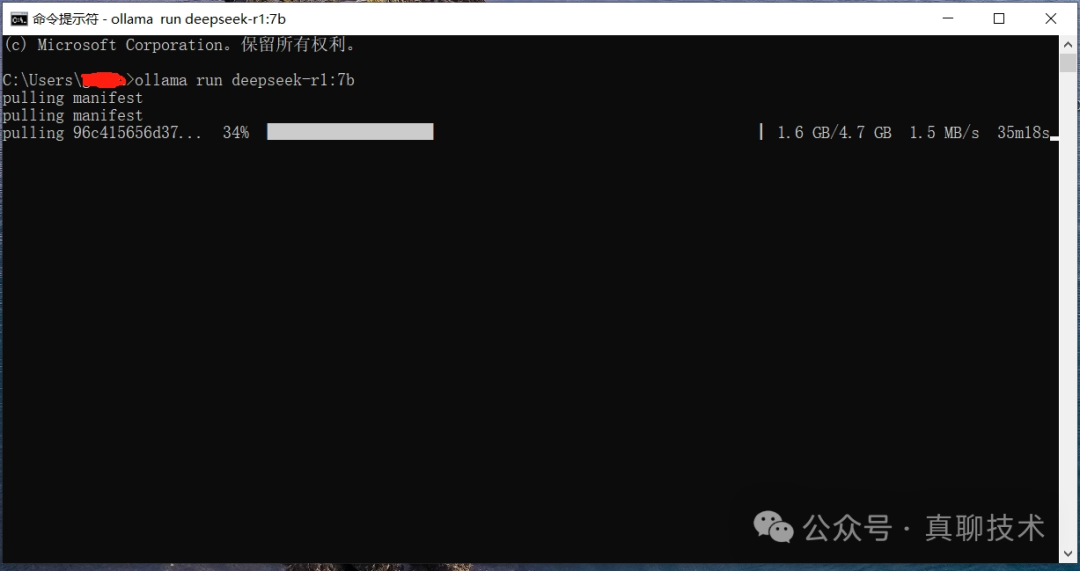
模型下载完并运行后,就可以进行对话。
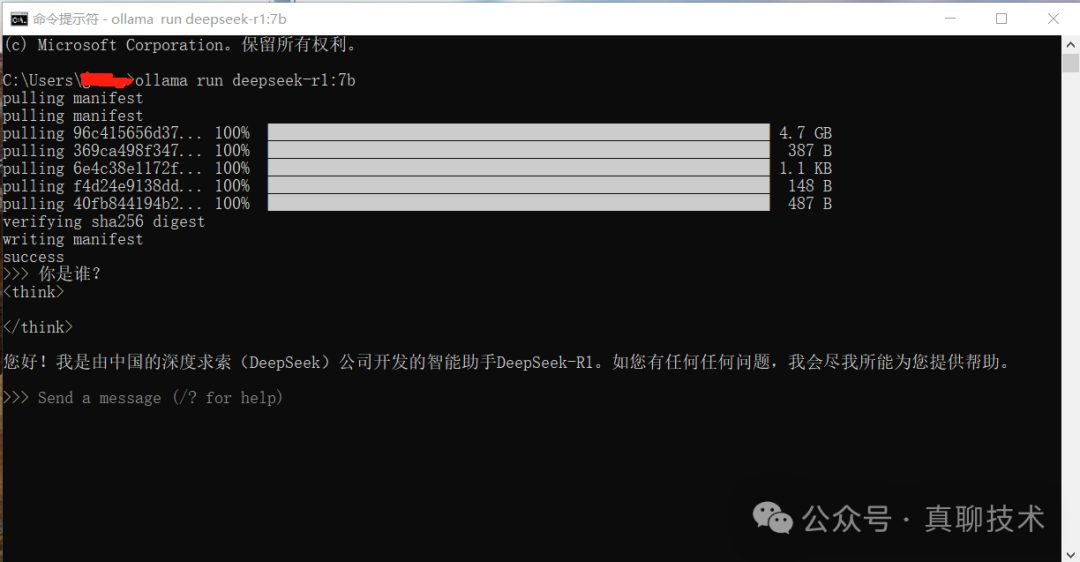
使用Ollama部署时,32B模型使用3090、4090的卡都可以顺利完成部署。
Linux环境部署
1、Ollama的下载与安装
地址:https://ollama.com/download/linux

点击复制命令,到linux界面执行,安装Ollama。
安装完毕后,执行以下命令:可以看到ollama的启动日志。
ollama serve
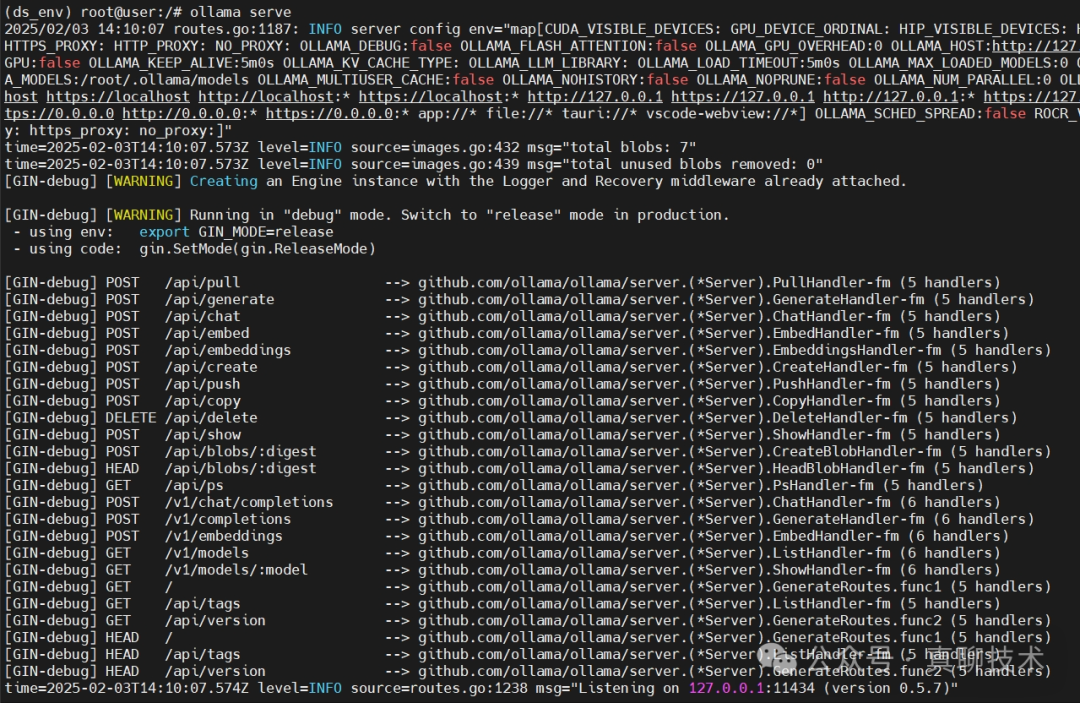
2、DeepSeek-R1模型的选择
参考Windows环境部署中的模型选择,选择一个大模型,这里我们以32B为例,32B后复制命令。
3、下载模型并运行
执行以下命令:模型下载并运行。
ollama run deepseek-r1:32b
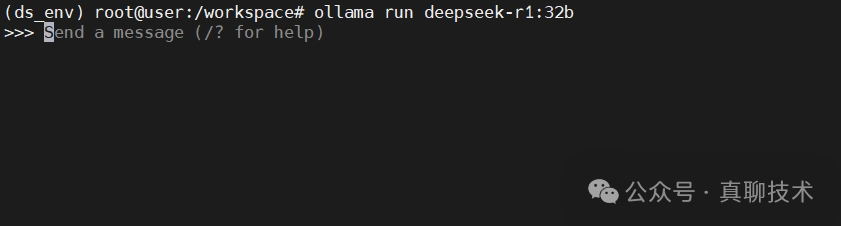
注:我这里已经下载安装过,所以执行命令后,直接就进入了聊天界面。
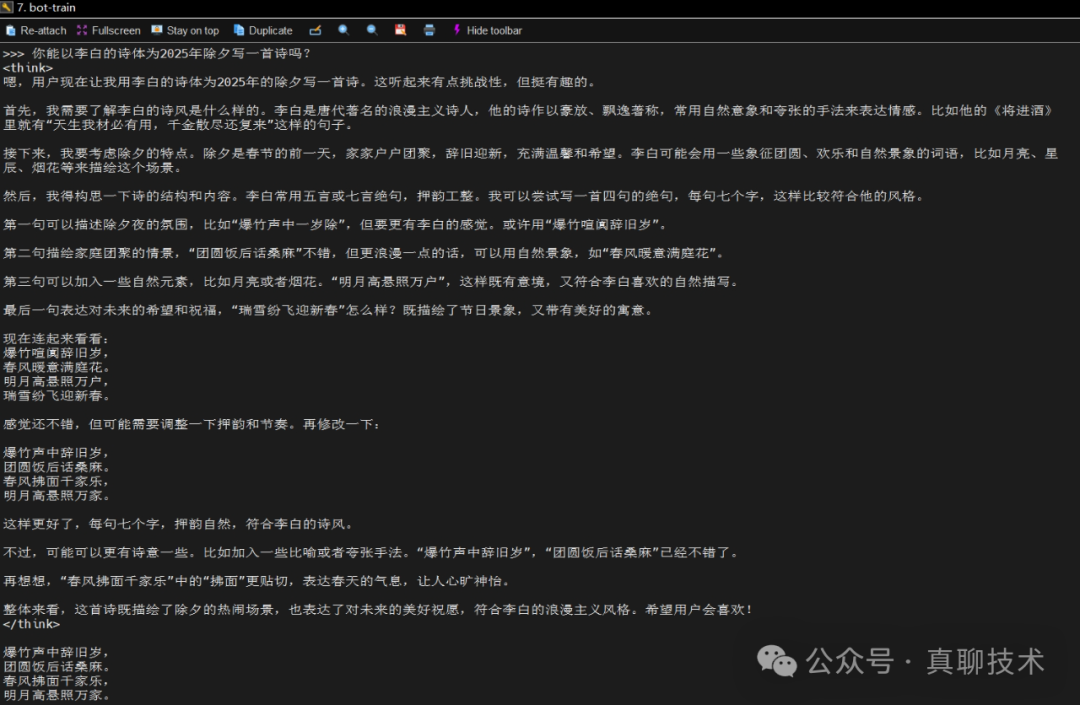
我让它用李白的诗体为2025年除夕写一首诗,它经过思考,写了一首7言绝句,你觉得怎么样?
爆竹声中辞旧岁,
团圆饭后话桑麻。
春风拂面千家乐,
明月高悬照万家。
使用Open WebUI提升对话体验
1、Open WebUI的下载与安装
地址:https://github.com/open-webui/open-webui
找到“If Ollama is on your computer, use this command:”提示语,并复制命令。
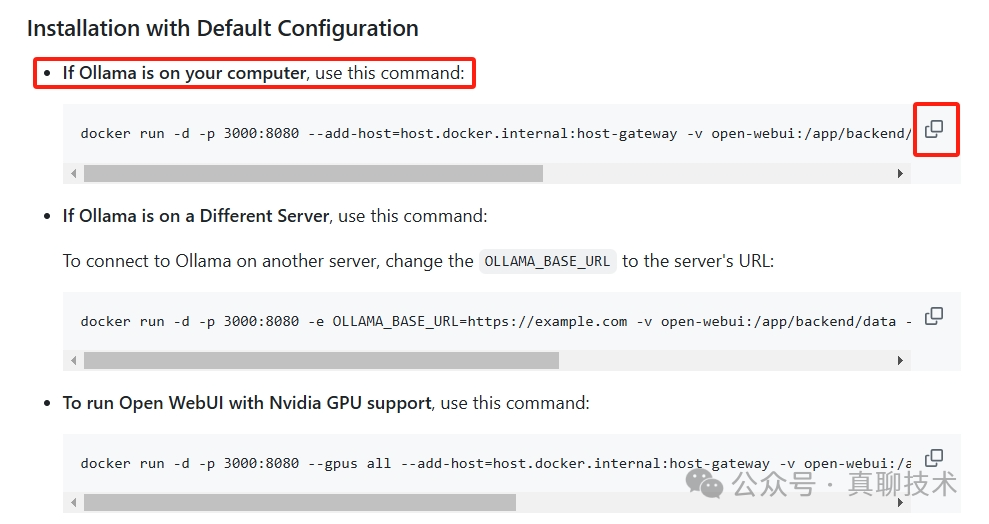
注:我们采用Docker环境部署,环境请自行安装。
将复制的命令,在一个新的命令提示符窗口下打开。
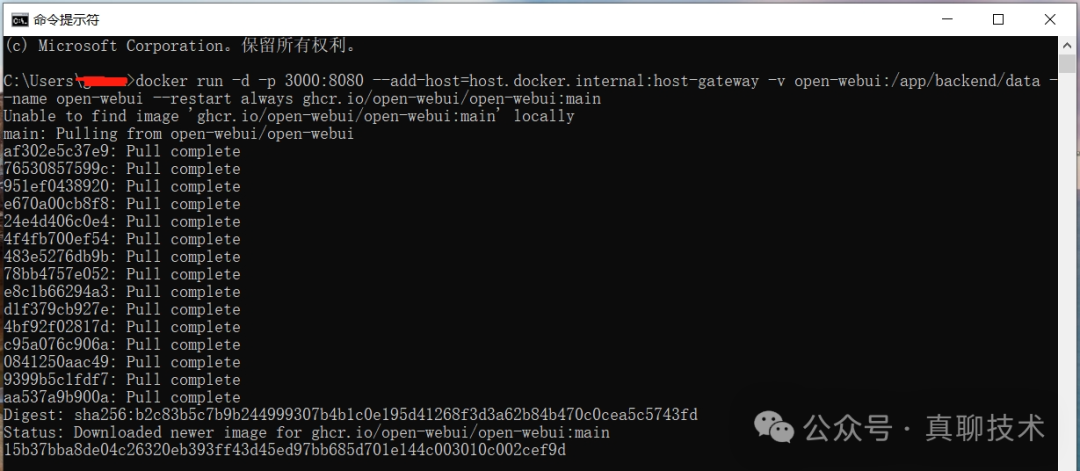
安装完成后可以在Docker列表中看到Open WebUI的条目。

2、Open WebUI+DeepSeek-R1
Open WebUI地址:http://localhost:3000
拷贝地址在浏览器中打开,或是点击Docker Open WebUI条目中红框圈住的部分。

打开后的Open WebUI界面如下:
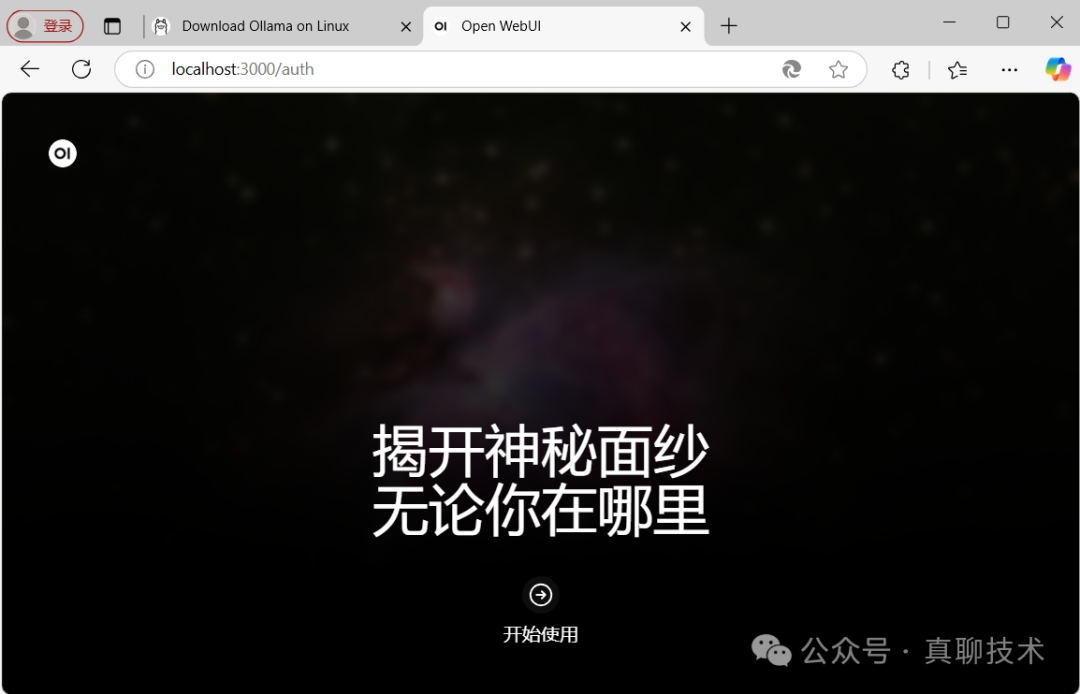
点击“开始使用”,完成管理员账号的创建,就可以进入聊天界面。
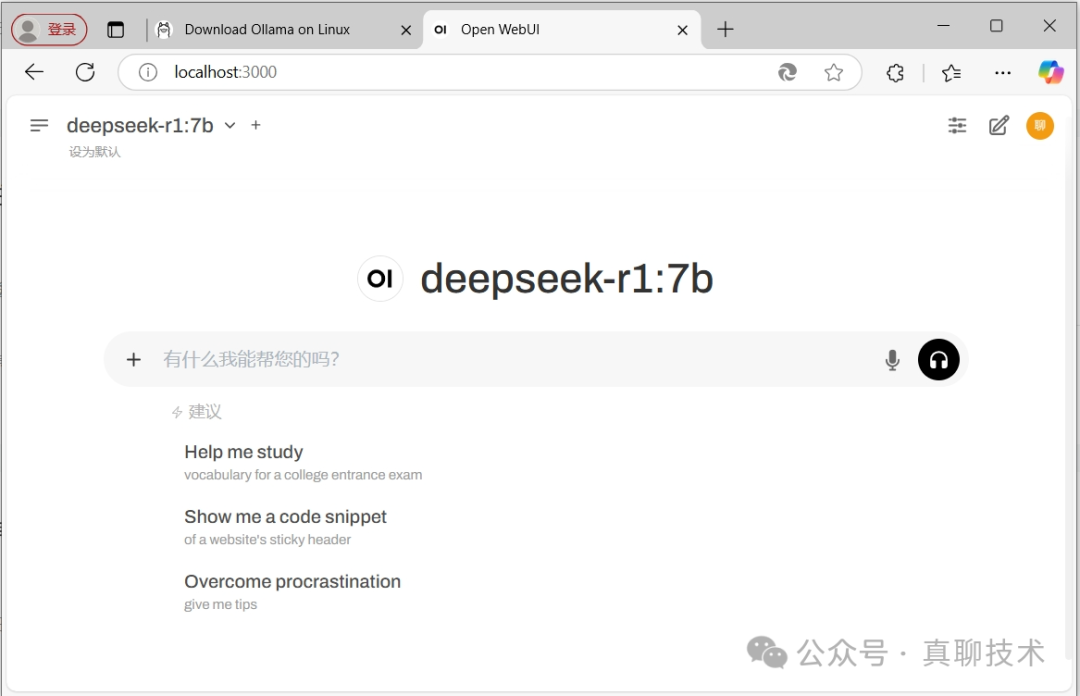
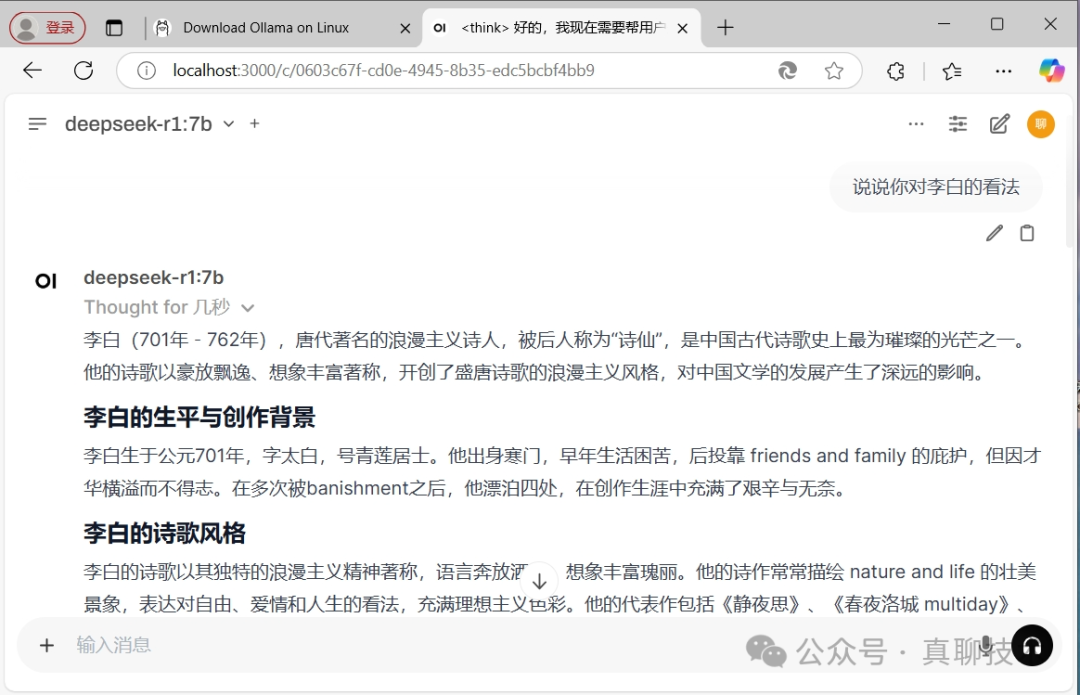
我让它谈以下对李白的看法,它思考一会,写了大概有1000多字,看来它十分喜欢李白,最后对李白的评价也是相当的好。
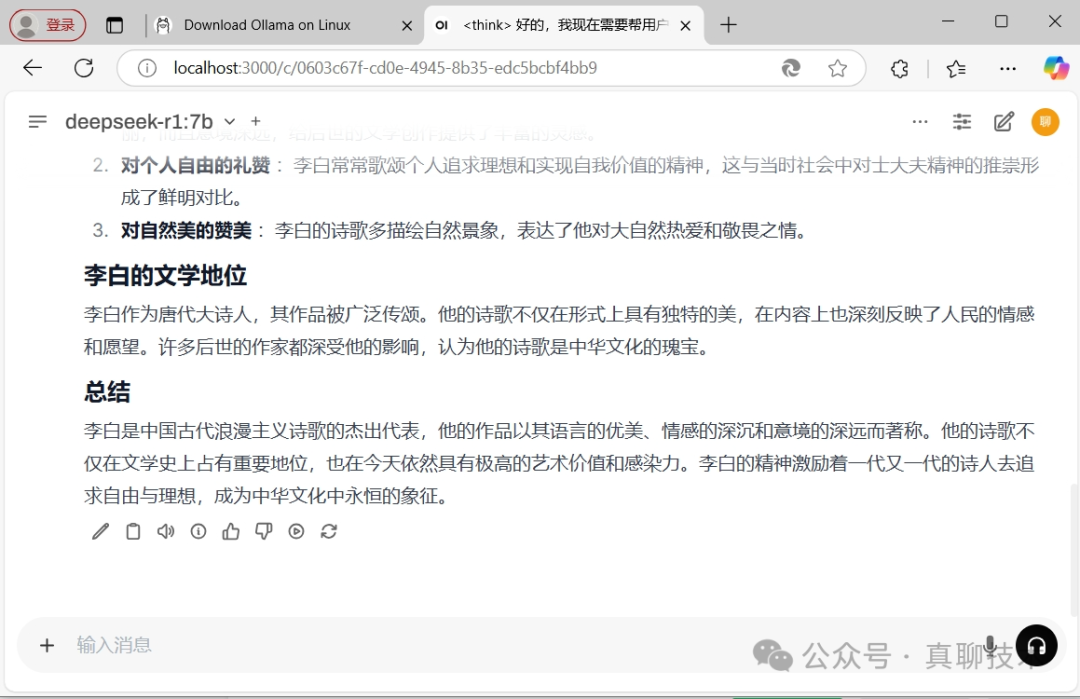
个人部署DeepSeek-R1总结
个人在本地部署时,可以根据自己的电脑配置选择不同参数的模型。如果你的电脑配有GPU显卡,且显存约为22GB,可以选择32B模型。该模型在各项指标上可与ChatGPT-o1-mini相媲美,具备完整的思考与推理过程,除了性能与DeepSeek官网差一些,其它体验相差无几。
如果你有阿里云、百度云等提供GPU的云服务器,也可以选择在云端部署大型模型,并在个人电脑上安装Open WebUI配置云端模型,这样的使用体验将是最佳的,同时还能确保个人信息安全。
采用vLLM实现企业部署
DeepSeek-R1的企业部署将在节后迎来高峰期,许多企业已经开始积极筹备。如果企业计划在节后更换现有的大模型部署,DeepSeek-R1是一个值得参考的选择。
企业可以根据自身业务需求和成本考虑部署不同参数的DeepSeek-R1模型。通常,企业都会拥有自己的用户交互系统。DeepSeek-R1的不同模型启动后,会自动启用支持OpenAI协议的接口,企业可以直接通过标准的OpenAI API方式进行接入。
执行以下命令:可以看到调用效果。
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{` `"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",` `"messages": [` `{"role": "system", "content": "You are DeepSeek-R1-7B. You are a helpful assistant."},` `{"role": "user", "content": "请介绍一下你自己"}` `],` `"temperature": 0.6,` `"top_p": 0.8,` `"repetition_penalty": 1.05,` `"max_tokens": 512``}'
模型回答:
{` `"id": "chatcmpl-711471f00c9c40f6b4cdd66a9995d843",` `"object": "chat.completion",` `"created": 1738595207,` `"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",` `"choices": [{` `"index": 0,` `"message": {` `"role": "assistant",` `"reasoning_content": null,` `"content": "<think>\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1-7B。如您有任何任何问题,我会尽我所能为您提供帮助。\n</think>\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1-7B。如您有任何任何问题,我会尽我所能为您提供帮助。",` `"tool_calls": []` `},` `"logprobs": null,` `"finish_reason": "stop",` `"stop_reason": null` `}],` `"usage": {` `"prompt_tokens": 22,` `"total_tokens": 103,` `"completion_tokens": 81,` `"prompt_tokens_details": null` `},` `"prompt_logprobs": null``}
写在最后
DeepSeek-R1已经将AI大模型带入了寻常百姓家,为AI的普及做出了巨大贡献。最后,我用DeepSeek-R1创作的一首诗来结束今天的分享。
我的提示词:
请你用DeepSeek-R1已经让AI大模型进入寻常百姓家为背景,仿刘禹锡的诗体,写一首属于你的诗句。
《智咏》
——DeepSeek-R1智启万门
寻常巷陌无寒暑,
一屏尽览古今情。
莫道云端高难问,
智能入世万象新。
千帆竞发星河渡,
万户轻吟数据鸣。
且看AI春风里,
笑与人间共潮生。
注:笔者以刘禹锡"沉舟侧畔千帆过"的变革视角切入,用"巷陌无寒暑"喻指AI普惠带来的生活质变,"云端高难问"化用"白云在青天"的古典意象,转以"数据鸣"赋予科技人文温度。末句"共潮生"既呼应刘禹锡"潮打空城寂寞回"的时空哲思,更展现智能时代人机共生的新境界。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 7369
7369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









