






一,名词解释
1,DDP技术,核心思想是将模型和数据复制到多个 GPU 上并行训练,然后汇总平均梯度。
2,EMA,在深度学习中,经常会用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒
3,Bbox是BoundingBox(边界框)的缩写,指的是目标检测中用于表示物体位置和大小的有向矩形框。
二,解读
1,提出了一种新的端到端框架,该框架具有显式框检测,用于多人姿态估计,它统一了人类级别(全局)和关键点级别(局部)信息之间的上下文学习。
2,首先,引入了一个人工检测解码器,从编码的令牌中提取全局特征。它可以为后期的关键点检测提供良好的初始化,使训练过程收敛速度快。
3,其次,为了在关键点附近引入上下文信息,将姿态估计视为关键点框检测问题,以学习每个关键点的框位置和内容。人-关键点检测解码器采用人-关键点特征交互学习策略,进一步增强全局和局部特征聚合能力。
4,是一个完全端到端的多人姿态估计框架,没有任何后处理(后处理和密集的热图监督等)。
5,采用查询选择(QS)策略来更好地初始化,提出了一个从粗到精的方案来逐步选择高质量的人工查询。
6,将多人姿态估计作为多集关键点盒子检测问题。
7,通过人对关键点查询扩展流程初始化多组关键点查询(即包括内容和位置查询),并将人和关键点查询连接在一起,作为人对关键点检测解码器的输入(图3 (b)),以计算每个人的精确关键点位置。
8,关键点内容查询和位置查询由相应的人工查询初始化,而不是随机初始化。
9,对于一组特定的关键点位置查询,将初始化过程分为中心坐标初始化(例如,fx, yg)和框大小初始化(例如,fw, hg)。对于前者,采用FFN通过使用相应的人类内容查询来回归所有K个位置的坐标。对于后者,K个盒子的大小通过点乘动态权重w2r K×2由相应人类盒子的宽度和高度决定。
10,在生成人-关键点查询后,将其馈送到人-关键点交互关注中
三,代码分析
顶1,python中[-1]、[:-1]、[::-1]、[n::-1]、[:,:,0]、[…,0]、[…,::-1]的意思(下面的a = [1,2,3,4,5,6])
[-1]: 列表最后一项

[:-1]: 从第一项到最后一项
原型是[n : m],前闭后开,索引从零开始,n可以取到,m不可取到。

[::-1]: 代表从全列表倒序取
原型是[n : m : k],代表的是从那一段开始取,隔几个取一次。前闭后开,k代表间隔,可正可负,正值代表正向顺序跳取,负值代表反向跳取。
需要注意的是,当k为正的时候起始索引应该小于结束索引;当k为负的时候起始索引应该大于结束索引,因为在倒序来看,首先是索引值大的被取到,然后才是索引值小的。![]()
[n::-1]: 同上所述,从索引n开始倒序取值:

[:,:,0]: 它是对多维数据的一种处理方式,代表了前两维全选,取其中的所有0号索引。
原型是[n:m, j:k, g:h],维度可以更多,在图片处理中,一般是三维的。n,m控制最外层列表的取值,从第n个元素到第m个元素,前闭后开;j,k控制n,m取中的元素的列表中的元素的选取,也是前闭后开,g,h管j,k取中元素的列表中的元素的选取,例子如下:

[…,0]: 代表了取最里边一层的所有第0号元素,…代表了对:,:,:,的省略。注意只能进行一次省略,不能是[… , …]

放在后面视为其中的所有值
[…,::-1]: 是对最内层的列表进行逆序取值:
a[: , ::-1 , :],他就会把所有的第二层进行颠倒:
顶2,IOU交并比
IoU优点:(1)IoU具有尺度不变性(2)结果非负,且范围是(0, 1)
IoU缺点:(1)如果两个目标没有重叠,IoU将会为0,并且不会反应两个目标之间的距离,在这种无重叠目标的情况下,如果IoU用作于损失函数,梯度为0,无法优化。
(2)IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。

GIoU:
计算方法:对于任意的两个A、B框,首先找到一个能够包住它们的最小方框C。然后计算C \ (A ∪ B) 的面积与C的面积的比值,注:C \ (A ∪ B) 的面积为C的面积减去A∪B的面积。再用A、B的IoU值减去这个比值得到GIoU。


优点:(1)当IoU=0时,仍然可以很好的表示两个框的距离。
(2)GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
缺点:(1)当两个框属于包含关系时,GIoU会退化成IoU,无法区分其相对位置关系,如下图:

(2)由于GIoU仍然严重依赖IoU,因此在两个垂直方向,误差很大,很难收敛。两个框在相同距离的情况下,水平垂直方向时,此部分面积最小,对loss的贡献也就越小,从而导致在垂直水平方向上回归效果较差。如下图,三种情况下GIoU的值一样,GIoU将很难区分这种情况。

DIoU:
将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定;
公式如下:

其中分别代表了预测框和真实框的中心点,且 ρ 代表的是计算两个中心点间的欧式距离。 c 代表的是能够同时包含预测框和真实框的最小外接矩形的对角线长度。、
优点:(1)DIoU loss可以直接最小化两个目标框的距离,因此比GIoU loss收敛快得多。
(2)对于包含两个框在水平方向和垂直方向上这种情况,DIoU损失可以使回归非常快。
(3)DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
缺点:虽然DIOU能够直接最小化预测框和真实框的中心点距离加速收敛,但是Bounding box的回归还有一个重要的因素纵横比暂未考虑。如下图,三个红框的面积相同,但是长宽比不一样,红框与绿框中心点重合,这时三种情况的DIoU相同,证明DIoU不能很好的区分这种情况。

CIOU:
是在IOU的基础上考虑了两个真实框和预测框的中心点距离(图中的d)还有两个框的最小包裹框的对角线距离(图中的c,最小包裹矩形框是图中虚线部分)。

如当两个框不重叠的时候,那么此时的IOU是等于0的,这样会导致无法进行反向传播,而CIOU可以很好的解决这一问题。公式如下:

其中α是权重函数,v用来度量宽高比的一致性:


最终CIoU Loss定义为:

优点:考虑了框的纵横比,可以解决DIoU的问题。
缺点:通过CIoU公式中的v反映的纵横比的差异,而不是宽高分别与其置信度的真实差异,所以有时会阻碍模型有效的优化相似性。
EIOU:
EIOU Loss,将纵横比拆开,并且加入Focal聚焦优质的预测框。
惩罚项公式如下:
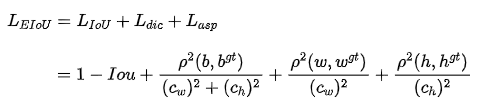
其中 ![]() 和
和 ![]() 是覆盖两个Box的最小外接框的宽度和高度。
是覆盖两个Box的最小外接框的宽度和高度。
优点:(1)将纵横比的损失项拆分成预测的宽高分别与最小外接框宽高的差值,加速了收敛提高了回归精度。
(2)引入了Focal Loss优化了边界框回归任务中的样本不平衡问题,即减少与目标框重叠较少的大量锚框对BBox 回归的优化贡献,使回归过程专注于高质量锚框。
壹main.py
1,models.registry模型注册
2,MODULE_BUILD_FUNCS模块构建函数
3,os.path.join(path,*paths)
- path 位置参数,必传,路径
- *paths 可变参数,可以传入多个路径
示例:
os.path.join('/root', 'sd')
'/root/sd'4,cfg = Config.fromfile(args.config_file)通过配置文件生成 config,配置文件可以是 py、yaml、yml 和 json 格式。
5,Dump文件是进程的内存镜像
6,json.dump()
将json对象存储在扩展名为.json的文件中
json.dump(object, file)接受两个实参:存储的数据、存储数据的文件对象,可在函数中添加indent属性,代表缩进字符个数;添加ensure_ascii属性(True,False),规定编码格式
7,vars()函数,用于返回对象的字典,其中包含对象的属性。
8,setattr(args, k, v),设置对应的key,value;getattr(),通过名称获取
9,torch.device(“device_type:device_id”) 来创建一个设备对象,其中 device_type 是设备类型,可以是 “cpu” 或 “cuda”,而 device_id 是GPU的标识号(从 0 开始)
cpu_device = torch.device("cpu") # 创建一个CPU设备对象
gpu_device = torch.device("cuda:0") # 创建第一个GPU设备对象10,model.module
如果模型被 nn.parallel.DistributedDataParallel 包装,那么使用 model.module 可以访问原始的模型对象,而不是并行包装的对象。假设在一个进程里改变了 model.module 的参数,那么该进程中被 nn.parallel.DistributedDataParallel 包装的模型的参数也会改变(其它进程不会改变,因为还没有进行同步)。
11,numel(),返回数组中元素的个数
n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
12,torch.optim.Adam优化器参数学习
optimizer = torch.optim.AdamW(param_dicts, lr=args.lr,
weight_decay=args.weight_decay)
13,dataset和dataloader:无论我们构建什么样的pytorch程序来训练网络,在数据准备部分都少不了两个东西:Dataset和DataLoader。前者用来定义自己的数据集类型(内部实现的时侯其实最主要的是写清楚__getitem__()方法);而后者则是负责真正在运行的时侯给网络递送数据。
14,if args.frozen_weights is not None: 这是一个条件语句,用于检查是否指定了预训练模型的路径。
15,os.environ.get,用于获取系统环境变量的值。
16,pycocotools工具包中cocoeval中的evaluateImg(计算单张图片在特征类别,特定面积阈值,特定最大检测结果下的结果), accumulate(将每张图片的评估结果累计到一起,并把结果存在self.eval变量中)以及summarize(输出给定检测指标、给定iouThr、给定面积阈值、给定最大检测结果时想要的指标)函数
# 将cocoeval的结果保存到本地文件中
cocoeval_result = coco_evaluator.coco_eval['bbox'].eval17,argparse是python用于解析命令行参数的标准模块。
常常把argparse的使用简化成下面四个步骤
- import argparse ;首先导入该模块
- parser = argparse.ArgumentParser();创建一个解析对象
- parser.add_argument();然后向该对象中添加要关注的命令行参数和选项,每一个add_argument方法对应一个要关注的参数或选项;
- parser.parse_args();调用parse_args()方法进行解析,解析成功之后即可使用。
18,mkdir(parents=True, exist_ok=True)
parents:如果父目录不存在,是否创建父目录。
exist_ok:只有在目录不存在时创建目录,目录已存在时不会抛出异常。
贰box_loss.py
1,torch.sigmoid(bboxes1),将值映射到0-1之间
2,shape[-1]
rows = bboxes1.shape[0],shape用法:
x=np.array([[1,2,3],[4,5,6]])
print(x.shape)#(2, 3)
x=np.array([[1,2,3],[4,5,6]])
print(x.shape[0])#2
对于二维张量,shape[0]代表行数,shape[1]代表列数
shape[-1]代表最后一个维度,如在二维张量里,shape[-1]表示列数
shape[::-1] 是一个 Python 中的列表切片操作符,将列表或数组的维度翻转。例如,对于一个形状为 (3,4,5) 的数组,使用 shape[::-1] 可以得到一个形状为 (5,4,3)
3,torch.zeros(),用于创建一个指定大小的全零张量(tensor)。即返回一个新的张量,其元素全部为零,并具有指定的形状、数据类型和设备。
cious = torch.zeros((rows, cols))
4,torch.exp(),用于对输入的张量进行按元素指数运算。指数运算是将基数的指数次幂的结果
w1 = torch.exp(bboxes1[:, 2])
x = torch.tensor([-2.0, -4.0, 0.0, 6.0, 8.0])
y = torch.exp(x)
print(y)#tensor([1.3534e-01, 1.8316e-02, 1.0000e+00, 4.0343e+02, 2.9810e+03])
5,bboxes1[:, 2]
a=torch.rand((2,3))
b=torch.rand((3,2))
#a[:,:2]的shape为(2,2);b[:,:2]的shape为(3,2)6,torch.clamp_(),将输入input张量每个元素的值压缩到区间 [min,max],并返回结果到一个新张量。
叁box_ops.py
1,torch.unbind(input,dim=0)
例子:
>>> torch.unbind(torch.tensor([[1, 2, 3],
>>> [4, 5, 6],
>>> [7, 8, 9]]))
(tensor([1, 2, 3]), tensor([4, 5, 6]), tensor([7, 8, 9]))2,torch.stack(b, dim=-1),是把多个2维的张量凑成一个3维的张量;多个3维的凑成一个4维的张量…以此类推,也就是在增加新的维度进行堆叠。
可以保留两个信息:1. 序列和2. 张量矩阵信息,属于扩张再拼接的函数。
3,dim=-1与dim=2等效
4,all()
python内置函数all可用于判断传入的可迭代参数 iterable 中的所有元素是否都为True,如果是则返回True,反之返回False。如果可迭代对象是空的,也会返回True。
在判断元素是否为True时,只要元素不是0、空、None、False,就视为True。
5,assert断言语句和 if 分支有点类似,它用于对一个 bool 表达式进行断言,如果该 bool 表达式为 True,该程序可以继续向下执行;否则程序会引发 AssertionError 错误。
assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
6,pairwise_iou函数的作用是计算IoU
7,用masks_to_boxes函数将 mask 转化为边界框(bounding box)
8, torch.meshgrid()的功能是生成网格,可以用于生成坐标。函数输入两个数据类型相同的一维张量,两个输出张量的行数为第一个输入张量的元素个数,列数为第二个输入张量的元素个数
import torch
a = torch.tensor([1, 2, 3, 4])
print(a)
b = torch.tensor([4, 5, 6])
print(b)
x, y = torch.meshgrid(a, b)
print(x)
print(y)
结果:
tensor([1, 2, 3, 4])
tensor([4, 5, 6])
tensor([[1, 1, 1],
[2, 2, 2],
[3, 3, 3],
[4, 4, 4]])
tensor([[4, 5, 6],
[4, 5, 6],
[4, 5, 6],
[4, 5, 6]])9,torch.unsqueeze()函数起到升维的作用,dim等于几表示在第几维度加一,比如原来x的size=([4]),x.unsqueeze(0)之后就变成了size=([1, 4]),而x.unsqueeze(1)之后就变成了size=([4, 1]),注意dim∈[-input.dim() - 1, input.dim() + 1]
# 输入:
x = torch.tensor([1, 2, 3, 4]) # x.dim()=1
print(x)
print(x.shape)
y = x.unsqueeze(0)
print(y)
print(y.shape) # 此时y.dim()=2
z = x.unsqueeze(1)
print(z)
print(z.shape) # 此时z.dim()=2
# 输出:
tensor([1, 2, 3, 4])
torch.Size([4])
tensor([[1, 2, 3, 4]])
torch.Size([1, 4])
tensor([[1],
[2],
[3],
[4]])
torch.Size([4, 1])
10,X.flatten(),将维度展开为一维。flatten(dim)表示,从第dim个维度开始展开,将后面的维度转化为一维。默认是x.flatten('A')按照行来降维的,x.flatten('F')是按照列的方向降维。

11,masked_fill(),在时序任务中,主要是用来mask掉当前时刻后面时刻的序列信息。此时的mask主要实现时序上的mask。
>>>a=torch.tensor([1,0,2,3])
>>>a.masked_fill(mask = torch.ByteTensor([1,1,0,0]), value=torch.tensor(-1e9))
>>>a
>>>tensor([-1.0000e+09, -1.0000e+09, 2.0000e+00, 3.0000e+00])
12,[x_min, y_min, x_max, y_max]边框坐标编码
肆keypoint_ops.py
1,torch.zeros_like(keypoints),返回一个形状与input相同且值全为0的张量。
torch.zeros_like(input)相当于torch.zeros(input.size, dtype=input.dtype,layout=input.layout,device=input.device)。
input:[Tensor] input向量的形状决定了输出向量的形状。
dtype:[可选,torch.dtype] 返回张量的所需数据类型。如果为None,则使用全局默认值
layout:[可选,torch.layout] 返回张量的期望内存布局形式,默认为torch.strided。
device:返回张量的期望计算设备。如果为None,使用当前的设备
requires_grad:[可选,bool] 是否需要自动微分,默认为False。
memory_format:[可选,torch.memory_format] 返回张量的所需内存格式,默认为torch.preserve_format。
2," / "表示 浮点数除法,返回浮点结果;" // "表示整数除法。
伍misc.py(可直接复制)
1,SmoothedValue类可以简单理解为一个加强版的list(deque),是一个Python类SmoothedValue的初始化部分,该类用于跟踪一系列数值并提供对这些数值的平滑处理(滑动窗口或全局平均值)。
class SmoothedValue(object):
"""Track a series of values and provide access to smoothed values over a
window or the global series average.
"""
def __init__(self, window_size=20, fmt=None):
if fmt is None:
fmt = "{median:.4f} ({global_avg:.4f})"
self.deque = deque(maxlen=window_size)
self.total = 0.0
self.count = 0
self.fmt = fmt
def update(self, value, n=1):
self.deque.append(value)
self.count += n
self.total += value * n
def synchronize_between_processes(self):
"""
Warning: does not synchronize the deque!
"""
if not is_dist_avail_and_initialized():
return
t = torch.tensor([self.count, self.total], dtype=torch.float64, device='cuda')
dist.barrier()
dist.all_reduce(t)
t = t.tolist()
self.count = int(t[0])
self.total = t[1]
@property
def median(self):
d = torch.tensor(list(self.deque))
if d.shape[0] == 0:
return 0
return d.median().item()
@property
def avg(self):
d = torch.tensor(list(self.deque), dtype=torch.float32)
return d.mean().item()
@property
def global_avg(self):
return self.total / self.count
@property
def max(self):
return max(self.deque)
@property
def value(self):
return self.deque[-1]
def __str__(self):
return self.fmt.format(
median=self.median,
avg=self.avg,
global_avg=self.global_avg,
max=self.max,
value=self.value)
解释:
__init__(self, window_size=20, fmt=None):初始化方法,用于创建SmoothedValue类的实例。
update(self, value, n=1):更新方法,用于添加一个新的数值到SmoothedValue中。参数value是要添加的数值,参数n表示数值的数量(默认为1)。这个方法用于不断更新跟踪的数值序列。
syncronize_between_processes,该方法用于在多个进程之间同步计数和总和。
@property是个装饰器,这里可简单理解为把本来计算中位数的方法转为median(中值)属性。
median:返回数值序列的中位数。
avg:返回数值序列的平均值。
global_avg:返回数值序列的全局平均值,即所有数值的总和除以数值的数量。
max:返回数值序列中的最大值,即双端队列(deque)中的最大数值。
value:返回数值序列中的最新值,即双端队列(deque)中的最后一个数值。
__str__:用于将SmoothedValue实例转换为字符串表示。
2,all_gather()
gather操作用于在不同节点间收集信息,首先初始化一个空Tensor列表tensor_list 用于接收所有节点的信息,然后调用all_gather即可在所有节点中得到包含每个节点本地张量的列表,列表中有world_size个元素,每个元素都是bs的大小,后续通过cat操作即可得到大小为bs * world_size的表示
def all_gather(data):
"""
Run all_gather on arbitrary picklable data (not necessarily tensors)
Args:
data: any picklable object
Returns:
list[data]: list of data gathered from each rank
"""
world_size = get_world_size()
if world_size == 1:
return [data]
# serialized to a Tensor
buffer = pickle.dumps(data)
storage = torch.ByteStorage.from_buffer(buffer)
tensor = torch.ByteTensor(storage).to("cuda")
# obtain Tensor size of each rank
local_size = torch.tensor([tensor.numel()], device="cuda")
size_list = [torch.tensor([0], device="cuda") for _ in range(world_size)]
dist.all_gather(size_list, local_size)
size_list = [int(size.item()) for size in size_list]
max_size = max(size_list)
# receiving Tensor from all ranks
# we pad the tensor because torch all_gather does not support
# gathering tensors of different shapes
tensor_list = []
for _ in size_list:
tensor_list.append(torch.empty((max_size,), dtype=torch.uint8, device="cuda"))
if local_size != max_size:
padding = torch.empty(size=(max_size - local_size,), dtype=torch.uint8, device="cuda")
tensor = torch.cat((tensor, padding), dim=0)
dist.all_gather(tensor_list, tensor)
data_list = []
for size, tensor in zip(size_list, tensor_list):
buffer = tensor.cpu().numpy().tobytes()[:size]
data_list.append(pickle.loads(buffer))
return data_list解释:
- 在分布式计算环境中执行数据的全局收集
world_size = get_world_size():获取当前分布式环境中的总进程数。(假设有两个机器,每个机器4张卡,那么world_size就是2*4=8;rank表示全局的进程号,值为0到7;local_rank的当前机器的进程号,在两个机器中均为0到3,假设设置batch_size(bs)为16,那么全局的bs就是bs * world_size = 128)
if world_size == 1::如果只有一个进程,则无需执行全局收集,直接返回包含原始数据的列表。
- 将输入的
data对象序列化为一个PyTorch字节张量buffer = pickle.dumps(data):将输入的数据data序列化为字节流,并存储在buffer中。
storage = torch.ByteStorage.from_buffer(buffer):创建一个PyTorch字节存储(ByteStorage)对象,用于存储序列化数据的字节。
tensor = torch.ByteTensor(storage).to("cuda"):将字节存储转换为PyTorch字节张量(ByteTensor)并将其移动到CUDA设备上。
- 获取分布式环境中每个进程的张量大小
local_size = torch.tensor([tensor.numel()], device="cuda"):创建一个包含当前进程张量大小的张量,并将其移到CUDA设备上。
size_list:创建一个包含每个进程张量大小的列表,其中每个元素都是一个包含零的张量,用于接收其他进程的张量大小信息。
dist.all_gather(size_list, local_size):使用分布式通信操作dist.all_gather,将每个进程的张量大小信息收集到size_list中。
size_list:将size_list中的每个张量大小转换为整数,并找到最大的大小。
- 创建一个用于接收从所有进程收集到的张量的列表
tensor_listtensor_list = []:首先,它创建一个空列表tensor_list,用于存储从每个进程收集到的张量。列表的长度等于进程总数,每个元素都是一个具有相同最大大小的空PyTorch张量。这里的size_list包含了每个进程的张量大小信息。
for _ in size_list::然后,它使用size_list中的每个进程的张量大小信息,迭代地创建一个空的PyTorch张量,并将其添加到tensor_list中。这确保了tensor_list中的每个元素都是一个具有相同大小的张量。
if local_size != max_size::接下来,它检查当前进程的张量大小是否与最大大小max_size不同。
padding = torch.empty(size=(max_size - local_size,), dtype=torch.uint8, device="cuda"):如果当前进程的张量大小不等于最大大小,那么它创建一个名为padding的空PyTorch张量,其大小等于max_size - local_size,这是为了将当前进程的张量填充到与其他进程相同的大小。
tensor = torch.cat((tensor, padding), dim=0):然后,它使用torch.cat函数将当前进程的张量tensor与padding张量连接起来,以便它们具有相同的大小。这是为了确保所有进程的张量都具有相同的大小,以便进行全局收集。
dist.all_gather(tensor_list, tensor):最后,使用PyTorch的分布式通信操作dist.all_gather,它将每个进程的张量tensor收集到tensor_list中。由于所有张量的大小现在相同,可以安全地进行收集。
- 将从所有进程收集到的数据张量列表
tensor_list转换回原始数据对象的列表data_listdata_list = []:首先,它创建一个空列表data_list,用于存储从张量恢复的原始数据对象。
for size, tensor in zip(size_list, tensor_list)::然后,它迭代size_list和tensor_list中的元素,其中size是张量的大小,tensor是从其他进程收集到的数据张量。
buffer = tensor.cpu().numpy().tobytes()[:size]:对于每个张量,它首先使用.cpu()将张量从CUDA设备移到CPU上,然后使用.numpy()将其转换为NumPy数组,最后使用.tobytes()将NumPy数组转换为字节表示。由于在之前的填充步骤中,我们已经确保了每个张量的大小与原始数据相符,因此只需提取前size个字节,以避免多余的填充数据。
data_list.append(pickle.loads(buffer)):最后,它使用pickle.loads()将字节流buffer反序列化为原始数据对象,并将其添加到data_list中。
最终,函数返回data_list,其中包含了从所有进程收集到的原始数据对象的列表。
3,reduce_dict()
作用是将一个字典中的值从所有进程中进行归约,以便所有进程都具有归约后的结果。
def reduce_dict(input_dict, average=True):
"""
Args:
input_dict (dict): all the values will be reduced
average (bool): whether to do average or sum
Reduce the values in the dictionary from all processes so that all processes
have the averaged results. Returns a dict with the same fields as
input_dict, after reduction.
"""
world_size = get_world_size()
if world_size < 2:
return input_dict
with torch.no_grad():
names = []
values = []
# sort the keys so that they are consistent across processes
for k in sorted(input_dict.keys()):
names.append(k)
values.append(input_dict[k])
values = torch.stack(values, dim=0)
dist.all_reduce(values)
if average:
values /= world_size
reduced_dict = {k: v for k, v in zip(names, values)}
return reduced_dict解释:
world_size = get_world_size():首先,获取当前分布式环境中的进程总数,确定是否需要进行归约。如果只有一个进程,直接返回输入的字典。
with torch.no_grad()::这是一个上下文管理器,用于确保在此代码块中不会创建梯度计算图。
names = [] 和 values = []:创建两个空列表,用于分别存储字典中的键和对应的值。
for k in sorted(input_dict.keys())::迭代字典中的键,通过sorted函数对键进行排序
names.append(k) 和 values.append(input_dict[k]):将每个键存储在names列表中,将对应的值存储在values列表中。
values = torch.stack(values, dim=0):将values列表中的值堆叠成一个张量,其中每一行对应一个进程的值。dim=0表示在张量的第一个维度上堆叠。
dist.all_reduce(values):将所有进程中的值进行归约。每个进程的值将与其他进程的值相加,从而在所有进程中获得了总和。
values /= world_size:将总和的值除以进程总数,以获得平均值。
reduced_dict = {k: v for k, v in zip(names, values)}:将键和归约后的值重新组成一个字典,并将其存储在reduced_dict中。
4,MetricLogger类
主要作用是方便记录和打印训练过程中的指标数据
class MetricLogger(object):
def __init__(self, delimiter="\t"):
self.meters = defaultdict(SmoothedValue)
self.delimiter = delimiter
def update(self, **kwargs):
for k, v in kwargs.items():
if isinstance(v, torch.Tensor):
v = v.item()
assert isinstance(v, (float, int))
self.meters[k].update(v)
def __getattr__(self, attr):
if attr in self.meters:
return self.meters[attr]
if attr in self.__dict__:
return self.__dict__[attr]
raise AttributeError("'{}' object has no attribute '{}'".format(
type(self).__name__, attr))
def __str__(self):
loss_str = []
for name, meter in self.meters.items():
if meter.count > 0:
loss_str.append(
"{}: {}".format(name, str(meter))
)
return self.delimiter.join(loss_str)
def synchronize_between_processes(self):
for meter in self.meters.values():
meter.synchronize_between_processes()
def add_meter(self, name, meter):
self.meters[name] = meter
def log_every(self, iterable, print_freq, header=None, logger=None):
if logger is None:
print_func = print
else:
print_func = logger.info
i = 0
if not header:
header = ''
start_time = time.time()
end = time.time()
iter_time = SmoothedValue(fmt='{avg:.4f}')
data_time = SmoothedValue(fmt='{avg:.4f}')
space_fmt = ':' + str(len(str(len(iterable)))) + 'd'
if torch.cuda.is_available():
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}',
'max mem: {memory:.0f}'
])
else:
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}'
])
MB = 1024.0 * 1024.0
for obj in iterable:
data_time.update(time.time() - end)
yield obj
# import ipdb; ipdb.set_trace()
iter_time.update(time.time() - end)
if i % print_freq == 0 or i == len(iterable) - 1:
eta_seconds = iter_time.global_avg * (len(iterable) - i)
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
if torch.cuda.is_available():
print_func(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time),
memory=torch.cuda.max_memory_allocated() / MB))
else:
print_func(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time)))
i += 1
end = time.time()
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print_func('{} Total time: {} ({:.4f} s / it)'.format(
header, total_time_str, total_time / len(iterable)))
解释:
- __init__(self, delimiter="\t"):这是类的构造函数,用于初始化一个MetricLogger对象。它接受一个可选的参数delimiter,用于指定打印指标数据时的分隔符,默认为制表符("\t")。
self.meters:这是一个字典,用于存储指标数据。字典的键是指标的名称,而值是与每个指标相关联的SmoothedValue对象,该对象用于平滑和跟踪指标的值。
self.delimiter:这是一个属性,表示在打印指标数据时使用的分隔符,默认为制表符("\t")。
- update(self,**kwargs)用于更新指标数据。它接受一个关键字参数
kwargs,其中每个键值对表示一个指标的名称和相应的值。方法会遍历kwargs中的每个键值对,将指标的值添加到self.meters字典中的相应SmoothedValue对象中。 __getattr__(self,attr)用于处理对象的属性访问。具体来说,当你尝试访问MetricLogger对象的属性时,会调用__getattr__方法来确定应该返回什么值。__str__(self)使用户可以通过print函数轻松地查看对象的状态。synchronize_between_processes(self)用于在多个进程之间同步指标数据。- add_meter(self,name,meter)用于向
MetricLogger对象中添加新的指标。(name:要添加的指标的名称,作为字符串。meter:一个SmoothedValue对象,用于跟踪和记录指标值。) - log_every(self, iterable, print_freq, header=None, logger=None)提供一个可视化和实时监控
(1)主要步骤:
初始化迭代计数器 i,如果没有提供 header,则将其设置为空字符串。
记录当前时间作为 start_time。
初始化迭代时间和数据加载时间的平滑值(iter_time 和 data_time)。
记录当前时间作为 end。
根据 iterable 的长度确定输出格式中迭代次数的显示宽度。
根据是否有可用的 CUDA 设备,设置不同的日志消息格式(log_msg)。接下来,进入迭代循环:
对于 iterable 中的每个对象,执行以下操作:
更新 data_time,记录从上一次迭代到当前迭代的时间。
使用 yield obj 从迭代器中获取下一个对象,并将其返回。yield 关键字用于生成器函数,可以暂停函数的执行并返回一个值,直到下一次迭代被调用。
更新 iter_time,记录从上一次迭代到当前迭代的时间。检查是否达到了指定的 print_freq 或是否已经遍历完了 iterable 中的所有对象。如果是,执行以下操作:
计算估计的剩余时间(eta_seconds):这是平均每次迭代花费的时间乘以剩余迭代次数。
格式化日志消息 log_msg,将当前迭代次数、总迭代次数、估计的剩余时间、平滑值统计信息以及时间和数据加载时间插入到消息中。
如果CUDA设备可用,还包括最大内存使用量。
打印日志消息。增加迭代计数器 i,更新 end 以记录当前时间,然后继续下一次迭代。
最后,计算总的训练时间,并打印总时间以及每次迭代的平均时间。
这个方法用于实时监控和记录训练进程中的信息,包括迭代次数、剩余时间、性能指标等,以便及时调整训练策略和分析模型的性能。
(2)主要迭代循环MB = 1024.0 * 1024.0:这是用于将字节转换为兆字节(MB)的常数,以便在日志消息中显示内存使用量。
for obj in iterable::这是迭代 iterable 中的对象的开始。iterable 是用于训练的数据加载器。
data_time.update(time.time() - end):记录了数据加载时间,它计算从上一次迭代到当前迭代的时间差并更新 data_time 的平滑值。
yield obj:从迭代器中获取下一个对象,并将其返回。使用 yield 关键字可以将当前函数变成一个生成器,它会在 yield 处暂停执行并将值传递给调用方。
iter_time.update(time.time() - end):记录了整个迭代的时间,它计算了从上一次迭代到当前迭代的时间差,并更新了 iter_time 的平滑值。
if i % print_freq == 0 or i == len(iterable) - 1::检查是否达到了指定的 print_freq 或是否已经遍历完了 iterable 中的所有对象。如果是这两种情况之一,就会执行以下操作,用于记录日志信息:
eta_seconds = iter_time.global_avg * (len(iterable) - i):计算了估计的剩余时间(秒),这是平均每次迭代花费的时间乘以剩余迭代次数。
eta_string = str(datetime.timedelta(seconds=int(eta_seconds))):将估计的剩余时间转换为可读的时间格式(天、小时、分钟和秒)。
日志消息的构建:根据是否有可用的 CUDA 设备来构建日志消息 log_msg,并将迭代次数、总迭代次数、估计的剩余时间、平滑值统计信息以及时间和数据加载时间插入到消息中。如果有可用的 CUDA 设备,还会包括最大内存使用量。
打印日志消息:最后,根据所构建的日志消息 log_msg 打印日志信息。
i += 1:迭代计数器 i 增加 1,用于跟踪当前迭代次数。
end = time.time():更新 end 以记录当前时间,为下一次迭代做准备。
最后,计算并打印总的训练时间以及每次迭代的平均时间。
5,get_sha()
用于获取当前代码库的 Git 信息,包括提交的 SHA(commit hash)、工作目录的状态以及当前的分支。
def get_sha():
cwd = os.path.dirname(os.path.abspath(__file__))
def _run(command):
return subprocess.check_output(command, cwd=cwd).decode('ascii').strip()
sha = 'N/A'
diff = "clean"
branch = 'N/A'
try:
sha = _run(['git', 'rev-parse', 'HEAD'])
subprocess.check_output(['git', 'diff'], cwd=cwd)
diff = _run(['git', 'diff-index', 'HEAD'])
diff = "has uncommited changes" if diff else "clean"
branch = _run(['git', 'rev-parse', '--abbrev-ref', 'HEAD'])
except Exception:
pass
message = f"sha: {sha}, status: {diff}, branch: {branch}"
return message解释:
- cwd = os.path.dirname(os.path.abspath(__file__)):获取当前脚本文件的绝对路径,并使用 os.path.dirname 获取它的父目录路径。这个路径用于设置 Git 命令的工作目录。
- _run(command):用来运行 Git 命令。
- sha = _run(['git', 'rev-parse', 'HEAD']):运行 Git 命令 git rev-parse HEAD,以获取当前代码库的最新提交的 SHA(commit hash)。
- subprocess.check_output(['git', 'diff'], cwd=cwd):运行 Git 命令 git diff,以检查工作目录中是否有未提交的更改。如果有未提交的更改,会引发异常,否则不会有异常。
- diff = _run(['git', 'diff-index', 'HEAD']):运行 Git 命令 git diff-index HEAD,以获取有关工作目录更改的详细信息。如果有未提交的更改,diff 将包含有关这些更改的信息,否则它是 "clean"。
- branch = _run(['git', 'rev-parse', '--abbrev-ref', 'HEAD']):运行 Git 命令 git rev-parse --abbrev-ref HEAD,以获取当前的 Git 分支名称。
- message = f"sha: {sha}, status: {diff}, branch: {branch}":构建一个包含 SHA、工作目录状态和分支信息的字符串。
- 返回包含 Git 信息的消息字符串。
6,collate_fn(batch)
将具有不同大小的图像和与之相关的信息组合成一个批次(batch),以便输入到神经网络中。
预处理以使大小不同的图像具有相同的尺寸或格式。
def collate_fn(batch):
# import ipdb; ipdb.set_trace()
batch = list(zip(*batch))
batch[0] = nested_tensor_from_tensor_list(batch[0])
return tuple(batch)解释:
- batch是一个包含批次中的多个样本的列表,每个样本包含两个元素,第一个元素是图像(可能是不同大小的),第二个元素是与图像相关的信息(如边界框、标签等)。
- batch = list(zip(*batch)):将批次中的样本重新排列,并将它们放入两个不同的列表中。现在batch[0]包含所有图像,batch[1]包含所有信息。
- batch[0] = nested_tensor_from_tensor_list(batch[0]):用函数 nested_tensor_from_tensor_list将图像列表转换为一个"嵌套张量",这个嵌套张量允许处理不同大小的图像。
- return tuple(batch)返回组合后的批次。
7,_max_by_axis(the_list)
目的是找到输入列表中的每个列的最大值。
def _max_by_axis(the_list):
# type: (List[List[int]]) -> List[int]
maxes = the_list[0]
for sublist in the_list[1:]:
for index, item in enumerate(sublist):
maxes[index] = max(maxes[index], item)
return maxes解释:
- maxes 初始化为第一个内部列表 the_list[0]。
- 函数遍历 the_list 中的每个内部列表,通过比较每个内部列表的元素与 maxes 中相应位置的元素,来更新 maxes 中的值。如果内部列表的元素比 maxes 中对应位置的元素更大,就用内部列表的元素替换 maxes 中的值。
- 最后返回 maxes,其中包含了每个列的最大值。
8,NestedTensor(object)
用于表示嵌套的张量(Nested Tensor)。主要用于处理具有不同形状或分辨率的图像数据,其中主张量表示图像,而掩码张量用于处理不同位置的信息。例如,在分割任务中,掩码张量可以用于表示每个像素是否属于对象区域。
class NestedTensor(object):
def __init__(self, tensors, mask: Optional[Tensor]):
self.tensors = tensors
self.mask = mask
if mask == 'auto':
self.mask = torch.zeros_like(tensors).to(tensors.device)
if self.mask.dim() == 3:
self.mask = self.mask.sum(0).to(bool)
elif self.mask.dim() == 4:
self.mask = self.mask.sum(1).to(bool)
else:
raise ValueError("tensors dim must be 3 or 4 but {}({})".format(self.tensors.dim(), self.tensors.shape))
def imgsize(self):
res = []
for i in range(self.tensors.shape[0]):
mask = self.mask[i]
maxH = (~mask).sum(0).max()
maxW = (~mask).sum(1).max()
res.append(torch.Tensor([maxH, maxW]))
return res
def to(self, device):
# type: (Device) -> NestedTensor # noqa
cast_tensor = self.tensors.to(device)
mask = self.mask
if mask is not None:
assert mask is not None
cast_mask = mask.to(device)
else:
cast_mask = None
return NestedTensor(cast_tensor, cast_mask)
def to_img_list_single(self, tensor, mask):
assert tensor.dim() == 3, "dim of tensor should be 3 but {}".format(tensor.dim())
maxH = (~mask).sum(0).max()
maxW = (~mask).sum(1).max()
img = tensor[:, :maxH, :maxW]
return img
def to_img_list(self):
"""remove the padding and convert to img list
Returns:
[type]: [description]
"""
if self.tensors.dim() == 3:
return self.to_img_list_single(self.tensors, self.mask)
else:
res = []
for i in range(self.tensors.shape[0]):
tensor_i = self.tensors[i]
mask_i = self.mask[i]
res.append(self.to_img_list_single(tensor_i, mask_i))
return res
@property
def device(self):
return self.tensors.device
def decompose(self):
return self.tensors, self.mask
def __repr__(self):
return str(self.tensors)
@property
def shape(self):
return {
'tensors.shape': self.tensors.shape,
'mask.shape': self.mask.shape
}
解释:
__init__(self, tensors, mask: Optional[Tensor])
-
tensors: 一个张量(通常是 PyTorch 张量),用于存储主要数据。
-
mask: 一个可选的张量,通常也是 PyTorch 张量,用于表示一个掩码或者标志位。这个掩码张量的形状通常与主张量相同,值通常是二进制的,用于指示主张量中的哪些元素是有效的,哪些是无效的。
to(self, device)
用于将 NestedTensor 对象中的数据转移到指定的设备(如GPU或CPU)。device 参数指定目标设备。
-
cast_tensor = self.tensors.to(device): 将主要张量 self.tensors 移动到指定的设备上。其中 device 是目标设备,可以是 'cuda'(GPU)或 'cpu'(CPU)等。
-
mask = self.mask: 获取掩码张量。
- 如果掩码张量存在,那么 cast_mask = mask.to(device) 将掩码张量移动到相同的目标设备上。
-
最后,返回一个新的 NestedTensor 对象,其中包含移动后的主要张量和掩码张量。
decompose(self): 返回一个包含两个元素的元组,第一个元素是主要张量 self.tensors,第二个元素是掩码张量 self.mask。
__repr__(self): 返回一个字符串表示,通常用于在打印 NestedTensor 对象时显示其内容。
9,nested_tensor_from_tensor_list(tensor_list: List[Tensor])
目的是将一个张量列表转换为 NestedTensor 对象,其中 NestedTensor 是一个包含主要张量和掩码张量的对象,用于处理不同大小的张量(例如图像)。
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
# TODO make this more general
if tensor_list[0].ndim == 3:
if torchvision._is_tracing():
# nested_tensor_from_tensor_list() does not export well to ONNX
# call _onnx_nested_tensor_from_tensor_list() instead
return _onnx_nested_tensor_from_tensor_list(tensor_list)
# TODO make it support different-sized images
max_size = _max_by_axis([list(img.shape) for img in tensor_list])
# min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list]))
batch_shape = [len(tensor_list)] + max_size
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return NestedTensor(tensor, mask)
解释:
-
if torchvision._is_tracing():
检查当前是否处于ONNX追踪模式(tracing mode)。ONNX是一种用于导出模型的格式。如果当前处于ONNX追踪模式,就用 _onnx_nested_tensor_from_tensor_list(tensor_list) 来创建 NestedTensor 对象。因为在ONNX追踪模式下,nested_tensor_from_tensor_list() 函数的行为可能无法正确导出到ONNX格式。
-
max_size = _max_by_axis([list(img.shape) for img in tensor_list]):这一行计算了输入图像列表 tensor_list 中所有图像的最大尺寸,包括宽度和高度。_max_by_axis 函数用于找到每个轴(维度)的最大尺寸。
-
batch_shape = [len(tensor_list)] + max_size:len(tensor_list) 给出了图像列表中图像的数量,即批次大小。max_size 包含了最大宽度和最大高度,将其添加到批次大小后,得到 batch_shape,它表示批次中每个图像的大小。
-
b, c, h, w = batch_shape:将 batch_shape 中的值解包到变量 b(批次大小)、c(通道数,一般为图像的通道数,如3表示RGB图像)、h(高度)和w(宽度)中。
-
dtype = tensor_list[0].dtype:获取了输入图像列表中的第一个图像的数据类型,通常为 torch.float32 或 torch.uint8。
-
device = tensor_list[0].device:获取了输入图像列表中的第一个图像所在的设备,通常为GPU。
-
tensor = torch.zeros(batch_shape, dtype=dtype, device=device):创建一个名为 tensor 的全零张量,其形状由 batch_shape 指定,数据类型由 dtype 指定,设备由 device 指定。
-
mask = torch.ones((b, h, w), dtype=torch.bool, device=device):创建一个名为 mask 的全一张量,形状为 (b, h, w),数据类型为布尔型 (dtype=torch.bool),设备与 tensor 相同。
-
使用 for 循环遍历 tensor_list 中的每个图像以及相应的 pad_img 和 m:pad_img 是 tensor 中的一部分,用于存储图像数据。通过切片操作将图像数据从原始图像 img 复制到 pad_img 中,以适应不同大小的图像。m 是一个布尔掩码,用于表示图像的有效区域。通过将 m 的部分设置为 False,将未使用的部分标记为无效。
-
最后,通过检查 tensor_list 中的图像是否都具有相同的尺寸,如果是则返回一个 NestedTensor 对象,否则引发 ValueError 异常。
10,_onnx_nested_tensor_from_tensor_list(tensor_list: List[Tensor]) -> NestedTensor
作用是将具有不同大小的图像张量列表转换为一个批量张量和一个掩码张量,以创建一个 NestedTensor 对象,同时考虑了 ONNX 跟踪的要求。返回一个 NestedTensor 对象,其中包含批量张量和掩码张量,以表示具有不同大小的图像。考虑了 ONNX 跟踪的要求。
@torch.jit.unused
def _onnx_nested_tensor_from_tensor_list(tensor_list: List[Tensor]) -> NestedTensor:
max_size = []
for i in range(tensor_list[0].dim()):
max_size_i = torch.max(torch.stack([img.shape[i] for img in tensor_list]).to(torch.float32)).to(torch.int64)
max_size.append(max_size_i)
max_size = tuple(max_size)
padded_imgs = []
padded_masks = []
for img in tensor_list:
padding = [(s1 - s2) for s1, s2 in zip(max_size, tuple(img.shape))]
padded_img = torch.nn.functional.pad(img, (0, padding[2], 0, padding[1], 0, padding[0]))
padded_imgs.append(padded_img)
m = torch.zeros_like(img[0], dtype=torch.int, device=img.device)
padded_mask = torch.nn.functional.pad(m, (0, padding[2], 0, padding[1]), "constant", 1)
padded_masks.append(padded_mask.to(torch.bool))
tensor = torch.stack(padded_imgs)
mask = torch.stack(padded_masks)
return NestedTensor(tensor, mask=mask)
解释:
- 创建一个空列表 max_size,用于存储每个维度的最大大小。
- 使用 for 循环遍历输入张量列表中的每个维度。对于每个维度,计算该维度上所有张量的最大值,并将结果存储为整数。这里使用 torch.max 函数来找到最大值。
- 将计算得到的每个维度的最大大小组合成一个元组 max_size。
- 创建两个空列表 padded_imgs 和 padded_masks,用于存储填充后的图像张量和掩码张量。
- 使用 for 循环遍历输入张量列表中的每个图像。对于每个图像,计算需要添加的填充量,并使用 torch.nn.functional.pad 函数将图像进行填充,以使其大小与 max_size 相同。同时,还创建一个掩码张量,并进行相应的填充,将空白区域标记为 True。
- 使用 torch.stack 函数将填充后的图像张量列表和掩码张量列表分别堆叠成批量张量和掩码张量。
- 返回一个包含批量张量和掩码张量的 NestedTensor 对象,表示具有不同大小的图像。
- 创建两个空列表 padded_imgs 和 padded_masks,用于存储填充后的图像张量和掩码张量。
- 使用 for 循环遍历输入张量列表 tensor_list 中的每个图像。
- 对于每个图像 img,计算需要添加的填充量 padding。padding 是一个包含三个元素的列表,分别表示在图像的三个维度(高度、宽度和通道数)上需要添加的填充量。这些填充量是通过将 max_size 减去当前图像的形状来计算的,确保所有图像都将填充为相同的大小。
- 使用 torch.nn.functional.pad 函数对图像 img 进行填充,以使其大小与 max_size 相同。填充的方式是在图像的高度、宽度和通道维度上分别添加填充量。填充后的图像被添加到 padded_imgs 列表中。
- 创建一个与图像 img 相同形状的全零张量 m,并将其数据类型设置为整数(dtype=torch.int)。这个张量将用作掩码。
- 使用 torch.nn.functional.pad 函数对掩码 m 进行填充,只在高度和宽度维度上添加填充。填充的方式是使用常数填充,将空白区域标记为 1(True),表示这些区域没有值。
- 将填充后的图像张量和填充后的掩码张量添加到 padded_imgs 和 padded_masks 列表中,并将掩码张量的数据类型转换为布尔型(to(torch.bool))。
- 用
torch.stack函数将填充后的图像张量列表padded_imgs和填充后的掩码张量列表padded_masks合并成一个新的张量tensor和掩码张量mask。 - 返回一个
NestedTensor对象,该对象包含了合并后的张量tensor和掩码张量mask。这个NestedTensor对象可以用于表示一批具有不同大小的图像,并在模型中进行处理,同时保持了相同的大小以便于处理。
11,setup_for_distributed(is_master)
用于在分布式环境中设置打印行为,以便在非主进程中禁用打印。
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print解读:
- 首先,将内置的 print 函数引用命名为 builtin_print。
- 然后,定义一个名为 print 的新函数,该函数接受与内置的 print 函数相同的参数和关键字参数。但它还接受一个名为 force 的关键字参数,该参数默认值为 False。
- 在新的 print 函数中,它首先检查 is_master 的值(该值表示当前进程是否为主进程)。如果 is_master 为 True 或者 force 参数为 True,则调用内置的 print 函数 builtin_print 打印传入的参数。
- 最后,它将新的 print 函数赋值给内置的 print 函数,从而在之后的代码中使用新的 print 函数来实现打印操作。
12,is_dist_avail_and_initialized()
用于检查当前环境是否支持分布式计算,并且是否已经初始化了分布式计算环境。
def is_dist_avail_and_initialized():
if not dist.is_available():
return False
if not dist.is_initialized():
return False
return True解读:
- 首先,使用 dist.is_available() 函数来检查当前环境是否支持分布式计算。如果不支持,返回 False。
- 接着,使用 dist.is_initialized() 函数来检查分布式计算环境是否已经初始化。如果未初始化,返回 False。
- 最后,如果分布式计算环境已经初始化且当前环境支持分布式计算,那么函数返回 True,表示分布式环境已经准备好使用。
13,get_world_size()
用于获取分布式计算环境中的世界大小(world size)。世界大小表示了分布式计算中的进程数量,也就是同时运行的任务或者计算节点的数量。
def get_world_size():
if not is_dist_avail_and_initialized():
return 1
return dist.get_world_size()解读:
- 首先,调用了 is_dist_avail_and_initialized() 函数,以检查当前环境是否支持分布式计算并且是否已经初始化。如果不满足这些条件,函数返回默认的世界大小为1,表示单机环境。
- 如果当前环境支持分布式计算且已经初始化,那么函数使用 dist.get_world_size() 函数来获取实际的世界大小,即分布式计算中的进程数量。
14,get_rank()
用于获取当前进程在分布式计算环境中的排名。排名表示当前进程在分布式计算中的唯一标识,通常从0开始递增,表示不同的计算节点或任务。
def get_rank():
if not is_dist_avail_and_initialized():
return 0
return dist.get_rank()解读:
- 首先,调用了 is_dist_avail_and_initialized() 函数,以检查当前环境是否支持分布式计算并且是否已经初始化。如果不满足这些条件,函数返回默认的排名为0,表示单机环境中的唯一进程。
- 如果当前环境支持分布式计算且已经初始化,那么函数使用 dist.get_rank() 函数来获取当前进程的排名。
15,is_main_process()
目的是检查当前进程是否是主进程。
def is_main_process():
return get_rank() == 016,save_on_master(*args, **kwargs)
用于在主进程上保存模型或其他对象。在分布式计算中,通常只有主进程负责保存模型参数和其他重要信息,以确保保存的模型是完整的且不会发生冲突。
def save_on_master(*args, **kwargs):
if is_main_process():
torch.save(*args, **kwargs)17,init_distributed_mode(args)
初始化分布式计算
def init_distributed_mode(args):
if 'WORLD_SIZE' in os.environ and os.environ['WORLD_SIZE'] != '':
local_world_size = int(os.environ['WORLD_SIZE'])
args.world_size = args.world_size * local_world_size
args.gpu = args.local_rank = int(os.environ['LOCAL_RANK'])
args.rank = args.rank * local_world_size + args.local_rank
print('world size: {}, rank: {}, local rank: {}'.format(args.world_size, args.rank, args.local_rank))
print(json.dumps(dict(os.environ), indent=2))
elif 'SLURM_PROCID' in os.environ:
args.rank = int(os.environ['SLURM_PROCID'])
args.gpu = args.local_rank = int(os.environ['SLURM_LOCALID'])
args.world_size = int(os.environ['SLURM_NPROCS'])
print('world size: {}, world rank: {}, local rank: {}, device_count: {}'.format(args.world_size, args.rank, args.local_rank, torch.cuda.device_count()))
print("os.environ['SLURM_JOB_NODELIST']:", os.environ['SLURM_JOB_NODELIST'])
print(json.dumps(dict(os.environ), indent=2))
print('args:')
print(json.dumps(vars(args), indent=2))
else:
print('Not using distributed mode')
args.distributed = False
args.world_size = 1
args.rank = 0
args.local_rank = 0
return
print("world_size:{} rank:{} local_rank:{}".format(args.world_size, args.rank, args.local_rank))
args.distributed = True
torch.cuda.set_device(args.local_rank)
args.dist_backend = 'nccl'
print('| distributed init (rank {}): {}'.format(args.rank, args.dist_url), flush=True)
torch.distributed.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
print("Before torch.distributed.barrier()")
torch.distributed.barrier()
print("End torch.distributed.barrier()")
setup_for_distributed(args.rank == 0)
解读:
- 将 args.distributed 设置为 True,表示当前处于分布式模式。
- 使用 torch.cuda.set_device(args.gpu) 将当前 GPU 设备设置为 args.gpu。这是为了确保每个进程使用正确的 GPU 设备。
- 设置 args.dist_backend 为 'nccl',这是 PyTorch 中用于分布式计算的后端。
- 使用 torch.distributed.init_process_group 初始化分布式进程组。这个函数会根据传入的参数初始化分布式计算的通信机制,包括进程排名、通信后端、通信初始化方法、世界大小等。
- 调用 torch.distributed.barrier() 来确保所有进程都已初始化完成。分布式计算中,通常需要所有进程都达到某个同步点后才能继续执行后续操作。
- 最后,调用 setup_for_distributed 函数来设置打印输出,确保只有主进程才会打印信息,而其他进程不会打印。
18,accuracy(output, target, topk=(1,))
计算了模型的预测输出 output 与真实标签 target 之间的精度(accuracy),并且支持不同的精度计算,即可以计算前k个预测的精度。
@torch.no_grad()
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
if target.numel() == 0:
return [torch.zeros([], device=output.device)]
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res解读:
- def accuracy(output, target, topk=(1,)):定义了一个函数,它接受三个参数:output(模型的预测输出)、target(真实标签)、topk(一个元组,包含要计算的精度值,默认为1)。
- if target.numel() == 0: 检查真实标签 target 是否为空(即没有元素)。如果没有真实标签,意味着没有可以计算精度的数据,因此返回一个包含零值的张量作为结果,其设备与 output 相同。
- maxk = max(topk)获取 topk 中的最大值,表示要计算的精度的最大值。
- batch_size = target.size(0)获取批处理中的样本数量,即真实标签 target 的第一维大小,通常表示批处理的大小。
- _, pred = output.topk(maxk, 1, True, True)使用 torch.topk 函数找到 output 张量中每个样本的前 maxk 个预测值(按值降序排列)和相应的索引。这里的 _ 是一个占位符,因为我们不需要关注预测值,只需要索引。
- pred = pred.t()对预测索引矩阵进行转置操作,使每一列包含一个样本的前 maxk 个预测的类别索引。
- correct = pred.eq(target.view(1, -1).expand_as(pred))创建一个布尔张量 correct,其形状与 pred 相同,用于表示每个预测是否正确。这里的操作将 target 变换为与 pred 相同的形状,然后与 pred 逐元素比较,返回一个布尔张量,表示哪些预测是正确的。
- res = []创建一个空列表 res 以存储精度结果。
- for k in topk:迭代要计算的不同精度值。
- correct_k = correct[:k].view(-1).float().sum(0)从 correct 布尔张量中选择前 k 个预测的结果,并将其展平成一维张量。然后将布尔值转换为浮点数(True 变为1,False 变为0),并计算它们的和,表示正确的预测数量。
- res.append(correct_k.mul_(100.0 / batch_size))将精度结果(百分比形式)添加到 res 列表中。首先将正确的预测数量除以批处理大小,然后乘以100,以计算精度百分比。这个值被添加到 res 列表中。
- return res返回存储不同精度值的列表 res,每个元素表示对应精度的百分比精度值。
19,interpolate(input, size=None, scale_factor=None, mode="nearest", align_corners=None)
作用是根据输入参数调整输入张量的尺寸,并返回一个新的张量,该张量具有指定的输出尺寸和插值模式。如果输入张量的元素数量为0(即空输入),则函数将返回一个具有指定输出尺寸的空张量。
def interpolate(input, size=None, scale_factor=None, mode="nearest", align_corners=None):
# type: (Tensor, Optional[List[int]], Optional[float], str, Optional[bool]) -> Tensor
"""
Equivalent to nn.functional.interpolate, but with support for empty batch sizes.
This will eventually be supported natively by PyTorch, and this
class can go away.
"""
if __torchvision_need_compat_flag < 0.7:
if input.numel() > 0:
return torch.nn.functional.interpolate(
input, size, scale_factor, mode, align_corners
)
output_shape = _output_size(2, input, size, scale_factor)
output_shape = list(input.shape[:-2]) + list(output_shape)
return _new_empty_tensor(input, output_shape)
else:
return torchvision.ops.misc.interpolate(input, size, scale_factor, mode, align_corners)
解读:
- input(Tensor):输入张量,可以是图像或特征图。
- size(Optional[List[int]]):目标输出的空间大小,通常表示为 [H, W],其中 H 表示高度,W 表示宽度。
- scale_factor(Optional[float]):尺度因子,用于确定输出尺寸相对于输入尺寸的比例。例如,如果 scale_factor=0.5,则输出尺寸将是输入尺寸的一半。
- mode(str):插值模式,用于确定如何进行插值。常见的模式包括:
"nearest":最近邻插值,使用最近的像素值进行插值。
"bilinear":双线性插值,使用四个最近的像素值进行插值。
"bicubic":双三次插值,使用16个最近的像素值进行插值。
- align_corners(Optional[bool]):一个布尔值,确定是否要对齐角点。通常在双线性插值中使用,以确定是否将插值网格的四个角点对齐到输入和输出的角点。
总代码:
"""
Misc functions, including distributed helpers.
Mostly copy-paste from torchvision references.
"""
import os
import random
import subprocess
import time
from collections import OrderedDict, defaultdict, deque
import datetime
import pickle
from typing import Optional, List
import json, time
import numpy as np
import torch
import torch.distributed as dist
from torch import Tensor
import colorsys
import torchvision
__torchvision_need_compat_flag = float(torchvision.__version__.split('.')[1]) < 7
if __torchvision_need_compat_flag:
from torchvision.ops import _new_empty_tensor
from torchvision.ops.misc import _output_size
class SmoothedValue(object):
"""Track a series of values and provide access to smoothed values over a
window or the global series average.
"""
def __init__(self, window_size=20, fmt=None):
if fmt is None:
fmt = "{median:.4f} ({global_avg:.4f})"
self.deque = deque(maxlen=window_size)
self.total = 0.0
self.count = 0
self.fmt = fmt
def update(self, value, n=1):
self.deque.append(value)
self.count += n
self.total += value * n
def synchronize_between_processes(self):
"""
Warning: does not synchronize the deque!
"""
if not is_dist_avail_and_initialized():
return
t = torch.tensor([self.count, self.total], dtype=torch.float64, device='cuda')
dist.barrier()
dist.all_reduce(t)
t = t.tolist()
self.count = int(t[0])
self.total = t[1]
@property
def median(self):
d = torch.tensor(list(self.deque))
if d.shape[0] == 0:
return 0
return d.median().item()
@property
def avg(self):
d = torch.tensor(list(self.deque), dtype=torch.float32)
return d.mean().item()
@property
def global_avg(self):
return self.total / self.count
@property
def max(self):
return max(self.deque)
@property
def value(self):
return self.deque[-1]
def __str__(self):
return self.fmt.format(
median=self.median,
avg=self.avg,
global_avg=self.global_avg,
max=self.max,
value=self.value)
def all_gather(data):
"""
Run all_gather on arbitrary picklable data (not necessarily tensors)
Args:
data: any picklable object
Returns:
list[data]: list of data gathered from each rank
"""
world_size = get_world_size()
if world_size == 1:
return [data]
# serialized to a Tensor
buffer = pickle.dumps(data)
storage = torch.ByteStorage.from_buffer(buffer)
tensor = torch.ByteTensor(storage).to("cuda")
# obtain Tensor size of each rank
local_size = torch.tensor([tensor.numel()], device="cuda")
size_list = [torch.tensor([0], device="cuda") for _ in range(world_size)]
dist.all_gather(size_list, local_size)
size_list = [int(size.item()) for size in size_list]
max_size = max(size_list)
tensor_list = []
for _ in size_list:
tensor_list.append(torch.empty((max_size,), dtype=torch.uint8, device="cuda"))
if local_size != max_size:
padding = torch.empty(size=(max_size - local_size,), dtype=torch.uint8, device="cuda")
tensor = torch.cat((tensor, padding), dim=0)
dist.all_gather(tensor_list, tensor)
data_list = []
for size, tensor in zip(size_list, tensor_list):
buffer = tensor.cpu().numpy().tobytes()[:size]
data_list.append(pickle.loads(buffer))
return data_list
def reduce_dict(input_dict, average=True):
"""
Args:
input_dict (dict): all the values will be reduced
average (bool): whether to do average or sum
Reduce the values in the dictionary from all processes so that all processes
have the averaged results. Returns a dict with the same fields as
input_dict, after reduction.
"""
world_size = get_world_size()
if world_size < 2:
return input_dict
with torch.no_grad():
names = []
values = []
# sort the keys so that they are consistent across processes
for k in sorted(input_dict.keys()):
names.append(k)
values.append(input_dict[k])
values = torch.stack(values, dim=0)
dist.all_reduce(values)
if average:
values /= world_size
reduced_dict = {k: v for k, v in zip(names, values)}
return reduced_dict
class MetricLogger(object):
def __init__(self, delimiter="\t"):
self.meters = defaultdict(SmoothedValue)
self.delimiter = delimiter
def update(self, **kwargs):
for k, v in kwargs.items():
if isinstance(v, torch.Tensor):
v = v.item()
assert isinstance(v, (float, int))
self.meters[k].update(v)
def __getattr__(self, attr):
if attr in self.meters:
return self.meters[attr]
if attr in self.__dict__:
return self.__dict__[attr]
raise AttributeError("'{}' object has no attribute '{}'".format(
type(self).__name__, attr))
def __str__(self):
loss_str = []
for name, meter in self.meters.items():
if meter.count > 0:
loss_str.append(
"{}: {}".format(name, str(meter))
)
return self.delimiter.join(loss_str)
def synchronize_between_processes(self):
for meter in self.meters.values():
meter.synchronize_between_processes()
def add_meter(self, name, meter):
self.meters[name] = meter
def log_every(self, iterable, print_freq, header=None, logger=None):
if logger is None:
print_func = print
else:
print_func = logger.info
i = 0
if not header:
header = ''
start_time = time.time()
end = time.time()
iter_time = SmoothedValue(fmt='{avg:.4f}')
data_time = SmoothedValue(fmt='{avg:.4f}')
space_fmt = ':' + str(len(str(len(iterable)))) + 'd'
if torch.cuda.is_available():
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}',
'max mem: {memory:.0f}'
])
else:
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}'
])
MB = 1024.0 * 1024.0
for obj in iterable:
data_time.update(time.time() - end)
yield obj
# import ipdb; ipdb.set_trace()
iter_time.update(time.time() - end)
if i % print_freq == 0 or i == len(iterable) - 1:
eta_seconds = iter_time.global_avg * (len(iterable) - i)
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
if torch.cuda.is_available():
print_func(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time),
memory=torch.cuda.max_memory_allocated() / MB))
else:
print_func(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time)))
i += 1
end = time.time()
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print_func('{} Total time: {} ({:.4f} s / it)'.format(
header, total_time_str, total_time / len(iterable)))
def get_sha():
cwd = os.path.dirname(os.path.abspath(__file__))
def _run(command):
return subprocess.check_output(command, cwd=cwd).decode('ascii').strip()
sha = 'N/A'
diff = "clean"
branch = 'N/A'
try:
sha = _run(['git', 'rev-parse', 'HEAD'])
subprocess.check_output(['git', 'diff'], cwd=cwd)
diff = _run(['git', 'diff-index', 'HEAD'])
diff = "has uncommited changes" if diff else "clean"
branch = _run(['git', 'rev-parse', '--abbrev-ref', 'HEAD'])
except Exception:
pass
message = f"sha: {sha}, status: {diff}, branch: {branch}"
return message
def collate_fn(batch):
# import ipdb; ipdb.set_trace()
batch = list(zip(*batch))
batch[0] = nested_tensor_from_tensor_list(batch[0])
return tuple(batch)
def _max_by_axis(the_list):
# type: (List[List[int]]) -> List[int]
maxes = the_list[0]
for sublist in the_list[1:]:
for index, item in enumerate(sublist):
maxes[index] = max(maxes[index], item)
return maxes
class NestedTensor(object):
def __init__(self, tensors, mask: Optional[Tensor]):
self.tensors = tensors
self.mask = mask
if mask == 'auto':
self.mask = torch.zeros_like(tensors).to(tensors.device)
if self.mask.dim() == 3:
self.mask = self.mask.sum(0).to(bool)
elif self.mask.dim() == 4:
self.mask = self.mask.sum(1).to(bool)
else:
raise ValueError("tensors dim must be 3 or 4 but {}({})".format(self.tensors.dim(), self.tensors.shape))
def imgsize(self):
res = []
for i in range(self.tensors.shape[0]):
mask = self.mask[i]
maxH = (~mask).sum(0).max()
maxW = (~mask).sum(1).max()
res.append(torch.Tensor([maxH, maxW]))
return res
def to(self, device):
# type: (Device) -> NestedTensor # noqa
cast_tensor = self.tensors.to(device)
mask = self.mask
if mask is not None:
assert mask is not None
cast_mask = mask.to(device)
else:
cast_mask = None
return NestedTensor(cast_tensor, cast_mask)
def to_img_list_single(self, tensor, mask):
assert tensor.dim() == 3, "dim of tensor should be 3 but {}".format(tensor.dim())
maxH = (~mask).sum(0).max()
maxW = (~mask).sum(1).max()
img = tensor[:, :maxH, :maxW]
return img
def to_img_list(self):
"""remove the padding and convert to img list
Returns:
[type]: [description]
"""
if self.tensors.dim() == 3:
return self.to_img_list_single(self.tensors, self.mask)
else:
res = []
for i in range(self.tensors.shape[0]):
tensor_i = self.tensors[i]
mask_i = self.mask[i]
res.append(self.to_img_list_single(tensor_i, mask_i))
return res
@property
def device(self):
return self.tensors.device
def decompose(self):
return self.tensors, self.mask
def __repr__(self):
return str(self.tensors)
@property
def shape(self):
return {
'tensors.shape': self.tensors.shape,
'mask.shape': self.mask.shape
}
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
# TODO make this more general
if tensor_list[0].ndim == 3:
if torchvision._is_tracing():
# nested_tensor_from_tensor_list() does not export well to ONNX
# call _onnx_nested_tensor_from_tensor_list() instead
return _onnx_nested_tensor_from_tensor_list(tensor_list)
# TODO make it support different-sized images
max_size = _max_by_axis([list(img.shape) for img in tensor_list])
# min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list]))
batch_shape = [len(tensor_list)] + max_size
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return NestedTensor(tensor, mask)
@torch.jit.unused
def _onnx_nested_tensor_from_tensor_list(tensor_list: List[Tensor]) -> NestedTensor:
max_size = []
for i in range(tensor_list[0].dim()):
max_size_i = torch.max(torch.stack([img.shape[i] for img in tensor_list]).to(torch.float32)).to(torch.int64)
max_size.append(max_size_i)
max_size = tuple(max_size)
padded_imgs = []
padded_masks = []
for img in tensor_list:
padding = [(s1 - s2) for s1, s2 in zip(max_size, tuple(img.shape))]
padded_img = torch.nn.functional.pad(img, (0, padding[2], 0, padding[1], 0, padding[0]))
padded_imgs.append(padded_img)
m = torch.zeros_like(img[0], dtype=torch.int, device=img.device)
padded_mask = torch.nn.functional.pad(m, (0, padding[2], 0, padding[1]), "constant", 1)
padded_masks.append(padded_mask.to(torch.bool))
tensor = torch.stack(padded_imgs)
mask = torch.stack(padded_masks)
return NestedTensor(tensor, mask=mask)
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print
def is_dist_avail_and_initialized():
if not dist.is_available():
return False
if not dist.is_initialized():
return False
return True
def get_world_size():
if not is_dist_avail_and_initialized():
return 1
return dist.get_world_size()
def get_rank():
if not is_dist_avail_and_initialized():
return 0
return dist.get_rank()
def is_main_process():
return get_rank() == 0
def save_on_master(*args, **kwargs):
if is_main_process():
torch.save(*args, **kwargs)
def init_distributed_mode(args):
if 'WORLD_SIZE' in os.environ and os.environ['WORLD_SIZE'] != '':
local_world_size = int(os.environ['WORLD_SIZE'])
args.world_size = args.world_size * local_world_size
args.gpu = args.local_rank = int(os.environ['LOCAL_RANK'])
args.rank = args.rank * local_world_size + args.local_rank
print('world size: {}, rank: {}, local rank: {}'.format(args.world_size, args.rank, args.local_rank))
print(json.dumps(dict(os.environ), indent=2))
elif 'SLURM_PROCID' in os.environ:
args.rank = int(os.environ['SLURM_PROCID'])
args.gpu = args.local_rank = int(os.environ['SLURM_LOCALID'])
args.world_size = int(os.environ['SLURM_NPROCS'])
print('world size: {}, world rank: {}, local rank: {}, device_count: {}'.format(args.world_size, args.rank, args.local_rank, torch.cuda.device_count()))
print("os.environ['SLURM_JOB_NODELIST']:", os.environ['SLURM_JOB_NODELIST'])
print(json.dumps(dict(os.environ), indent=2))
print('args:')
print(json.dumps(vars(args), indent=2))
else:
print('Not using distributed mode')
args.distributed = False
args.world_size = 1
args.rank = 0
args.local_rank = 0
return
print("world_size:{} rank:{} local_rank:{}".format(args.world_size, args.rank, args.local_rank))
args.distributed = True
torch.cuda.set_device(args.local_rank)
args.dist_backend = 'nccl'
print('| distributed init (rank {}): {}'.format(args.rank, args.dist_url), flush=True)
torch.distributed.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
print("Before torch.distributed.barrier()")
torch.distributed.barrier()
print("End torch.distributed.barrier()")
setup_for_distributed(args.rank == 0)
@torch.no_grad()
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
if target.numel() == 0:
return [torch.zeros([], device=output.device)]
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def interpolate(input, size=None, scale_factor=None, mode="nearest", align_corners=None):
# type: (Tensor, Optional[List[int]], Optional[float], str, Optional[bool]) -> Tensor
"""
Equivalent to nn.functional.interpolate, but with support for empty batch sizes.
This will eventually be supported natively by PyTorch, and this
class can go away.
"""
if __torchvision_need_compat_flag < 0.7:
if input.numel() > 0:
return torch.nn.functional.interpolate(
input, size, scale_factor, mode, align_corners
)
output_shape = _output_size(2, input, size, scale_factor)
output_shape = list(input.shape[:-2]) + list(output_shape)
return _new_empty_tensor(input, output_shape)
else:
return torchvision.ops.misc.interpolate(input, size, scale_factor, mode, align_corners)
class color_sys():
def __init__(self, num_colors) -> None:
self.num_colors = num_colors
colors=[]
for i in np.arange(0., 360., 360. / num_colors):
hue = i/360.
lightness = (50 + np.random.rand() * 10)/100.
saturation = (90 + np.random.rand() * 10)/100.
colors.append(tuple([int(j*255) for j in colorsys.hls_to_rgb(hue, lightness, saturation)]))
self.colors = colors
def __call__(self, idx):
return self.colors[idx]
def inverse_sigmoid(x, eps=1e-3):
x = x.clamp(min=0, max=1)
x1 = x.clamp(min=eps)
x2 = (1 - x).clamp(min=eps)
return torch.log(x1/x2)
def clean_state_dict(state_dict):
new_state_dict = OrderedDict()
for k, v in state_dict.items():
if k[:7] == 'module.':
k = k[7:] # remove `module.`
new_state_dict[k] = v
return new_state_dict陆plot_utils.py(提供一些常用的绘图工具)(可直接复制)
1,plot_logs(logs, fields=('class_error', 'loss_bbox_unscaled', 'mAP'), ewm_col=0, log_name='log.txt')
绘图日志函数
2,plot_precision_recall(files, naming_scheme='iter')
绘制P-R曲线


以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称“P-R曲线”,其代表的是查准率P与查全率R的关系。

总代码:
"""
Plotting utilities to visualize training logs.
"""
import torch
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from pathlib import Path, PurePath
def plot_logs(logs, fields=('class_error', 'loss_bbox_unscaled', 'mAP'), ewm_col=0, log_name='log.txt'):
'''
Function to plot specific fields from training log(s). Plots both training and test results.
:: Inputs - logs = list containing Path objects, each pointing to individual dir with a log file
- fields = which results to plot from each log file - plots both training and test for each field.
- ewm_col = optional, which column to use as the exponential weighted smoothing of the plots
- log_name = optional, name of log file if different than default 'log.txt'.
:: Outputs - matplotlib plots of results in fields, color coded for each log file.
- solid lines are training results, dashed lines are test results.
'''
func_name = "plot_utils.py::plot_logs"
if not isinstance(logs, list):
if isinstance(logs, PurePath):
logs = [logs]
print(f"{func_name} info: logs param expects a list argument, converted to list[Path].")
else:
raise ValueError(f"{func_name} - invalid argument for logs parameter.\n \
Expect list[Path] or single Path obj, received {type(logs)}")
for i, dir in enumerate(logs):
if not isinstance(dir, PurePath):
raise ValueError(f"{func_name} - non-Path object in logs argument of {type(dir)}: \n{dir}")
if not dir.exists():
raise ValueError(f"{func_name} - invalid directory in logs argument:\n{dir}")
# verify log_name exists
fn = Path(dir / log_name)
if not fn.exists():
print(f"-> missing {log_name}. Have you gotten to Epoch 1 in training?")
print(f"--> full path of missing log file: {fn}")
return
# load log file(s) and plot
dfs = [pd.read_json(Path(p) / log_name, lines=True) for p in logs]
fig, axs = plt.subplots(ncols=len(fields), figsize=(16, 5))
for df, color in zip(dfs, sns.color_palette(n_colors=len(logs))):
for j, field in enumerate(fields):
if field == 'mAP':
coco_eval = pd.DataFrame(
np.stack(df.test_coco_eval_bbox.dropna().values)[:, 1]
).ewm(com=ewm_col).mean()
axs[j].plot(coco_eval, c=color)
else:
df.interpolate().ewm(com=ewm_col).mean().plot(
y=[f'train_{field}', f'test_{field}'],
ax=axs[j],
color=[color] * 2,
style=['-', '--']
)
for ax, field in zip(axs, fields):
if field == 'mAP':
ax.legend([Path(p).name for p in logs])
ax.set_title(field)
else:
ax.legend([f'train', f'test'])
ax.set_title(field)
return fig, axs
def plot_precision_recall(files, naming_scheme='iter'):
if naming_scheme == 'exp_id':
# name becomes exp_id
names = [f.parts[-3] for f in files]
elif naming_scheme == 'iter':
names = [f.stem for f in files]
else:
raise ValueError(f'not supported {naming_scheme}')
fig, axs = plt.subplots(ncols=2, figsize=(16, 5))
for f, color, name in zip(files, sns.color_palette("Blues", n_colors=len(files)), names):
data = torch.load(f)
precision = data['precision']
recall = data['params'].recThrs
scores = data['scores']
precision = precision[0, :, :, 0, -1].mean(1)
scores = scores[0, :, :, 0, -1].mean(1)
prec = precision.mean()
rec = data['recall'][0, :, 0, -1].mean()
print(f'{naming_scheme} {name}: mAP@50={prec * 100: 05.1f}, ' +
f'score={scores.mean():0.3f}, ' +
f'f1={2 * prec * rec / (prec + rec + 1e-8):0.3f}'
)
axs[0].plot(recall, precision, c=color)
axs[1].plot(recall, scores, c=color)
axs[0].set_title('Precision / Recall')
axs[0].legend(names)
axs[1].set_title('Scores / Recall')
axs[1].legend(names)
return fig, axs柒time.counter.py
1,time.perf_counter()返回一个表示自程序运行以来经过的时间的浮点数。
2,AverageMeter(object)用来管理一些需要更新的变量,如loss,accuracy,mAP等指标。
直接用其定义一个待更新的变量,初始化时会调用AverageMeter函数中的reset方法
losses = AverageMeter()
调用该函数的update方法时会对相应的变量进行更新
losses.update(loss.data.item())
总代码:
import json
import time
class TimeCounter:
def __init__(self) -> None:
pass
def clear(self):
self.timedict = {}
self.basetime = time.perf_counter()
def timeit(self, name):
nowtime = time.perf_counter() - self.basetime
self.timedict[name] = nowtime
self.basetime = time.perf_counter()
class TimeHolder:
def __init__(self) -> None:
self.timedict = {}
def update(self, _timedict:dict):
for k,v in _timedict.items():
if k not in self.timedict:
self.timedict[k] = AverageMeter(name=k, val_only=True)
self.timedict[k].update(val=v)
def final_res(self):
return {k:v.avg for k,v in self.timedict.items()}
def __str__(self):
return json.dumps(self.final_res(), indent=2)
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f', val_only=False):
self.name = name
self.fmt = fmt
self.val_only = val_only
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
if self.val_only:
fmtstr = '{name} {val' + self.fmt + '}'
else:
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)捌visualizer.py
1,ColorMap类用于生成颜色映射,初始化时可以指定基准RGB颜色,默认为[255, 255, 0]。调用ColorMap实例时,输入一个np.uint8类型的二维数组attnmap,返回一个带有颜色映射的四通道图像,其中颜色映射基于输入的attnmap。
- repeat(a,b,...n)(参数的个数,不能少于被操作的张量的维度的个数),样例如下:
a = torch.randn(33, 55)
a.size()
#torch.Size([33, 55])
a.repeat(1,1).size()
torch.Size([33, 55])
>>> a.repeat(2,1).size()
torch.Size([66, 55])
a.repeat(1,1,1).size() # 原始值:torch.Size([33, 55])
torch.Size([1, 33, 55])
a.repeat(2,1,1).size() # 原始值:torch.Size([33, 55])
torch.Size([2, 33, 55])
a.repeat(1,1,1,1).size() # 原始值:torch.Size([33, 55])
torch.Size([1, 1, 33, 55])
res = res[None][None].repeat(h, 0).repeat(w, 1)
- np.concatenate()
函数接收以下参数:
1,(a1, a2, ...):要合并的数组序列,以元组形式传入。(沿着默认的轴 0 进行合并)
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.concatenate((a, b))
print(c)
#输出结果为:[1 2 3 4 5 6]。2,axis:指定合并的轴,即沿着哪个维度进行合并。默认值为 0,表示沿着第一个维度进行合并。
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
c = np.concatenate((a, b), axis=1)
print(c)
#输出结果为:
[[1 2 5 6]
[3 4 7 8]]3,out:指定输出数组的可选参数。
res = np.concatenate((res, attn1), axis=-1).astype(np.uint8)
2,rainbow_text函数用于在图中显示彩虹文本,可以水平或垂直显示一组字符串ls,每个字符串对应一个颜色lc。函数会将字符串按顺序显示在指定的位置(x, y),并根据对应的颜色进行着色。
-
plt.gca().transData,调用plt.gca()函数获取当前的坐标轴实例,再调用实例的transData、transAxes、transFigure等方法可以将坐标系转换到不同的坐标系。
数据坐标系(Data):默认情况下,绘图中所使用的坐标系即是数据坐标系。该坐标系以数据本身为基准,比如以x轴为例,x轴上的数据点会被映射到以x轴为基准的数值范围内展示。
坐标轴坐标系(Axes):坐标轴坐标系即为以整个坐标轴中的点为基准,x轴的范围为[0, 1],y轴的范围为[0, 1]。因此,如果我们想在图中表达的信息可能不能按照数据的值进行展示,而是想表达一些相对信息时,可以使用坐标轴坐标系。
ax = plt.gca() # 获取当前坐标轴实例
ax.spines['right'].set_color('none') # 去掉右边界线
ax.spines['top'].set_color('none') # 去掉上边界线
ax.xaxis.set_ticks_position('bottom') # 移动x轴下标
ax.spines['bottom'].set_position(('data', 0)) # 移动x轴下标到y轴0刻度上
ax.yaxis.set_ticks_position('left') # 移动y轴左标
ax.spines['left'].set_position(('data', 0)) # 移动y轴左标到x轴0刻度上
x = np.linspace(-np.pi, np.pi, 300, endpoint=True) # 设置x轴范围及分割数量
y = np.sin(x) # 定义y轴上的数据
plt.plot(x, y, color='blue', linewidth=2.0, linestyle='-', alpha=0.8) # 绘制函数图像
plt.xlim(x.min()*1.1, x.max()*1.1) # 设置x轴坐标范围
plt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi],
[r'$-\pi$', r'$-\frac{\pi}{2}$', r'$0$', r'$\frac{\pi}{2}$', r'$+\pi$']) # 设置x轴刻度标签
plt.ylim(y.min()*1.1, y.max()*1.1) # 设置y轴坐标范围
plt.yticks(np.linspace(-1, 1, num=5, endpoint=True)) # 设置y轴刻度标签
for label in ax.get_xticklabels() + ax.get_yticklabels():
label.set_fontsize(16)
label.set_bbox(dict(facecolor='white', edgecolor='None', alpha=0.65 ))
# 设置刻度标签外边框图形坐标系(Figure):图形坐标系是以整个绘图区域(figure)为基准的坐标系。以x轴为例,x轴的范围为[0, 1],表示在绘图区域中该轴的占比情况。
fig = plt.figure(dpi=120, figsize=(8, 6)) # 设置绘图区域大小及分辨率
plt.plot(x, y, color='blue', linewidth=2.0, linestyle='-', alpha=0.8) # 绘制函数图像
plt.xlim(x.min()*1.1, x.max()*1.1) # 设置x轴坐标范围
plt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi],
[r'$-\pi$', r'$-\frac{\pi}{2}$', r'$0$', r'$\frac{\pi}{2}$', r'$+\pi$']) # 设置x轴刻度标签
plt.ylim(y.min()*1.1, y.max()*1.1) # 设置y轴坐标范围
plt.yticks(np.linspace(-1, 1, num=5, endpoint=True)) # 设置y轴刻度标签
ax = plt.gca() # 获取当前坐标轴实例
ax.spines['right'].set_color('none') # 去掉右边界线
ax.spines['top'].set_color('none') # 去掉上边界线
ax.xaxis.set_ticks_position('bottom') # 移动x轴下标
ax.spines['bottom'].set_position(('data', 0)) # 移动x轴下标到y轴0刻度上
ax.yaxis.set_ticks_position('left') # 移动y轴左标
ax.spines['left'].set_position(('data', 0)) # 移动y轴左标到x轴0刻度上
for label in ax.get_xticklabels() + ax.get_yticklabels():
label.set_fontsize(16)
label.set_bbox(dict(facecolor='white', edgecolor='None', alpha=0.65 ))
# 设置刻度标签外边框- plt.gcf() 和plt.gca()分别表示Get Current Figure 和Get Current Axes 。在pyplot 模块中,许多函数都是对当前的Figure 或Axes 对象进行处理,比如:plt.plot() 实际上会通过plt.gca() 获得当前的Axes 对象ax ,然后再调用ax.plot() 方法实现真正的绘图。
-
plt.text(x, y, s, fontsize, verticalalignment,horizontalalignment,rotation , **kwargs)
- x,y表示标签添加的位置,默认是根据坐标轴的数据来度量的,是绝对值,也就是说图中点所在位置的对应的值,如果要变换坐标系的话,要用transform=ax.transAxes参数。
- s表示标签的符号,字符串格式
- fontsize顾名思义就是你加标签字体大小了,取整数。
- verticalalignment表示垂直对齐方式 ,可选 ‘center’ ,‘top’ , ‘bottom’,‘baseline’ 等
- horizontalalignment表示水平对齐方式 ,可以填 ‘center’ , ‘right’ ,‘left’ 等
- rotation表示标签的旋转角度,以逆时针计算,取整
- 还有 family 用来设置字体,style 设置字体的风格,weight 字体的粗细, bbox 给字体添加框,如 bbox=dict(facecolor='red', alpha=0.5) 等。
-
get_window_extent(renderer=None)获取显示空间中的轴边界框。
- transforms.offset_copy(),将绘图元素(如文本字符串)放置在屏幕坐标(点或英寸)中相对于任何坐标中给定位置的指定偏移处。
3,COCOVisualizer是一个用于可视化COCO数据的类。
__init__(self, coco=None, tokenlizer=None):类的初始化方法,接受两个参数coco和tokenlizer。coco是一个COCO数据集对象,tokenlizer是一个标记化器对象。-
visualize方法用于将图像和目标检测结果可视化,并保存为图片。其中img是输入的图像张量,tgt是目标检测结果,caption是可选的标题,dpi是图片分辨率,savedir是保存路径。
-
addtgt方法用于在图像上添加目标检测结果的边界框、关键点等信息。
-
showAnns方法用于显示指定的注释信息,包括实例分割、关键点等。根据注释的类型不同(instances或captions),采取不同的显示方式。
总代码:
# -*- coding: utf-8 -*-
'''
@File : visualizer.py
@Author : Jie Yang
'''
import os, sys
from textwrap import wrap
import torch
import numpy as np
import cv2
import datetime
import matplotlib.pyplot as plt
from matplotlib.collections import PatchCollection
from matplotlib.patches import Polygon
from pycocotools import mask as maskUtils
from matplotlib import transforms
from util.utils import renorm
class ColorMap():
def __init__(self, basergb=[255, 255, 0]):
self.basergb = np.array(basergb)
def __call__(self, attnmap):
# attnmap: h, w. np.uint8.
# return: h, w, 4. np.uint8.
assert attnmap.dtype == np.uint8
h, w = attnmap.shape
res = self.basergb.copy()
res = res[None][None].repeat(h, 0).repeat(w, 1) # h, w, 3
attn1 = attnmap.copy()[..., None] # h, w, 1
res = np.concatenate((res, attn1), axis=-1).astype(np.uint8)
return res
def rainbow_text(x, y, ls, lc, **kw):
"""
Take a list of strings ``ls`` and colors ``lc`` and place them next to each
other, with text ls[i] being shown in color lc[i].
This example shows how to do both vertical and horizontal text, and will
pass all keyword arguments to plt.text, so you can set the font size,
family, etc.
"""
t = plt.gca().transData
fig = plt.gcf()
plt.show()
# horizontal version
for s, c in zip(ls, lc):
text = plt.text(x, y, " " + s + " ", color=c, transform=t, **kw)
text.draw(fig.canvas.get_renderer())
ex = text.get_window_extent()
t = transforms.offset_copy(text._transform, x=ex.width, units='dots')
class COCOVisualizer():
def __init__(self, coco=None, tokenlizer=None) -> None:
self.coco = coco
def visualize(self, img, tgt, caption=None, dpi=180, savedir='vis'):
"""
img: tensor(3, H, W)
tgt: make sure they are all on cpu.
must have items: 'image_id', 'boxes', 'size'
"""
img = renorm(img).permute(1, 2, 0)
fig=plt.figure(frameon=False)
dpi = plt.gcf().dpi
fig.set_size_inches(img.shape[1] / dpi, img.shape[0] / dpi)
plt.subplots_adjust(left=0, right=1, top=1, bottom=0)
ax = plt.gca()
ax.imshow(img, aspect='equal')
self.addtgt(tgt)
if caption is None:
savename = '{}/{}-{}.png'.format(savedir, int(tgt['image_id']),
str(datetime.datetime.now()).replace(' ', '-'))
else:
savename = '{}/{}-{}-{}.png'.format(savedir, caption, int(tgt['image_id']),
str(datetime.datetime.now()).replace(' ', '-'))
print("savename: {}".format(savename))
os.makedirs(os.path.dirname(savename), exist_ok=True)
plt.savefig(savename, dpi=dpi)
plt.close()
def addtgt(self, tgt):
"""
"""
assert 'boxes' in tgt
ax = plt.gca()
H, W = tgt['size'].tolist()
ax.set_xlim(0, W)
ax.set_ylim(H, 0)
ax.set_aspect('equal')
numbox = tgt['boxes'].shape[0]
color_kpt = [[0.00, 0.00, 0.00],
[1.00, 1.00, 1.00],
[1.00, 0.00, 0.00],
[1.00, 1, 00., 0.00],
[0.50, 0.16, 0.16],
[0.00, 0.00, 1.00],
[0.69, 0.88, 0.90],
[0.00, 1.00, 0.00],
[0.63, 0.13, 0.94],
[0.82, 0.71, 0.55],
[1.00, 0.38, 0.00],
[0.53, 0.15, 0.34],
[1.00, 0.39, 0.28],
[1.00, 0.00, 1.00],
[0.04, 0.09, 0.27],
[0.20, 0.63, 0.79],
[0.94, 0.90, 0.55]]
color = []
color_box= [0.49,0.99,0]
color_kpt_bbox = []
polygons_kpt = []
boxes_kpt = []
polygons = []
boxes = []
for box in tgt['boxes'].cpu():
unnormbbox = box * torch.Tensor([W, H, W, H])
unnormbbox[:2] -= unnormbbox[2:] / 2
[bbox_x, bbox_y, bbox_w, bbox_h] = unnormbbox.tolist()
boxes.append([bbox_x, bbox_y, bbox_w, bbox_h])
poly = [[bbox_x, bbox_y], [bbox_x, bbox_y + bbox_h], [bbox_x + bbox_w, bbox_y + bbox_h],
[bbox_x + bbox_w, bbox_y]]
np_poly = np.array(poly).reshape((4, 2))
polygons.append(Polygon(np_poly))
# c = (np.random.random((1, 3)) * 0.6 + 0.4).tolist()[0]
color.append(color_box)
p = PatchCollection(polygons, facecolor=color, linewidths=0, alpha=0.1)
ax.add_collection(p)
p = PatchCollection(polygons, facecolor='none',linestyle="--", edgecolors=color, linewidths=1.5)
ax.add_collection(p)
if 'strings_positive' in tgt:
assert len(tgt['strings_positive']) == numbox, f"{len(tgt['strings_positive'])} = {numbox}, "
for idx, strlist in enumerate(tgt['strings_positive']):
cate_id = int(tgt['labels'][idx])
_string = str(cate_id) + ':' + ' '.join(strlist)
bbox_x, bbox_y, bbox_w, bbox_h = boxes[idx]
# ax.text(bbox_x, bbox_y, _string, color='black', bbox={'facecolor': 'yellow', 'alpha': 1.0, 'pad': 1})
ax.text(bbox_x, bbox_y, _string, color='black', bbox={'facecolor': color[idx], 'alpha': 0.6, 'pad': 1})
if 'box_label' in tgt:
assert len(tgt['box_label']) == numbox, f"{len(tgt['box_label'])} = {numbox}, "
for idx, bl in enumerate(tgt['box_label']):
_string = str(bl)
bbox_x, bbox_y, bbox_w, bbox_h = boxes[idx]
# ax.text(bbox_x, bbox_y, _string, color='black', bbox={'facecolor': 'yellow', 'alpha': 1.0, 'pad': 1})
ax.text(bbox_x, bbox_y, _string, color='black', bbox={'facecolor': color[idx], 'alpha': 0.6, 'pad': 1})
if 'caption' in tgt:
ax.set_title(tgt['caption'], wrap=True)
if 'attn' in tgt:
if isinstance(tgt['attn'], tuple):
tgt['attn'] = [tgt['attn']]
for item in tgt['attn']:
attn_map, basergb = item
attn_map = (attn_map - attn_map.min()) / (attn_map.max() - attn_map.min() + 1e-3)
attn_map = (attn_map * 255).astype(np.uint8)
cm = ColorMap(basergb)
heatmap = cm(attn_map)
ax.imshow(heatmap)
if 'keypoints' in tgt:
sks = np.array(self.coco.loadCats(1)[0]['skeleton']) - 1
for idx, ann in enumerate(tgt['keypoints']):
if "kpt_bbox" in tgt:
for kpt_bbox in tgt['kpt_bbox'][idx].cpu():
unnormbbox = kpt_bbox * torch.Tensor([W, H, W, H])
unnormbbox[:2] -= unnormbbox[2:] / 2
[bbox_x, bbox_y, bbox_w, bbox_h] = unnormbbox.tolist()
boxes_kpt.append([bbox_x, bbox_y, bbox_w, bbox_h])
poly = [[bbox_x, bbox_y], [bbox_x, bbox_y + bbox_h], [bbox_x + bbox_w, bbox_y + bbox_h],
[bbox_x + bbox_w, bbox_y]]
np_poly = np.array(poly).reshape((4, 2))
polygons_kpt.append(Polygon(np_poly))
color_kpt_bbox.append(color_box)
p_kpt = PatchCollection(polygons_kpt, facecolor=color_kpt, linewidths=0, alpha=0.1)
ax.add_collection(p_kpt)
p_kpt = PatchCollection(polygons_kpt, facecolor='none', edgecolors=color_kpt, linewidths=1)
ax.add_collection(p_kpt)
kp = np.array(ann.cpu())
Z = kp[:34] * np.array([W, H] * 17)
V = kp[34:]
x = Z[0::2]
y = Z[1::2]
v = V
if len(color) > 0:
c = color[idx % len(color)]
else:
c = (np.random.random((1, 3)) * 0.6 + 0.4).tolist()[0]
for sk in sks:
if np.all(v[sk] > 0):
plt.plot(x[sk], y[sk], linewidth=2, color=c)
for i in range(17):
c_kpt = color_kpt[i]
plt.plot(x[i], y[i], 'o', markersize=6, markerfacecolor=c_kpt, markeredgecolor='k', markeredgewidth=0.5)
ax.set_axis_off()
def showAnns(self, anns, draw_bbox=False):
"""
Display the specified annotations.
:param anns (array of object): annotations to display
:return: None
"""
if len(anns) == 0:
return 0
if 'segmentation' in anns[0] or 'keypoints' in anns[0]:
datasetType = 'instances'
elif 'caption' in anns[0]:
datasetType = 'captions'
else:
raise Exception('datasetType not supported')
if datasetType == 'instances':
ax = plt.gca()
ax.set_autoscale_on(False)
polygons = []
color = []
for ann in anns:
c = (np.random.random((1, 3)) * 0.6 + 0.4).tolist()[0]
if 'segmentation' in ann:
if type(ann['segmentation']) == list:
# polygon
for seg in ann['segmentation']:
poly = np.array(seg).reshape((int(len(seg) / 2), 2))
polygons.append(Polygon(poly))
color.append(c)
else:
# mask
t = self.imgs[ann['image_id']]
if type(ann['segmentation']['counts']) == list:
rle = maskUtils.frPyObjects([ann['segmentation']], t['height'], t['width'])
else:
rle = [ann['segmentation']]
m = maskUtils.decode(rle)
img = np.ones((m.shape[0], m.shape[1], 3))
if ann['iscrowd'] == 1:
color_mask = np.array([2.0, 166.0, 101.0]) / 255
if ann['iscrowd'] == 0:
color_mask = np.random.random((1, 3)).tolist()[0]
for i in range(3):
img[:, :, i] = color_mask[i]
ax.imshow(np.dstack((img, m * 0.5)))
if 'keypoints' in ann and type(ann['keypoints']) == list:
# turn skeleton into zero-based index
sks = np.array(self.loadCats(ann['category_id'])[0]['skeleton']) - 1
kp = np.array(ann['keypoints'])
x = kp[0::3]
y = kp[1::3]
v = kp[2::3]
for sk in sks:
if np.all(v[sk] > 0):
plt.plot(x[sk], y[sk], linewidth=3, color=c)
plt.plot(x[v > 0], y[v > 0], 'o', markersize=8, markerfacecolor=c, markeredgecolor='k',
markeredgewidth=2)
plt.plot(x[v > 1], y[v > 1], 'o', markersize=8, markerfacecolor=c, markeredgecolor=c,
markeredgewidth=2)
if draw_bbox:
[bbox_x, bbox_y, bbox_w, bbox_h] = ann['bbox']
poly = [[bbox_x, bbox_y], [bbox_x, bbox_y + bbox_h], [bbox_x + bbox_w, bbox_y + bbox_h],
[bbox_x + bbox_w, bbox_y]]
np_poly = np.array(poly).reshape((4, 2))
polygons.append(Polygon(np_poly))
color.append(c)
p = PatchCollection(polygons, facecolor='none', edgecolors=color, linewidths=2)
ax.add_collection(p)
elif datasetType == 'captions':
for ann in anns:
print(ann['caption'])
镹vis_utils.py
1,add_box_to_img函数用于在图像上添加边界框,并可选择添加文本标签。接受图像img、边界框列表boxes、颜色列表colorlist和文本标签列表brands作为输入,返回添加了边界框和文本标签后的图像。
2,plot_dual_img函数用于在图像上绘制不同类别的边界框,并可选择添加类别标签和序列标签。接受图像img、边界框列表boxes、类别列表labels、序列列表idxs和概率列表probs作为输入,返回添加了类别标签和序列标签后的两幅图像。
3,plot_raw_img函数用于在图像上绘制原始的边界框和标签。接受图像img、边界框列表boxes和类别列表labels作为输入,返回添加了边界框和标签后的图像。
总代码:
import cv2
import numpy as np
from util.utils import renorm
from util.misc import color_sys
_color_getter = color_sys(100)
# plot known and unknown box
def add_box_to_img(img, boxes, colorlist, brands=None):
"""[summary]
Args:
img ([type]): np.array, H,W,3
boxes ([type]): list of list(4)
colorlist: list of colors.
brands: text.
Return:
img: np.array. H,W,3.
"""
H, W = img.shape[:2]
for _i, (box, color) in enumerate(zip(boxes, colorlist)):
x, y, w, h = box[0] * W, box[1] * H, box[2] * W, box[3] * H
img = cv2.rectangle(img.copy(), (int(x-w/2), int(y-h/2)), (int(x+w/2), int(y+h/2)), color, 2)
if brands is not None:
brand = brands[_i]
org = (int(x-w/2), int(y+h/2))
font = cv2.FONT_HERSHEY_SIMPLEX
fontScale = 0.5
thickness = 1
img = cv2.putText(img.copy(), str(brand), org, font,
fontScale, color, thickness, cv2.LINE_AA)
return img
def plot_dual_img(img, boxes, labels, idxs, probs=None):
"""[summary]
Args:
img ([type]): 3,H,W. tensor.
boxes (): tensor(Kx4) or list of tensor(1x4).
labels ([type]): list of ints.
idxs ([type]): list of ints.
probs (optional): listof floats.
Returns:
img_classcolor: np.array. H,W,3. img with class-wise label.
img_seqcolor: np.array. H,W,3. img with seq-wise label.
"""
# import ipdb; ipdb.set_trace()
boxes = [i.cpu().tolist() for i in boxes]
img = (renorm(img.cpu()).permute(1,2,0).numpy() * 255).astype(np.uint8)
# plot with class
class_colors = [_color_getter(i) for i in labels]
if probs is not None:
brands = ["{},{:.2f}".format(j,k) for j,k in zip(labels, probs)]
else:
brands = labels
img_classcolor = add_box_to_img(img, boxes, class_colors, brands=brands)
# plot with seq
seq_colors = [_color_getter((i * 11) % 100) for i in idxs]
img_seqcolor = add_box_to_img(img, boxes, seq_colors, brands=idxs)
return img_classcolor, img_seqcolor
def plot_raw_img(img, boxes, labels):
"""[summary]
Args:
img ([type]): 3,H,W. tensor.
boxes ([type]): Kx4. tensor
labels ([type]): K. tensor.
return:
img: np.array. H,W,3. img with bbox annos.
"""
img = (renorm(img.cpu()).permute(1,2,0).numpy() * 255).astype(np.uint8)
H, W = img.shape[:2]
for box, label in zip(boxes.tolist(), labels.tolist()):
x, y, w, h = box[0] * W, box[1] * H, box[2] * W, box[3] * H
# import ipdb; ipdb.set_trace()
img = cv2.rectangle(img.copy(), (int(x-w/2), int(y-h/2)), (int(x+w/2), int(y+h/2)), _color_getter(label), 2)
# add text
org = (int(x-w/2), int(y+h/2))
font = cv2.FONT_HERSHEY_SIMPLEX
fontScale = 1
thickness = 1
img = cv2.putText(img.copy(), str(label), org, font,
fontScale, _color_getter(label), thickness, cv2.LINE_AA)
return img拾utils.py
1,clean_state_dict(state_dict),作用是去除PyTorch模型状态字典中键名中的`'module.'`前缀,使得状态字典可以在不同的模型之间进行加载和使用。
- 函数首先创建了一个新的有序字典`new_state_dict`,用于存储清理后的状态字典。
- 然后遍历输入的`state_dict`字典的键值对,对于每个键值对,判断键是否以`'module.'`开头,如果是的话,就将`'module.'`去掉然后将新的键值对存入`new_state_dict`中。
- 最终函数返回清理后的新状态字典`new_state_dict`。
def clean_state_dict(state_dict):
new_state_dict = OrderedDict()
for k, v in state_dict.items():
if k[:7] == 'module.':
k = k[7:] # remove `module.`
new_state_dict[k] = v
return new_state_dict2,renorm,作用是对输入的图像进行重新归一化处理,使得图像的像素值符合指定的均值和标准差。函数接受一个torch.FloatTensor类型的图像张量img作为输入,同时可以指定均值mean和标准差std。函数的返回值也是一个torch.FloatTensor类型的图像张量,与输入图像相同。
- 函数首先通过断言语句确保输入图像的维度为3或4,如果不是则会抛出异常。接着根据输入图像的维度进行不同的处理
- 如果输入图像的维度为3,且通道数为3,函数会将图像通道顺序调整为(H,W,3),然后根据给定的均值和标准差对图像进行重新归一化处理,最后将通道顺序调整回来并返回处理后的图像。
- 如果输入图像的维度为4,且通道数为3,函数会将图像通道顺序调整为(B,H,W,3),然后同样根据给定的均值和标准差对图像进行重新归一化处理,最后将通道顺序调整回来并返回处理后的图像。
def renorm(img: torch.FloatTensor, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) \
-> torch.FloatTensor:
# img: tensor(3,H,W) or tensor(B,3,H,W)
# return: same as img
assert img.dim() == 3 or img.dim() == 4, "img.dim() should be 3 or 4 but %d" % img.dim()
if img.dim() == 3:
assert img.size(0) == 3, 'img.size(0) shoule be 3 but "%d". (%s)' % (img.size(0), str(img.size()))
img_perm = img.permute(1, 2, 0)
mean = torch.Tensor(mean)
std = torch.Tensor(std)
img_res = img_perm * std + mean
return img_res.permute(2, 0, 1)
else: # img.dim() == 4
assert img.size(1) == 3, 'img.size(1) shoule be 3 but "%d". (%s)' % (img.size(1), str(img.size()))
img_perm = img.permute(0, 2, 3, 1)
mean = torch.Tensor(mean)
std = torch.Tensor(std)
img_res = img_perm * std + mean
return img_res.permute(0, 3, 1, 2)3,class CocoClassMapper()用于将COCO数据集中的类别映射为紧凑的类别索引。通过这个类,可以方便地进行原始类别和紧凑类别索引之间的转换,便于在模型训练和推理过程中使用不同的类别表示。
1. `__init__(self)`:初始化方法,定义了三个字典属性`category_map_str`、`origin2compact_mapper`和`compact2origin_mapper`,分别用于存储原始类别到紧凑类别索引的映射关系。其中`category_map_str`存储了原始类别到紧凑类别索引的映射关系,`origin2compact_mapper`存储了原始类别到紧凑类别索引的映射关系,`compact2origin_mapper`存储了紧凑类别索引到原始类别的映射关系。
2. `origin2compact(self, idx)`:接受一个原始类别索引作为输入,返回对应的紧凑类别索引。
3. `compact2origin(self, idx)`:接受一个紧凑类别索引作为输入,返回对应的原始类别索引。
class CocoClassMapper():
def __init__(self) -> None:
self.category_map_str = {"1": 1, "2": 2, "3": 3, "4": 4, "5": 5, "6": 6, "7": 7, "8": 8, "9": 9, "10": 10,
"11": 11, "13": 12, "14": 13, "15": 14, "16": 15, "17": 16, "18": 17, "19": 18,
"20": 19, "21": 20, "22": 21, "23": 22, "24": 23, "25": 24, "27": 25, "28": 26,
"31": 27, "32": 28, "33": 29, "34": 30, "35": 31, "36": 32, "37": 33, "38": 34,
"39": 35, "40": 36, "41": 37, "42": 38, "43": 39, "44": 40, "46": 41, "47": 42,
"48": 43, "49": 44, "50": 45, "51": 46, "52": 47, "53": 48, "54": 49, "55": 50,
"56": 51, "57": 52, "58": 53, "59": 54, "60": 55, "61": 56, "62": 57, "63": 58,
"64": 59, "65": 60, "67": 61, "70": 62, "72": 63, "73": 64, "74": 65, "75": 66,
"76": 67, "77": 68, "78": 69, "79": 70, "80": 71, "81": 72, "82": 73, "84": 74,
"85": 75, "86": 76, "87": 77, "88": 78, "89": 79, "90": 80}
self.origin2compact_mapper = {int(k): v - 1 for k, v in self.category_map_str.items()}
self.compact2origin_mapper = {int(v - 1): int(k) for k, v in self.category_map_str.items()}
def origin2compact(self, idx):
return self.origin2compact_mapper[int(idx)]
def compact2origin(self, idx):
return self.compact2origin_mapper[int(idx)]4,to_device(item, device)用于将输入的数据结构中的所有`torch.Tensor`对象移动到指定的设备上。
- 如果输入的`item`是`torch.Tensor`类型,则将其移动到指定的`device`上。
- 如果输入的`item`是`list`类型,则递归地对列表中的每个元素调用`to_device`函数,并返回移动后的列表。
- 如果输入的`item`是`dict`类型,则递归地对字典中的每个值调用`to_device`函数,并返回移动后的字典。
- 如果输入的`item`不是`torch.Tensor`、`list`或`dict`类型,则抛出`NotImplementedError`异常,提示用户使用了不支持的数据结构。
def to_device(item, device):
if isinstance(item, torch.Tensor):
return item.to(device)
elif isinstance(item, list):
return [to_device(i, device) for i in item]
elif isinstance(item, dict):
return {k: to_device(v, device) for k, v in item.items()}
else:
raise NotImplementedError("You use other containers! type: {}".format(type(item)))
5,get_gaussian_mean(x, axis, other_axis, softmax=True),用于计算输入张量`x`在指定轴`axis`上的加权均值。
- `x`是输入的张量,形状为(BxCxHxW),其中B表示batch size,C表示通道数,H和W分别表示高度和宽度。
- `axis`是用于加权平均的轴的索引。
- `other_axis`是另一个轴的索引,用于在计算加权平均前对张量进行求和。
- `softmax`是一个布尔值,表示是否对计算得到的加权平均进行softmax操作。
- 函数首先对输入张量在`other_axis`上进行求和,得到`mat2line`。
- 然后根据`softmax`参数的取值,对`mat2line`进行softmax操作或者归一化操作,得到权重`u`。
- 接着创建一个等差数列`ind`,并根据输入张量的形状构造出相应的索引张量`index`。
- 最后,计算加权平均的位置`mean_position`,并返回结果。
def get_gaussian_mean(x, axis, other_axis, softmax=True):
"""
Args:
x (float): Input images(BxCxHxW)
axis (int): The index for weighted mean
other_axis (int): The other index
Returns: weighted index for axis, BxC
"""
mat2line = torch.sum(x, axis=other_axis)
# mat2line = mat2line / mat2line.mean() * 10
if softmax:
u = torch.softmax(mat2line, axis=2)
else:
u = mat2line / (mat2line.sum(2, keepdim=True) + 1e-6)
size = x.shape[axis]
ind = torch.linspace(0, 1, size).to(x.device)
batch = x.shape[0]
channel = x.shape[1]
index = ind.repeat([batch, channel, 1])
mean_position = torch.sum(index * u, dim=2)
return mean_position
6,get_expected_points_from_map(hm, softmax=True),用于从输入的热图(heat map)张量中获取期望的点位置。
- `hm`是输入的热图张量,形状为(BxCxHxW),其中B表示batch size,C表示通道数,H和W分别表示高度和宽度。
- `softmax`是一个布尔值,表示是否在计算加权平均值时使用softmax函数。
- 函数首先调用`get_gaussian_mean`函数两次,分别计算在水平方向和垂直方向上的加权平均位置`x_mean`和`y_mean`。
- 然后将这两个位置张量按照最后一个维度(通道维度)进行堆叠,得到形状为BxCx2的张量,其中每个通道包含了对应的期望点的x和y坐标。
def get_expected_points_from_map(hm, softmax=True):
"""get_gaussian_map_from_points
B,C,H,W -> B,N,2 float(0, 1) float(0, 1)
softargmax function
Args:
hm (float): Input images(BxCxHxW)
Returns:
weighted index for axis, BxCx2. float between 0 and 1.
"""
# hm = 10*hm
B, C, H, W = hm.shape
y_mean = get_gaussian_mean(hm, 2, 3, softmax=softmax) # B,C
x_mean = get_gaussian_mean(hm, 3, 2, softmax=softmax) # B,C
# return torch.cat((x_mean.unsqueeze(-1), y_mean.unsqueeze(-1)), 2)
return torch.stack([x_mean, y_mean], dim=2)
7,class Embedder,用于实现位置编码。通过将不同频率的周期函数应用于输入数据,实现对输入数据的编码。
- - `__init__`方法用于初始化`Embedder`类的实例,接受一个字典作为参数,并将参数保存在`self.kwargs`中,然后调用`create_embedding_fn`方法创建嵌入函数。
- - `create_embedding_fn`方法根据传入的参数设置嵌入函数,其中包括输入维度、是否包含输入、最大频率、频率数量、是否使用对数采样等参数。根据这些参数,创建不同的嵌入函数并保存在`embed_fns`列表中。
- - `embed`方法接受输入`inputs`,并对其应用所有嵌入函数,然后将结果在最后一个维度上进行拼接,并返回拼接后的张量。
# Positional encoding (section 5.1)
# borrow from nerf
class Embedder:
def __init__(self, **kwargs):
self.kwargs = kwargs
self.create_embedding_fn()
def create_embedding_fn(self):
embed_fns = []
d = self.kwargs['input_dims']
out_dim = 0
if self.kwargs['include_input']:
embed_fns.append(lambda x: x)
out_dim += d
max_freq = self.kwargs['max_freq_log2']
N_freqs = self.kwargs['num_freqs']
if self.kwargs['log_sampling']:
freq_bands = 2. ** torch.linspace(0., max_freq, steps=N_freqs)
else:
freq_bands = torch.linspace(2. ** 0., 2. ** max_freq, steps=N_freqs)
for freq in freq_bands:
for p_fn in self.kwargs['periodic_fns']:
embed_fns.append(lambda x, p_fn=p_fn, freq=freq: p_fn(x * freq))
out_dim += d
self.embed_fns = embed_fns
self.out_dim = out_dim
def embed(self, inputs):
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
8,get_embedder(multires, i=0),用于获取一个嵌入器(embedder)函数和对应的输出维度。
- - 如果`i`的取值为-1,则函数返回一个`nn.Identity()`对象和输出维度为3,即返回一个恒等映射和输出维度为3的情况。
- - 否则,根据传入的`multires`参数和预先设定的`embed_kwargs`字典,创建一个`Embedder`对象`embedder_obj`,并定义一个lambda函数`embed`,该函数接受输入`x`并调用`embedder_obj`的`embed`方法对其进行编码。
- - 最后,函数返回这个lambda函数`embed`和`embedder_obj`的输出维度`embedder_obj.out_dim`。
def get_embedder(multires, i=0):
import torch.nn as nn
if i == -1:
return nn.Identity(), 3
embed_kwargs = {
'include_input': True,
'input_dims': 3,
'max_freq_log2': multires - 1,
'num_freqs': multires,
'log_sampling': True,
'periodic_fns': [torch.sin, torch.cos],
}
embedder_obj = Embedder(**embed_kwargs)
embed = lambda x, eo=embedder_obj: eo.embed(x)
return embed, embedder_obj.out_dim
9,class APOPMeter,用于计算二分类问题中的混淆矩阵指标,包括真正例(True Positives)、假正例(False Positives)、真负例(True Negatives)和假负例(False Negatives)。
- - `__init__`方法用于初始化`APOPMeter`类的实例,初始化了四个计数器`tp`、`fp`、`tn`和`fn`,分别表示真正例、假正例、真负例和假负例的数量。
- - `update`方法接受预测值`pred`和真实标签`gt`作为输入,首先确保`pred`和`gt`的形状相同,然后根据预测值和真实标签更新计数器`tp`、`fp`、`tn`和`fn`,分别计算真正例、假正例、真负例和假负例的数量。
- - `update_cm`方法接受混淆矩阵中的四个值`tp`、`fp`、`tn`和`fn`作为输入,直接将这些值加到对应的计数器中,用于更新混淆矩阵指标。
class APOPMeter():
def __init__(self) -> None:
self.tp = 0
self.fp = 0
self.tn = 0
self.fn = 0
def update(self, pred, gt):
"""
Input:
pred, gt: Tensor()
"""
assert pred.shape == gt.shape
self.tp += torch.logical_and(pred == 1, gt == 1).sum().item()
self.fp += torch.logical_and(pred == 1, gt == 0).sum().item()
self.tn += torch.logical_and(pred == 0, gt == 0).sum().item()
self.tn += torch.logical_and(pred == 1, gt == 0).sum().item()
def update_cm(self, tp, fp, tn, fn):
self.tp += tp
self.fp += fp
self.tn += tn
self.tn += fn
10,inverse_sigmoid,用于计算输入张量`x`的逆sigmoid函数。
- - 函数首先将输入张量`x`限制在0到1之间,使用`clamp`方法确保`x`的取值范围在[0, 1]之间。
- - 然后,将`x`分别限制在一个很小的正数`eps`和`1-eps`之间,使用`clamp`方法确保`x1`和`x2`的取值范围不会过小,避免出现除零错误。
- - 最后,函数返回对`x1`和`x2`取对数后的差值,即计算了逆sigmoid函数的值。
def inverse_sigmoid(x, eps=1e-5):
x = x.clamp(min=0, max=1)
x1 = x.clamp(min=eps)
x2 = (1 - x).clamp(min=eps)
return torch.log(x1 / x2)
11,get_raw_dict,用于从输入参数`args`中提取字典数据并返回,将不同类型的参数对象转换为字典形式,方便后续对参数进行序列化或其他操作。。
- - 如果`args`是`argparse.Namespace`类型的对象,则通过`vars(args)`将其转换为字典并返回。
- - 如果`args`是字典类型,则直接返回`args`本身。
- - 如果`args`是`Config`类型的对象,则返回`args`对象的`_cfg_dict`属性,即配置对象的字典表示。
- - 如果`args`不属于上述三种类型,则抛出`NotImplementedError`异常,提示未知类型。
def get_raw_dict(args):
"""
return the dicf contained in args.
e.g:
>>> with open(path, 'w') as f:
json.dump(get_raw_dict(args), f, indent=2)
"""
if isinstance(args, argparse.Namespace):
return vars(args)
elif isinstance(args, dict):
return args
elif isinstance(args, Config):
return args._cfg_dict
else:
raise NotImplementedError("Unknown type {}".format(type(args)))
12,stat_tensors,用于统计输入张量`tensor`的一些统计信息,包括最大值、最小值、均值、方差、标准差和熵。
- - 函数首先通过`assert`语句确保输入张量`tensor`的维度为1,即一维张量。
- - 然后,对输入张量`tensor`进行softmax操作,得到归一化后的张量`tensor_sm`。
- - 接着,计算归一化后张量的熵,即对归一化后的张量乘以对数后求和。
- - 最后,返回一个包含最大值、最小值、均值、方差、标准差和熵的字典。
def stat_tensors(tensor):
assert tensor.dim() == 1
tensor_sm = tensor.softmax(0)
entropy = (tensor_sm * torch.log(tensor_sm + 1e-9)).sum()
return {
'max': tensor.max(),
'min': tensor.min(),
'mean': tensor.mean(),
'var': tensor.var(),
'std': tensor.var() ** 0.5,
'entropy': entropy
}
13,class NiceRepr,用作基类,通过继承这个类并定义`__nice__`方法,可以实现对象的“友好”打印。
- - `NiceRepr`类中定义了`__nice__`方法,用于返回一个描述对象的“友好”摘要字符串。
- - 如果子类定义了`__len__`方法,则`__nice__`方法会返回对象的长度。
- - 如果子类没有定义`__len__`方法,则会抛出`NotImplementedError`异常,提示子类需要定义`__nice__`方法。
- - `__repr__`方法和`__str__`方法分别使用`__nice__`方法返回的摘要字符串来构建对象的字符串表示形式。
- - 如果子类没有定义`__nice__`方法,会发出运行时警告,并返回默认的对象表示形式。
class NiceRepr:
"""Inherit from this class and define ``__nice__`` to "nicely" print your
objects.
Defines ``__str__`` and ``__repr__`` in terms of ``__nice__`` function
Classes that inherit from :class:`NiceRepr` should redefine ``__nice__``.
If the inheriting class has a ``__len__``, method then the default
``__nice__`` method will return its length.
Example:
>>> class Foo(NiceRepr):
... def __nice__(self):
... return 'info'
>>> foo = Foo()
>>> assert str(foo) == '<Foo(info)>'
>>> assert repr(foo).startswith('<Foo(info) at ')
Example:
>>> class Bar(NiceRepr):
... pass
>>> bar = Bar()
>>> import pytest
>>> with pytest.warns(None) as record:
>>> assert 'object at' in str(bar)
>>> assert 'object at' in repr(bar)
Example:
>>> class Baz(NiceRepr):
... def __len__(self):
... return 5
>>> baz = Baz()
>>> assert str(baz) == '<Baz(5)>'
"""
def __nice__(self):
"""str: a "nice" summary string describing this module"""
if hasattr(self, '__len__'):
# It is a common pattern for objects to use __len__ in __nice__
# As a convenience we define a default __nice__ for these objects
return str(len(self))
else:
# In all other cases force the subclass to overload __nice__
raise NotImplementedError(
f'Define the __nice__ method for {self.__class__!r}')
def __repr__(self):
"""str: the string of the module"""
try:
nice = self.__nice__()
classname = self.__class__.__name__
return f'<{classname}({nice}) at {hex(id(self))}>'
except NotImplementedError as ex:
warnings.warn(str(ex), category=RuntimeWarning)
return object.__repr__(self)
def __str__(self):
"""str: the string of the module"""
try:
classname = self.__class__.__name__
nice = self.__nice__()
return f'<{classname}({nice})>'
except NotImplementedError as ex:
warnings.warn(str(ex), category=RuntimeWarning)
return object.__repr__(self)
14,ensure_rng,根据输入的不同情况,函数会返回一个NumPy随机数生成器对象。。
- - 如果输入`rng`为None,则返回全局随机状态。
- - 如果输入`rng`为数值类型,则将其作为种子用于构建一个随机状态。
- - 否则,直接返回输入的`rng`。
def ensure_rng(rng=None):
"""Coerces input into a random number generator.
If the input is None, then a global random state is returned.
If the input is a numeric value, then that is used as a seed to construct a
random state. Otherwise the input is returned as-is.
Adapted from [1]_.
Args:
rng (int | numpy.random.RandomState | None):
if None, then defaults to the global rng. Otherwise this can be an
integer or a RandomState class
Returns:
(numpy.random.RandomState) : rng -
a numpy random number generator
References:
.. [1] https://gitlab.kitware.com/computer-vision/kwarray/blob/master/kwarray/util_random.py#L270 # noqa: E501
"""
if rng is None:
rng = np.random.mtrand._rand
elif isinstance(rng, int):
rng = np.random.RandomState(rng)
else:
rng = rng
return rng
15,random_boxes,作用是生成指定数量的随机边界框,并可以通过缩放比例对边界框进行缩放处理。
-
- 函数接受三个参数:`num`表示要生成的边界框数量,默认为1;`scale`表示边界框的缩放比例,默认为1;`rng`表示随机数生成器,用于生成随机数,默认为None。
-
- 函数首先调用`ensure_rng`函数,将输入的`rng`参数转换为随机数生成器对象。
-
- 然后利用随机数生成器生成一个形状为`(num, 4)`的随机数数组`tlbr`,并将其转换为`np.float32`类型。
-
- 接着根据生成的随机数数组计算边界框的左上角和右下角坐标,并根据缩放比例进行缩放。
-
- 最后将计算得到的边界框数据转换为PyTorch张量(Tensor)并返回。
def random_boxes(num=1, scale=1, rng=None):
"""Simple version of ``kwimage.Boxes.random``
Returns:
Tensor: shape (n, 4) in x1, y1, x2, y2 format.
References:
https://gitlab.kitware.com/computer-vision/kwimage/blob/master/kwimage/structs/boxes.py#L1390
Example:
>>> num = 3
>>> scale = 512
>>> rng = 0
>>> boxes = random_boxes(num, scale, rng)
>>> print(boxes)
tensor([[280.9925, 278.9802, 308.6148, 366.1769],
[216.9113, 330.6978, 224.0446, 456.5878],
[405.3632, 196.3221, 493.3953, 270.7942]])
"""
rng = ensure_rng(rng)
tlbr = rng.rand(num, 4).astype(np.float32)
tl_x = np.minimum(tlbr[:, 0], tlbr[:, 2])
tl_y = np.minimum(tlbr[:, 1], tlbr[:, 3])
br_x = np.maximum(tlbr[:, 0], tlbr[:, 2])
br_y = np.maximum(tlbr[:, 1], tlbr[:, 3])
tlbr[:, 0] = tl_x * scale
tlbr[:, 1] = tl_y * scale
tlbr[:, 2] = br_x * scale
tlbr[:, 3] = br_y * scale
boxes = torch.from_numpy(tlbr)
return boxes
16,class ModelEma,用于实现模型的指数移动平均。
-
- `__init__`方法用于初始化`ModelEma`类,接受三个参数:`model`表示要进行EMA的模型,`decay`表示EMA的衰减系数,默认为0.9997,`device`表示在不同设备上执行EMA,默认为None。
-
- `_update`方法用于更新EMA的权重,其中通过遍历模型和EMA模型的参数字典,根据给定的`update_fn`函数更新EMA的权重。
-
- `set`方法用于将EMA的权重设置为与原模型相同。
class ModelEma(torch.nn.Module):
def __init__(self, model, decay=0.9997, device=None):
super(ModelEma, self).__init__()
# make a copy of the model for accumulating moving average of weights
self.module = deepcopy(model)
self.module.eval()
# import ipdb; ipdb.set_trace()
self.decay = decay
self.device = device # perform ema on different device from model if set
if self.device is not None:
self.module.to(device=device)
def _update(self, model, update_fn):
with torch.no_grad():
for ema_v, model_v in zip(self.module.state_dict().values(), model.state_dict().values()):
if self.device is not None:
model_v = model_v.to(device=self.device)
ema_v.copy_(update_fn(ema_v, model_v))
def update(self, model):
self._update(model, update_fn=lambda e, m: self.decay * e + (1. - self.decay) * m)
def set(self, model):
self._update(model, update_fn=lambda e, m: m)
17,class BestMetricSingle,作用是跟踪单个指标值的最佳值及其对应的轮次,方便在训练过程中实时监控和记录最佳指标值的变化。。
- - `__init__`方法用于初始化`BestMetricSingle`类,接受两个参数:`init_res`表示初始指标值,默认为0.0,`better`表示指标值的比较方式,可选'large'或'small',分别表示指标越大越好或越小越好。在初始化过程中,记录初始指标值、最佳指标值和对应的轮次,并对`better`进行合法性检查。
- - `isbetter`方法用于判断新的指标值是否比旧的指标值更好,根据`better`的取值进行比较。
- - `update`方法用于更新最佳指标值及其对应的轮次,如果新的指标值比最佳指标值更好,则更新最佳指标值和轮次,并返回True;否则返回False。
- - `__str__`和`__repr__`方法用于返回对象的字符串表示,分别用于打印对象和调试时显示对象信息。
- - `summary`方法用于返回包含最佳指标值和对应轮次的字典形式的摘要信息。
class BestMetricSingle():
def __init__(self, init_res=0.0, better='large') -> None:
self.init_res = init_res
self.best_res = init_res
self.best_ep = -1
self.better = better
assert better in ['large', 'small']
def isbetter(self, new_res, old_res):
if self.better == 'large':
return new_res > old_res
if self.better == 'small':
return new_res < old_res
def update(self, new_res, ep):
if self.isbetter(new_res, self.best_res):
self.best_res = new_res
self.best_ep = ep
return True
return False
def __str__(self) -> str:
return "best_res: {}\t best_ep: {}".format(self.best_res, self.best_ep)
def __repr__(self) -> str:
return self.__str__()
def summary(self) -> dict:
return {
'best_res': self.best_res,
'best_ep': self.best_ep,
}
18,class BestMetricHolder,用于管理多个指标值的最佳值及其对应的轮次,支持使用指数移动平均(EMA)。
- - `__init__`方法用于初始化`BestMetricHolder`类,接受三个参数:`init_res`表示初始指标值,默认为0.0,`better`表示指标值的比较方式,可选'large'或'small',分别表示指标越大越好或越小越好,`use_ema`表示是否使用指数移动平均。在初始化过程中,创建一个BestMetricSingle对象`best_all`来管理所有指标值的最佳值,如果`use_ema`为True,则创建两个额外的`BestMetricSingle`对象`best_ema`和`best_regular`分别用于管理EMA和普通指标值的最佳值。
- - `update`方法用于更新指标值的最佳值及其对应的轮次,根据`use_ema`和`is_ema`参数的取值来决定更新哪个最佳值对象,并返回是否更新成功。
- - `summary`方法用于返回包含所有最佳值及其对应轮次的字典形式的摘要信息,如果使用EMA,则同时返回普通指标值和EMA的最佳值信息。
- - `__repr__`和`__str__`方法用于返回对象的字符串表示,分别用于以JSON格式打印对象和调试时显示对象信息。
class BestMetricHolder():
def __init__(self, init_res=0.0, better='large', use_ema=False) -> None:
self.best_all = BestMetricSingle(init_res, better)
self.use_ema = use_ema
if use_ema:
self.best_ema = BestMetricSingle(init_res, better)
self.best_regular = BestMetricSingle(init_res, better)
def update(self, new_res, epoch, is_ema=False):
"""
return if the results is the best.
"""
if not self.use_ema:
return self.best_all.update(new_res, epoch)
else:
if is_ema:
self.best_ema.update(new_res, epoch)
return self.best_all.update(new_res, epoch)
else:
self.best_regular.update(new_res, epoch)
return self.best_all.update(new_res, epoch)
def summary(self):
if not self.use_ema:
return self.best_all.summary()
res = {}
res.update({f'all_{k}': v for k, v in self.best_all.summary().items()})
res.update({f'regular_{k}': v for k, v in self.best_regular.summary().items()})
res.update({f'ema_{k}': v for k, v in self.best_ema.summary().items()})
return res
def __repr__(self) -> str:
return json.dumps(self.summary(), indent=2)
def __str__(self) -> str:
return self.__repr__()
19,merge_configs,用于将两个配置字典合并成一个新的配置字典,如果有重复的键,则使用`cfg2`中的值覆盖`cfg1`中的值,同时忽略值为None的情况。
- - 函数接受两个参数`cfg1`和`cfg2`,分别表示要合并的两个配置字典。
- - 首先对`cfg1`和`cfg2`进行空值检查,如果为None,则将其初始化为空字典。
- - 然后遍历`cfg2`中的每个键值对,如果值不为None,则将其添加到`cfg1`中,如果键已经存在于`cfg1`中,则用`cfg2`中的值覆盖`cfg1`中的值。
- - 最后返回合并后的配置字典`cfg1`。
def merge_configs(cfg1, cfg2):
# Merge cfg2 into cfg1
# Overwrite cfg1 if repeated, ignore if value is None.
cfg1 = {} if cfg1 is None else cfg1.copy()
cfg2 = {} if cfg2 is None else cfg2
for k, v in cfg2.items():
if v:
cfg1[k] = v
return cfg1借鉴链接:https://blog.csdn.net/xian0710830114/article/details/128177705
https://blog.csdn.net/sinat_41942180/article/details/132855765














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









