






一,名词解释
1,局部算子是指在某个点的取值仅受到该点周围一定范围内的数值影响,而不会受到其他位置上的数值影响。
2,径向窗如图

3,劈裂是指绘画中在颜料层之间、在颜料表面薄层和底色之间或在底色和基底之间的分离现象。
4,backbone(主干网络)大多时候指的是提取特征的网络,其作用就是提取图片中的信息,共后面的网络使用。
5,PRN(Region Proposal Network,区域生成网络),通俗讲是“筛选出可能会有目标的框”。
6,token,是文本中的最小单位。在英文中,一个 token 可以是一个单词,也可以是一个标点符号。在中文中,通常以字或词作为 token。
7,键和值:字典是由许多对相互之间有联系的元素组成,每一对元素都包含一个键(key)和一个值(value)。这种元素称为键值对,一般记作键:值 (key:value)。key 是索引,value 是数,key 和 value 之间用“:”分隔。key 必须是唯一的,value 可以取任何数据类型,但 key 只能使用 字符串、数字或元组
二,特点
1,提出了SphereFormer来直接将密集的近点信息聚合到稀疏的远点。它平滑地增加了接受野,并有助于提高稀疏距离点的性能。
2,设计了自关注的径向窗,将空间划分为多个不重叠的窄窗和长窗,克服了分离问题,平滑而显著地扩大了接收野,显著提高了稀疏距离点的性能。
3,为了适应窄窗和长窗,开发了相对位置编码的指数分裂。为了让不同位置的点对局部和全局信息的处理有所不同,提出了动态特征选择来改进。
4,为了适应变稀疏点分布,提出了将远程信息直接聚合到单个算子上的新思路。
5,对于每个token,不仅包含径向上下文信息,还包含本地邻居通信。具体而言,输入特征被投影为查询、键和值特征。前一半用于径向窗口自注意,其余的用于立方窗口自注意。之后,将这两个特征连接起来,然后线性投影到最终输出z进行特征融合。它使不同的点能够动态地选择局部或全局特征。
6,对于语义分割,采用编码器-解码器结构,并遵循U-Net[49]将细粒度的编码器特征拼接到解码器中,建议的模块在每个编码阶段的末尾堆叠。对于目标检测,采用CenterPoint[79]作为基线模型,建议的模块堆叠在第二和第三阶段的末尾。
三,环境配置
1,pip下载慢,须更换下载网址:
- 豆瓣 https://pypi.douban.com/simple/
- 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
- 阿里云 https://mirrors.aliyun.com/pypi/simple/
- 北外https://mirrors.bfsu.edu.cn
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip config set install.trusted-host mirrors.aliyun.com2,将ubuntu从WSL1转换到WSL2,详见:
3,报错RuntimeError: CUDA error: invalid device ordinal
翻译:CUDA版本不兼容
首先,在命令行输入nvidia-smi,查看系统CUDA版本
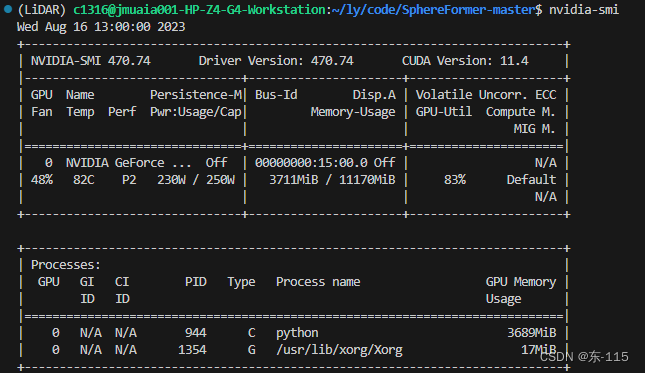
如图版本为CUDA11.4。再输入指令conda list查看环境所安装的配置版本(cu117代表CUDA版本为11.7,cp37代表python版本为3.7.x)
注意:pytorch版本必须和torchvision,torchaudio版本对应(torchvision版本为torch版本减去0.9.0,torchaudio版本为torch版本减去1.0.0,如torch-1.8.0+cu111对应torchvision-0.9.0+cu111,torchaudio-0.8.0)
各版本torch下载网址 : https://download.pytorch.org/whl/torch_stable.html
4,Segmentation fault (core dumped)
翻译:分段错误(核心转储)
解决方法:
1,检查源文件是否完整,可能在解压中缺失。或检查代码是否访问空指针,是否访问越界数组,破坏常变量等
2,输入ulimit -a检查core file size是否受限(为0,则被限制)
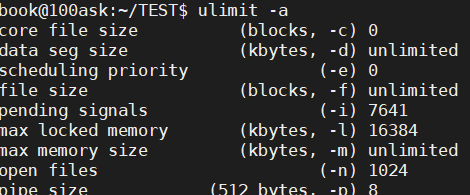
之后可输入ulimit -c unlimited解除该限制,再次运行程序后输入命令行ll(两个l)进行查看
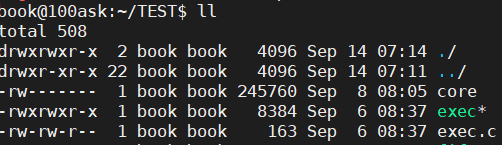
3,利用gdb调试:gdb corefile <core文件名>,如

问题为:Program terminated with signal SIGSEGV, Segmentation fault。
- SIGBUS(Bus error)意味着指针所对应的地址是有效地址,但总线不能正常使用该指针。通常是未对齐的数据访问所致。
- SIGSEGV(Segment fault)意味着指针所对应的地址是无效地址,没有物理内存对应该地址。
如定位错误,gdb打印消息如下:0x00000000 in ?? ()。则基本可以确定是踩内存(访问了本不应该预期内的内存,因而导致出错)。
可能出现的场景:
1、访问越界数组
2、访问已经被释放(被free)掉的内存
5,cannot import name ‘builder‘ from ‘google.protobuf.internal‘
翻译:导入错误:无法从“google.protobuf.internal”导入名称“生成器”
这个问题可能是由于 Protobuf 没有正确安装,或者版本不兼容导致的。
解决办法:
升级protobuf:pip install --upgrade protobuf
6,ubuntu安装cuda11.1,详见:
https://blog.csdn.net/level_code/article/details/126398286
cuda-driver官方下载地址https://www.nvidia.cn/Download/index.aspx?lang=cn
7,gdb bt/where调试出现0x00007fa348d5c4e6 in ?? (),详见:
https://blog.csdn.net/sinat_33452383/article/details/92814882
8,ubuntu-drivers: command not found
输入sudo apt-get install ubuntu-drivers-common来安装ubuntu-drivers
9,E: Could not open lock file /var/lib/dpkg/lock-frontend - open (13: Permission denied) E: Unable to acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend), are you root?
翻译:Ubuntu 无法打开锁文件 /var/lib/dpkg/lock - open (13: 权限不够) 无法获取 dpkg 前端锁 (/var/lib/dpkg/lock-frontend)
原因:权限不够
解决:
在终端输入:sudo passwd root
然后输入两次密码
再输入:su
再输入一次密码,就完成了root提升
10,lspci: Unable to load libkmod resources: error -12
翻译:
原因:通常是因为在系统中没有正确的安装kmod库所导致的
解决:
1,确认kmod库是否已安装。在终端中运行以下命令来检查kmod是否已安装:dpkg -s kmod
如果你的系统中没有安装kmod,那么你需要使用以下命令来安装:sudo apt-get install kmod
2, 如果你已经安装了kmod库,但仍无法解决问题,那么可能是因为库文件已经被损坏。你可以尝试重新安装kmod库。操作如下:
sudo apt-get remove kmod # 卸载kmod库
sudo apt-get install kmod # 重新安装kmod库
3. 如果重新安装kmod库也无法解决问题,那么你可以考虑升级系统到最新版本。这通常会帮助你解决系统中的一些库文件问题。
sudo apt-get upgrade # 升级系统中的所有软件包到最新版本
4. 如果以上步骤仍无法解决问题,那么你可以尝试重新安装lspci程序。
sudo apt-get remove pciutils # 卸载 lspci sudo apt-get install pciutils # 重新安装lspci
11,CUDA安装成功后测试Sample的时候报错
参考:https://blog.csdn.net/qq_41481731/article/details/86658523
测试CUDA自带的Sample。
cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery
make
sudo ./deviceQuery
报错:
$ ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
cudaGetDeviceCount returned 30
-> unknown error
Result = FAIL
解决:
1,检查NVIDIA驱动是否安装好了:nvidia-smi
出现下列信息就说明没有装好:
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
2,需要注意一点,在安装CUDA的时候我们把GCC和G++降级了,现在如果想安装nvidia驱动的话就需要先把GCC和G++升级,所以执行下面语句:
sudo apt-get purge gcc
sudo apt-get purge g++
sudo apt-get install gcc
sudo apt-get install g++
3,安装显卡驱动:
使用标准Ubuntu 仓库进行自动安装
sudo ubuntu-drivers devices
sudo ubuntu-drivers autoinstall
sudo reboot // 重启
注:输入lshw -numeric -C display或者lspci -vnn | grep VGA // 查看nvidia显卡型号
NVIDIA官网驱动下载地址: https://www.nvidia.com/zh-cn/
12,更改gcc默认版本(gcc版本降级/升级)与update-alternatives的使用
1,安装,如需安装gcc=7.5.0,则输入指令:sudo apt-get install gcc-7.5.0
输入命令gcc --verison可查看gcc的版本
2,设置gcc的默认版本
设置之前可以先输入命令
ls /usr/bin/gcc*
查看安装的所有gcc版本。
然后输入下面的命令设置默认版本:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7.5.0 100
最后的数字为优先级(越大越高),然后可以输入以下命令查看设置结果
sudo update-alternatives --config gcc
13,无法获得锁 /var/lib/dpkg/lock-frontend - open (11: 资源暂时不可用)
E: 无法获取 dpkg 前端锁(/var/lib/dpkg/lock
输入:sudo rm /var/lib/dpkg/lock-frontend
随后出现问题:
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)
E: Unable to lock the administration directory (/var/lib/dpkg/), is another process using it?
翻译:
E: 无法获得锁 /var/lib/dpkg/lock - open (11: 资源暂时不可用)
E: 无法锁定管理目录(/var/lib/dpkg/),是否有其他进程正占用它?
原因:出现这种问题的原因大概是文件被锁或者占用所致。
解决:
输入如下命令:
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock
又出现问题:
E: dpkg was interrupted, you must manually run 'sudo dpkg --configure -a' to correct the problem.
解决:
sudo dpkg --configure -a
sudo rm /var/lib/dpkg/lock-frontend
再出现问题:
E: 无法获得锁 /var/cache/apt/archives/lock - open (11: 资源暂时不可用) E: 无法对目录 /var/cache/apt/archives/ 加锁
解决(强制解锁):
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock
14,nvidia driver is not loaded
通过gpu管理员排查问题:
sudo gpu-manager
如显示Is nvidia blacklisted? yes,则nvidia显卡被屏蔽了,再输入
ls /lib/modprobe.d/或者ls /etc/modprobe.d
检查modprobe,如有blacklist-nvidia.conf文件,则输入命令
rm blacklist-nvidia.conf
删除该屏蔽
15,vidia 显卡驱动问题
Linux系统一般默认安装的是开源的nouvea显卡驱动,它与nvidia显卡驱动产生冲突,欲装nvidia必禁nouvea!其次Nvidia驱动默认安装OpenGL桌面,然而这又与GNOME桌面冲突,为了系统不宕机,也需禁用nvidia的OpenGL,过程中需要搭建gcc、kernel等环境。如此,可顺利安装NVIDIA显卡驱动。
16,该命令用于查看目前的显卡使用模式
prime-select query
如显示on-demand,则为混合模式,再次输入
sudo prime-select nvidia
将显卡模式切换为nvidia模式
17,查看所有安装的cuda的包
sudo dpkg -l |grep cuda
如需删除cuda-toolkit-11-0则输入命令
sudo dpkg -P cuda-toolkit-11-0
18,dpkg: error processing package *** (--configure)
原因:这主要是由于不完全安装导致的。
解决:是删除或编辑安装信息文件。
粗暴方法一:删除所有信息之后update
sudo mv /var/lib/dpkg/info/ /var/lib/dpkg/info_old/
sudo mkdir /var/lib/dpkg/info/
sudo apt-get update
执行完以上代码后再用sudo apt-get install 安装
精细方法二:查看出错信息,定向删除或编辑
如报错:
dpkg: error processing package ***
subprocess installed post-installation script returned error exit status 127
则出错信息在subprocess installed post-installation script returned error exit status 127中
可以看到这里的提示post-installation的问题,那么需要编辑该文件,具体在
/var/lib/dpkg/info/[package_name].postinst
同理,还有可能出问题的是"pre-removal" or "post-removal" 对应后缀 .prerm or .postrm
此时删除问题文件或编辑注释掉所有或问题内容即可。例如
sudo rm /var/lib/dpkg/info/[package_name].postinst # 或更狠一点,全删
# sudo rm /var/lib/dpkg/info/[package_name].*
sudo dpkg --configure -a
sudo apt-get update
执行完以上代码后再用sudo apt-get install 安装
参考:https://blog.csdn.net/dou3516/article/details/105120221
19,ubuntu dpkg dependency problem(依赖问题)
原因:在安装ubuntu-mate-desktop强制退出,导致一些包没安装上
一般解决方案:sudo dpkg --configure -a
20,W: GPG 错误:http://archive.ubuntu.com/ubuntu trusty Release: 由于没有公钥,无法验证下列签名: NO_PUBKEY 40976EAF437D05B5 NO_PUBKEY 3B4FE6ACC0B21F32
E: 仓库 “http://archive.ubuntu.com/ubuntu trusty Release” 没有数字签名。
N: 无法安全地用该源进行更新,所以默认禁用该源。
N: 参见 apt-secure(8) 手册以了解仓库创建和用户配置方面的细节。
解决:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 3B4FE6ACC0B21F32
最后一串数字改为没有数字签名的那个密钥
21,ubuntu22.04安装gcc-7
首先sudo su进入root模式,再输入
vim /etc/apt/sources.list
配置下载镜像地址,将
deb [arch=amd64] http://archive.ubuntu.com/ubuntu focal main universe添加到文件末尾,“:wq“保存再退出,之后输入
apt-get update更新镜像,再输入
apt-get -y install gcc-7 g++-7安装相应的gcc版本,输入
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 50
update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 50
配置gcc,g++优先级为50
如需切换gcc版本则输入
update-alternatives --config gcc
显示:
有 2 个候选项可用于替换 gcc (提供 /usr/bin/gcc)。
选择 路径 优先级 状态
------------------------------------------------------------
0 /usr/bin/gcc-7 50 自动模式
1 /usr/bin/gcc-7 50 手动模式
* 2 /usr/bin/gcc-8 30 手动模式
要维持当前值[*]请按<回车键>,或者键入选择的编号:
输入相应编号即可切换gcc版本
注:如需查看gcc版本,则输入gcc --version
22,查找cuda位置
whereis cuda
23,subprocess.CalledProcessError: Command ‘[‘which‘, ‘c++‘]‘ returned non-zero exit status 1
创建符号链接:
sudo ln -s /usr/bin/g++ /usr/bin/c++
24,pdb调试(python)
详见链接:python 调试工具 pdb 的基本用法(Python Debugger)_pdb python_ctrl A_ctrl C_ctrl V的博客-CSDN博客
四,总结:
配置训练环境必须严格按照github文章上所需要的软件版本安装,否则可能造成版本不对应,高版本的更新可能简化了低版本,造成无法正确读取等问题。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









