








🌟 嗨,我是Lethehong!🌟
🌍 立志在坚不欲说,成功在久不在速🌍
🚀 欢迎关注:👍点赞⬆️留言收藏🚀
🍀欢迎使用:小智初学计算机网页IT深度知识智能体
🚀个人博客:Lethehong有一起互链的朋友可以私信我
✅GPT体验码:私信博主~免费领取体验码
欢迎大家加入Lethehong的知识星球里面有全栈资料大全
✅ 高质量内容:相比免费内容,付费社群的干货更多,更新更系统。
✅ 实战导向:提供可运行的代码和策略,而非纯理论。
✅ 行业人脉:可与同行交流,获取内推机会。
✅ 持续更新:长期维护,而非一次性课程。✅GPT体验码:https://gitee.com/lethehong/chatgpt-share
Lethehong诚邀您加入社群,送您海量编程资源,DeepSeek资料包,各种线上线下活动等你来开启,快来占据你得一席之地吧!
【人工智能教程】——人工智能学习者的未来战舰!这个平台用"星际探索"模式重构AI教育:从机器学习基础到多模态大模型实战,每个技术栈都化身可交互的太空舱。上周我在「Transformer空间站」通过修复对话系统的注意力漏洞,竟掌握了BERT的微调精髓!平台三大核心引擎:
- 工业级沙盘:复刻字节跳动推荐算法系统,用真实点击数据训练你的排序模型
- 智能调试舱:代码错误会被三维可视化,梯度消失问题竟用银河系粒子动画演示
- 大厂AI工坊:开放京东智能客服训练框架,零距离接触千万级对话语料库
独创的「元宇宙研习」模式更震撼——戴上VR头盔即刻潜入神经网络内部,亲眼见证卷积核如何捕捉图像特征!新用户注册即送《AIGC实战宝典》+100小时Tesla V100算力卡,隐藏口令【AI_Captain】可解锁谷歌DeepMind课程解密版。点击启航:前言 – 人工智能教程 → 让你的AI能力光年跃迁!
优质专栏:
目录
前言:注册蓝耘智算平台
1. 点击注册链接:蓝耘智算平台
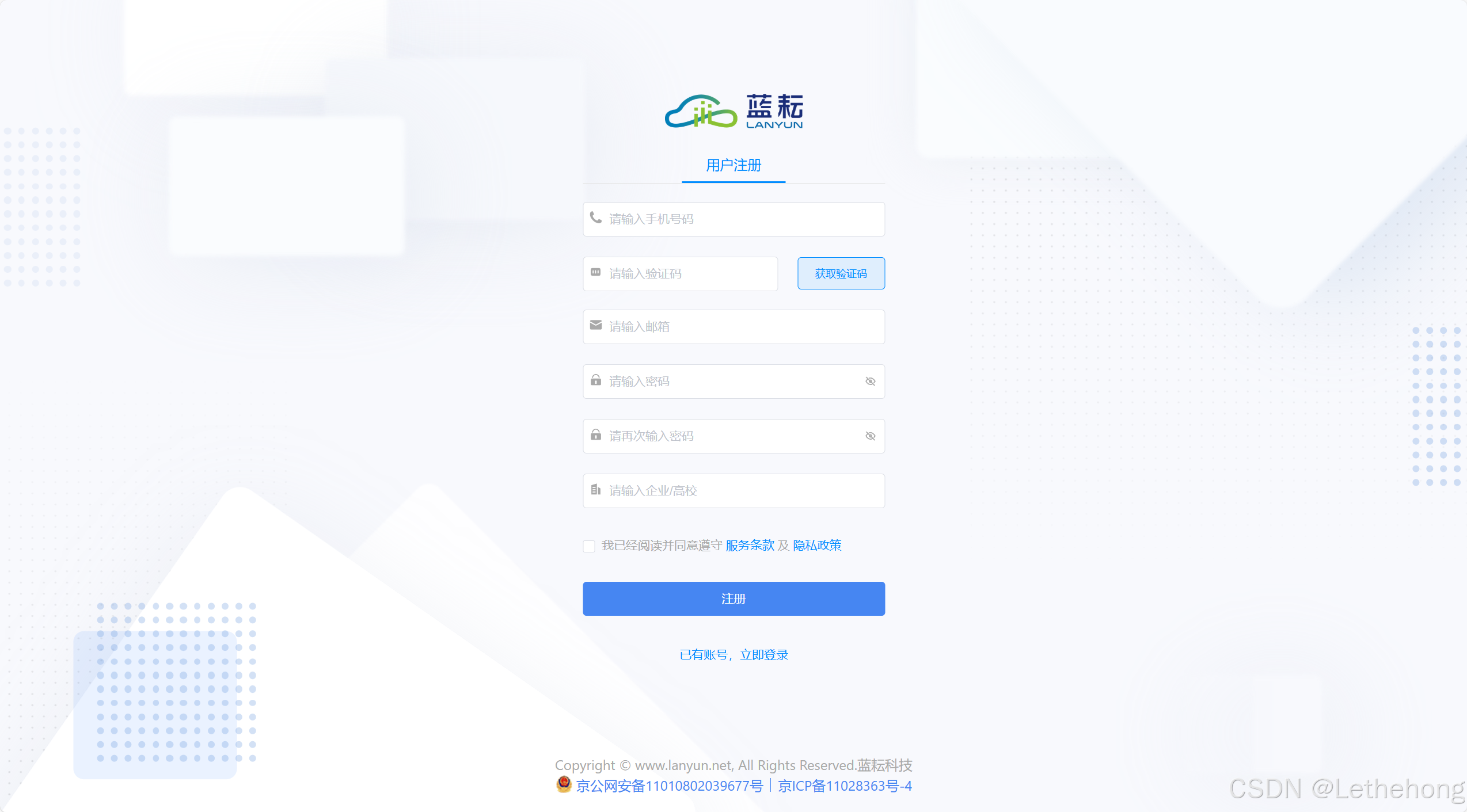
2. 进入下面图片界面,输入手机号并获取验证码,输入邮箱,设置密码,点击注册
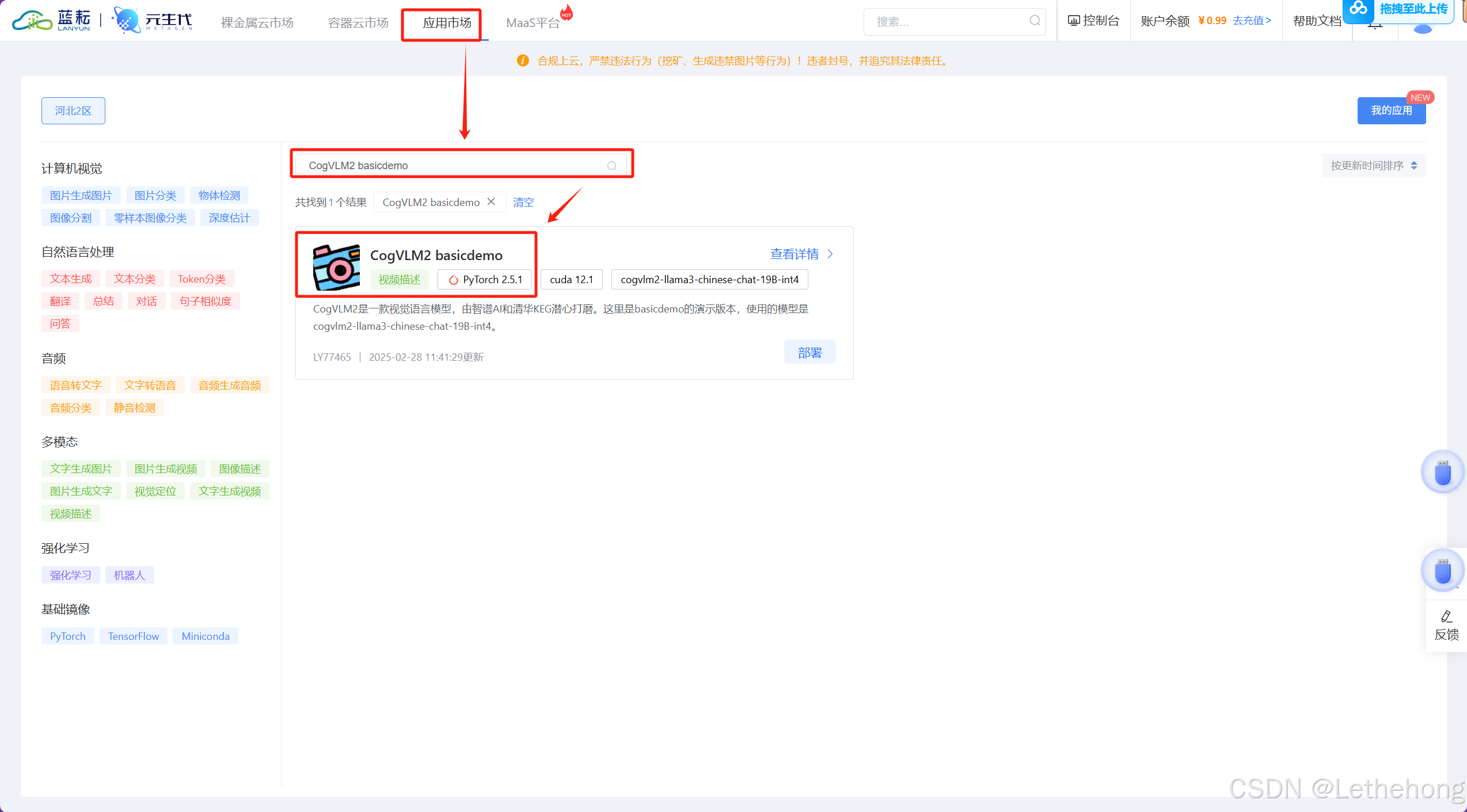
3. 登录之后点击应用市场,搜索CogVLM2 basicdemo之后点击部署
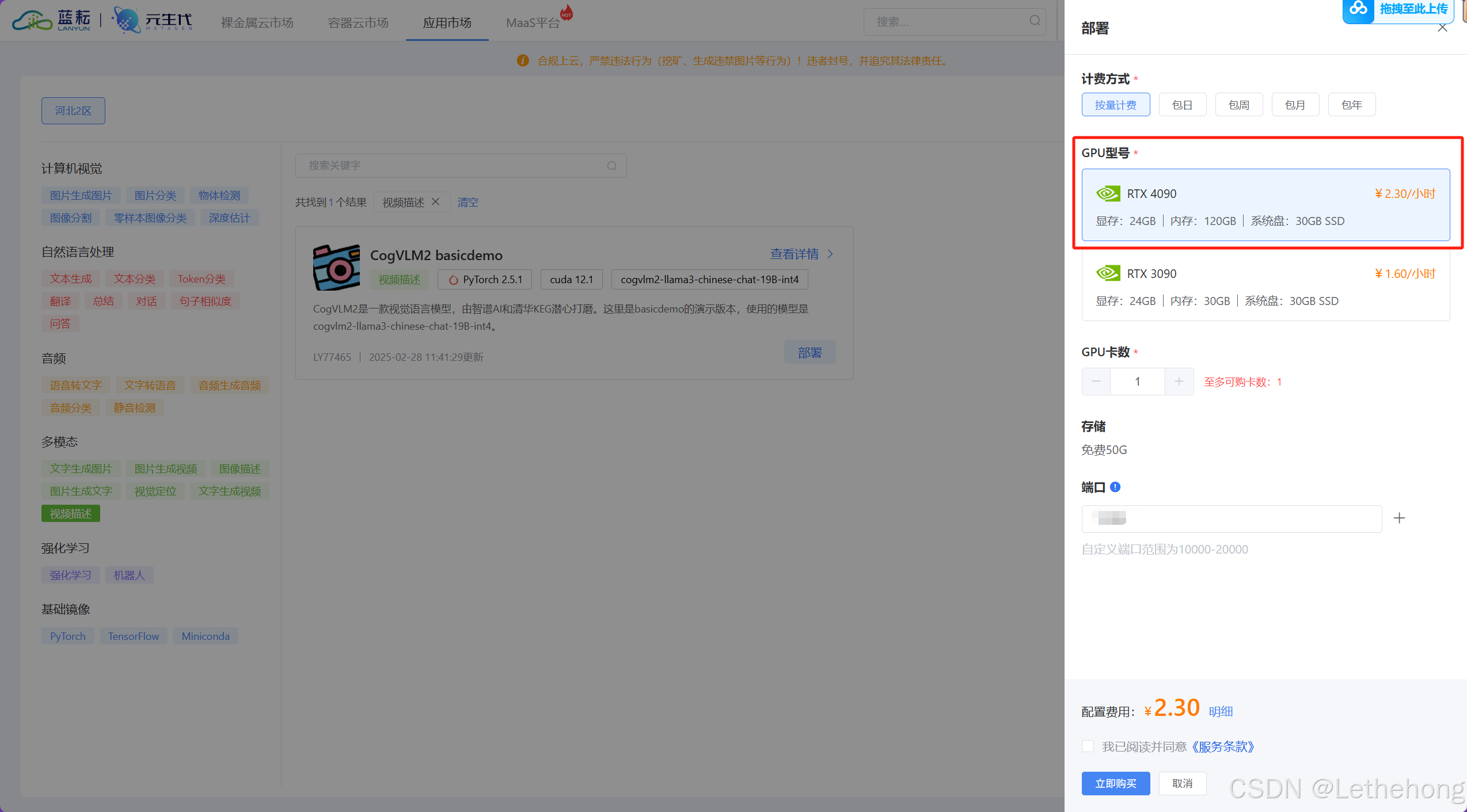
 4. GPU选择4090即可
4. GPU选择4090即可
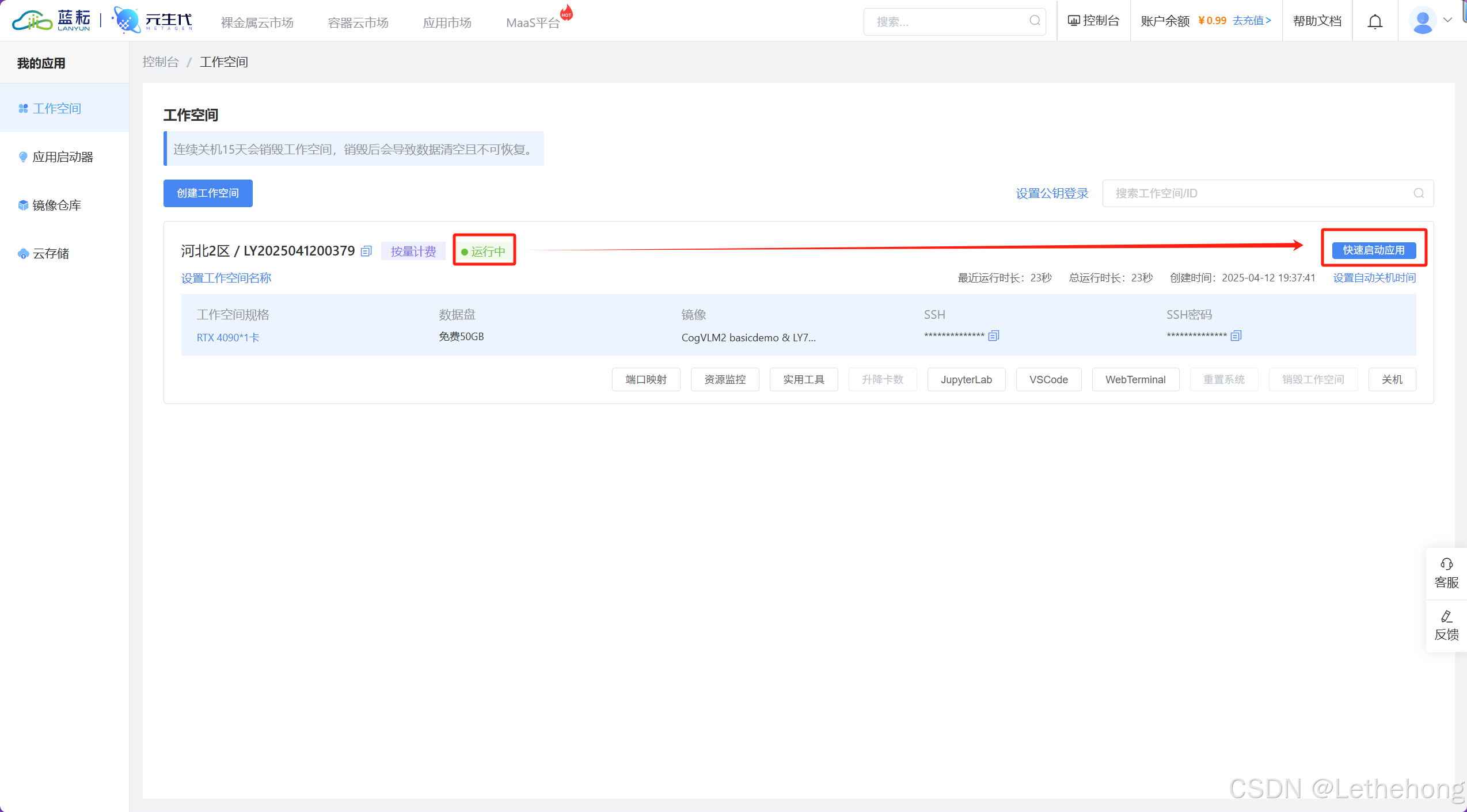
5. 这里已经创建成功(可能需要等待几分钟,大家不放听首歌缓解一下),点击快速启动应用即可(你也可以选择ssh连接去调用模型)
6. 这里跟我ComfyUI一样,点击之后会跳转到专属窗口,现在就可以去创造自己的艺术了
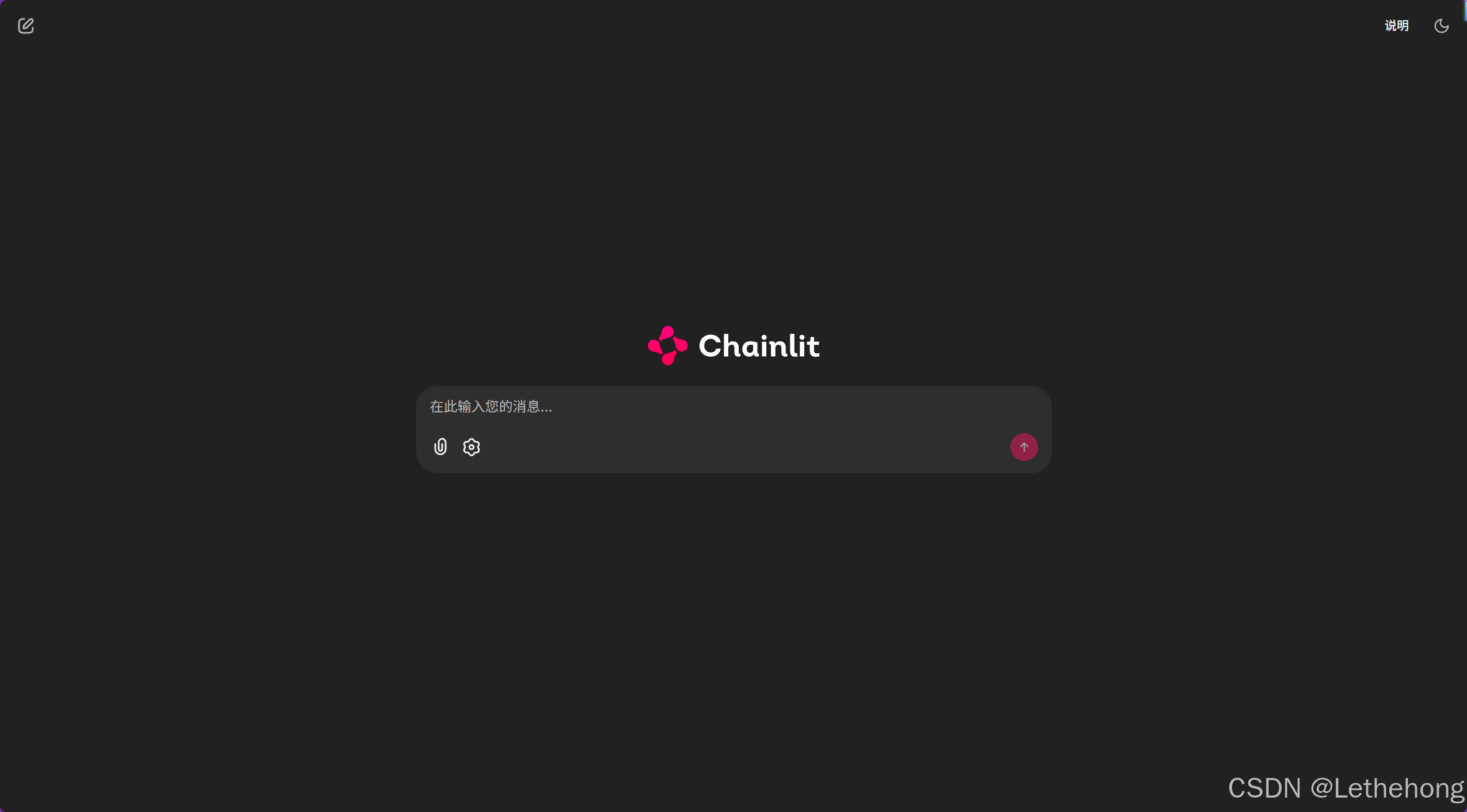
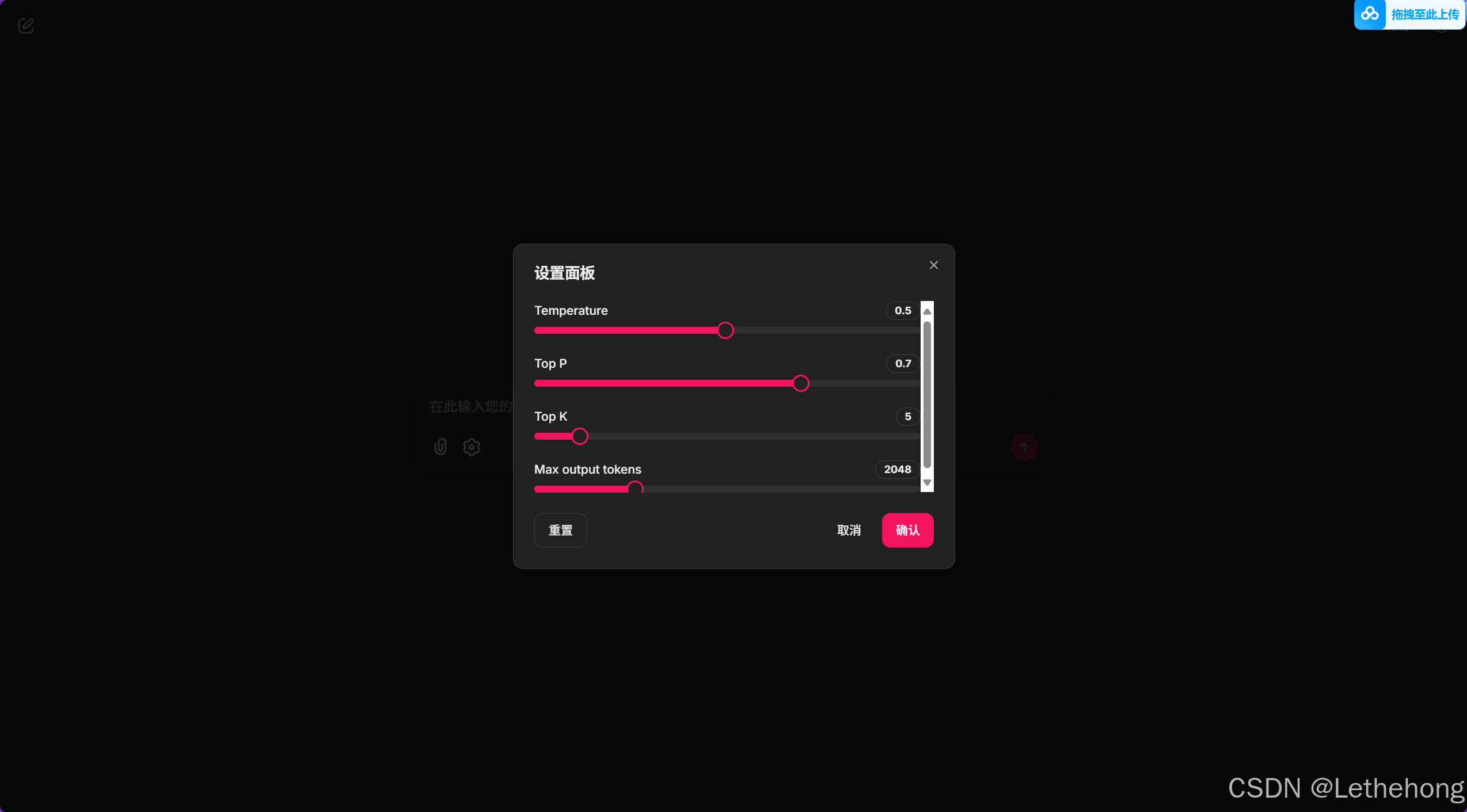
7. 设置面板根据自己的需要去调节,我这里用是默认
8. 怎么说呢,我只能用一个字来形容,那就是“快”,很值得大家去体验一番(图中的内容仅一个热点,请客观看待一切)。

9. 如果大家有兴趣去了解更多关于CogVLM2的情况,可以看末尾的资料文献


元生代品牌的核心价值
蓝耘品牌的核心价值可以归纳为三个关键词:智能化、效率化、创新性。
-
智能化: 蓝耘致力于通过智能平台和自动化工作流系统,帮助企业将传统人工操作转换为智能决策与自动执行。通过使用人工智能算法、机器学习和数据分析,蓝耘能够为企业提供实时的决策支持和优化方案,使得企业能够在瞬息万变的市场中保持竞争力。
-
效率化: 在当前快节奏的商业环境中,时间就是金钱。蓝耘通过精确的工作流管理系统,帮助企业提升工作效率,缩短决策和执行的时间周期。无论是跨部门协作,还是任务调度,蓝耘都能够实现高效的自动化执行,最大限度减少人为失误。
-
创新性: 蓝耘始终走在科技前沿,紧跟最新的技术潮流,并将创新思想融入到平台的开发中。无论是在技术架构、算法设计还是用户体验上,蓝耘都不断推陈出新,确保平台在不断变化的市场需求中始终保持领先地位。
1. 引言
1.1 人工智能与计算机视觉的发展
人工智能(AI)技术近年来取得了飞速发展,特别是在计算机视觉领域。计算机视觉旨在使计算机能够“看”和“理解”图像和视频,这对于自动驾驶、医疗影像分析、安防监控等领域具有重要意义。
1.2 CogVLM2的背景与意义
CogVLM2是蓝耘公司推出的一款视觉-语言模型(VLM)平台,旨在将计算机视觉与自然语言处理相结合,实现图像和文本的深度融合。该平台的推出,为研究人员和开发者提供了一个强大的工具,推动了多模态AI技术的发展。
1.3 文章目的与结构
本文旨在深入探讨CogVLM2平台的技术细节和应用实践,通过详细的代码示例和技术文档说明,帮助读者理解和使用该平台。同时,将与其他平台进行技术对比,突出CogVLM2的优势。
2. CogVLM2平台概述
2.1 平台简介
CogVLM2是基于Transformer架构的视觉-语言模型,能够处理图像和文本数据,实现多种任务,如图像描述生成、视觉问答等。该平台提供了易于使用的接口和丰富的功能,适用于学术研究和工业应用。
2.2 核心功能
-
图像描述生成:根据输入图像生成自然语言描述。
-
视觉问答:针对输入图像,回答相关问题。
-
多模态检索:支持图像和文本的相互检索。
-
模型训练与微调:提供模型训练和微调功能,适应特定任务需求。
2.3 技术架构
CogVLM2采用了Transformer架构,结合了视觉编码器和语言解码器。视觉编码器负责提取图像特征,语言解码器生成文本描述。两者通过注意力机制进行信息交互,实现高效的多模态学习。
3. 环境搭建与配置
3.1 系统要求
-
操作系统:Linux或Windows
-
Python版本:3.7及以上
-
依赖库:PyTorch、Transformers、OpenCV等
3.2 安装步骤
-
克隆代码仓库:
git clone https://github.com/THUDM/CogVLM2 cd CogVLM2 -
创建虚拟环境:
python3 -m venv cogvlm2_env source cogvlm2_env/bin/activate # Linux/Mac cogvlm2_env\Scripts\activate # Windows -
安装依赖:
pip install -r requirements.txt -
下载预训练模型:
python download_model.py
3.3 配置文件详解
平台的配置文件config.yaml包含了模型参数、数据路径等信息。主要字段说明:
-
data_path:数据存放路径 -
batch_size:训练批次大小 -
learning_rate:学习率 -
epochs:训练轮数 -
image_size:输入图像尺寸
4. 功能模块详解
4.1 数据预处理
数据预处理是模型训练的关键步骤,包括图像缩放、裁剪、归一化,以及文本标注的处理。CogVLM2提供了data_preprocess.py脚本,用户可以根据需求进行数据处理。
4.2 模型训练
模型训练模块负责加载数据、构建模型、设置优化器,并进行训练。主要步骤包括:
-
数据加载:使用
DataLoader加载训练和验证数据。 -
模型构建:加载预训练模型,并根据任务需求进行修改。
-
训练循环:迭代训练数据,计算损失,更新模型参数。
4.3 图像生成
图像生成模块利用训练好的模型,根据输入文本生成图像描述。用户可以使用generate.py脚本,输入文本,获取生成的图像描述。
4.4 结果评估
评估模块计算模型在验证集上的性能指标,如BLEU、CIDEr等。使用evaluate.py脚本,输入模型输出和参考答案,计算评估指标。
5. 功能模块详解
5.1 数据预处理
数据预处理是模型训练和推理的基础,直接影响模型的性能和效果。CogVLM2提供了灵活的数据预处理功能,包括:
-
图像处理:支持对图像进行裁剪、缩放、归一化等操作,确保输入数据的质量和一致性。
-
文本处理:对文本进行分词、去除停用词、词向量化等处理,使其适应模型的输入要求。
以下是一个数据预处理的示例代码:
from cogvlm2 import preprocess
# 图像预处理
image_path = 'path/to/image.jpg'
processed_image = preprocess.image(image_path, target_size=(224, 224))
# 文本预处理
text = '示例文本'
processed_text = preprocess.text(text)
5.2 模型训练
CogVLM2支持模型的训练和微调,用户可以根据自己的数据和任务需求,对模型进行定制化训练。主要步骤包括:
-
数据加载:使用
DataLoader加载训练和验证数据集。 -
模型构建:加载预训练模型,并根据任务需求进行修改。
-
训练过程:定义损失函数和优化器,进行模型训练。
以下是模型训练的示例代码:
from cogvlm2 import CogVLM2, DataLoader, Trainer
# 加载数据
train_loader = DataLoader('path/to/train_data')
val_loader = DataLoader('path/to/val_data')
# 初始化模型
model = CogVLM2(pretrained=True)
model.modify_for_task('image_captioning')
# 定义训练参数
trainer = Trainer(model=model, train_loader=train_loader, val_loader=val_loader, epochs=10, lr=1e-5)
# 开始训练
trainer.train()
5.3 图像生成
在模型训练完成后,可以使用模型进行图像生成任务,例如根据文本生成图像描述。以下是图像生成的示例代码:
from cogvlm2 import CogVLM2
# 加载训练好的模型
model = CogVLM2.load('path/to/trained_model')
# 输入文本
text_input = '一只可爱的猫咪在花园里玩耍'
# 生成图像描述
image_description = model.generate_image_description(text_input)
print(image_description)
5.4 结果评估
评估模型的性能是确保其有效性的关键步骤。CogVLM2提供了多种评估指标,如BLEU、CIDEr等,帮助用户量化模型的表现。以下是结果评估的示例代码:
from cogvlm2 import evaluator
# 加载模型输出和参考答案
model_output = ['生成的图像描述']
reference = [['参考的图像描述1', '参考的图像描述2']]
# 计算BLEU分数
bleu_score = evaluator.bleu(model_output, reference)
print(f'BLEU Score: {bleu_score}')
6. 技术文档说明
6.1 API接口说明
CogVLM2提供了丰富的API接口,方便用户进行模型调用和集成。主要API包括:
-
模型加载:加载预训练模型或自定义训练的模型。
-
数据处理:对图像和文本数据进行预处理和后处理。
-
训练与推理:提供训练和推理的接口,支持批量处理和实时处理。
详细的API文档可参考官方文档。
6.2 配置参数详解
在使用CogVLM2时,用户需要配置一些参数,如学习率、批次大小等。以下是主要配置参数的说明:
-
learning_rate:学习率,控制模型参数更新的步长。 -
batch_size:批次大小,决定每次训练使用的数据量。 -
epochs:训练轮数,模型将遍历整个训练数据集的次数。 -
image_size:输入图像的尺寸,影响模型的输入和计算量。
6.3 错误处理与调试
在使用过程中,可能会遇到各种错误和问题。CogVLM2提供了详细的错误提示和日志记录,帮助用户定位和解决问题。建议用户在调试时:
-
查看日志:检查日志文件,获取错误信息。
-
检查数据:确保输入的数据格式和内容正确。
-
调试模式:启用调试模式,获取更详细的运行信息。
7. 与其他平台的技术优势对比
在多模态AI领域,存在多种视觉语言模型平台。CogVLM2相对于其他平台,具有以下技术优势:
7.1 模型架构优势
CogVLM2采用了先进的模型架构,将视觉编码器和语言模型深度融合,充分利用了视觉和语言信息的互补性。这种设计使得模型在处理复杂的视觉语言任务时,表现出色。
7.2 性能优势
在多个标准数据集和基准测试中,CogVLM2取得了领先的性能。例如,在图像描述生成和视觉问答任务中,模型表现优异,证明了其强大的能力。
7.3 应用场景优势
CogVLM2支持多种应用场景,包括图像描述生成、视觉问答、多模态检索等,满足了不同领域的需求。其灵活性和可扩展性,使其适用于各种实际应用。
8. 案例研究
8.1 案例背景
某电商平台希望利用CogVLM2模型,对商品图片进行自动描述生成,以提升用户体验和搜索效率。
8.2 实施过程
-
数据收集:收集大量商品图片及其对应的文本描述。
-
模型训练:使用收集的数据,对CogVLM2模型进行微调,适应电商领域的特定需求。
-
系统部署:将训练好的模型部署到生产环境,提供实时的图像描述生成服务。
8.3 成果分析
通过实施,平台实现了对商品图片的自动描述生成,提升了搜索准确性和用户满意度。模型在实际应用中表现稳定,满足了业务需求。
9. 总结与展望
9.1 主要收获
通过对CogVLM2平台的深入研究和实践,获得以下主要收获:
-
技术理解:深入理解了视觉语言模型的原理和应用。
-
实践经验:掌握了使用CogVLM2进行模型训练和应用的技能。
-
性能评估:通过实际测试,验证了模型的性能和效果。
9.2 存在的挑战
尽管CogVLM2在多个领域取得了显著的成绩,但在实际应用中仍面临一些挑战和改进空间:
-
计算资源消耗:高性能模型通常需要大量的计算资源,尤其是在训练阶段。尽管CogVLM2在推理时通过量化技术降低了显存需求,但在训练和大规模推理时,仍需要高性能的硬件支持。
-
模型泛化能力:虽然CogVLM2在多个基准测试中表现出色,但在处理未见过的数据或复杂场景时,模型的泛化能力仍需进一步验证和提升。
-
多模态协同:在实际应用中,如何有效地融合视觉和语言信息,处理复杂的多模态输入,是一个持续研究的课题。
9.3 未来发展方向
展望未来,CogVLM2及其后续版本有以下发展方向:
-
模型轻量化:通过模型剪枝、量化等技术,减少模型的参数量和计算量,使其适用于资源受限的设备,如移动端和边缘计算设备。
-
跨模态学习:加强模型在不同模态之间的协同学习能力,提升其在复杂场景下的表现。例如,将视觉、语言和声音等多模态信息进行融合,处理更复杂的任务。
-
自监督学习:探索自监督学习方法,使模型能够从大量未标注的数据中学习,降低对人工标注数据的依赖,提升模型的泛化能力和鲁棒性。
-
应用拓展:将CogVLM2应用于更多实际场景,如智能医疗、自动驾驶、虚拟现实等,验证其在不同领域的适用性和效果。
10. 参考资料
- CogVLM2: 第二代视觉大模型,19B 即可比肩GPT-4V. 知乎专栏.
- CogVLM2:第二代视觉大模型,19B 即可比肩 GPT-4V. CSDN博客.
- CogVLM2多模态开源大模型:部署与实战指南. 百度智能云.
- CogVLM2最佳实践. GitHub.
- CogVLM2首页、文档和下载- 开源视觉语言模型. 开源中国.
- (赠书)国产开源视觉语言模型CogVLM2在线体验:竟能识别黑悟空. 博客园.
- 机械臂+大模型+多模态=人机协作具身智能体. 鲸智.
- CogVLM2: 智谱开源新一代多模态大模型
- CogVLM2 - 智谱AI推出的新一代多模态大模型
- CogVLM:智谱AI 新一代多模态大模型 [2023-10-12]
- 颜水成挂帅,奠定「通用视觉多模态大模型」终极形态!一统理解/生成/分割/编辑 - 知乎
- GitHub - LazyChads/cogvlm2
- CogVLM大模推理代码详细解读-CSDN博客
- 一文深度解读多模态大模型视频检索技术的实现与使用 [2024-01-25]
- CogVLM:智谱AI 新一代多模态大模型-CSDN博客 [2023-10-11]
- 2024年,目前的开源视觉大模型有哪些? - 知乎
- CogVLM多模态大模型训练代码详细教程(基于vscode调试与训练)_cogvlm模型微调
- CogVLM:智谱AI 新一代多模态大模型 - 知乎 - 知乎专栏 [2023-10-11]
- GPT-4o多模态能力再提升多家上市公司加速推进AI应用落地 [5 天前]
- 上海AI实验室发布新一代书生·视觉大模型,视觉核心任务开源领先
- CogAgent:带Agent 能力的视觉模型来了原创 [2023-12-24]
- CogAgent:基于多模态大模型的GUI Agent - DevPress [2023-12-26]
- 支持1120分辨率图像多轮对话具备GUI Agent能力 [2023-12-26]
- 万字长文带你全面解读视觉大模型 [2023-10-12]
- 颜水成挂帅,奠定「通用视觉多模态大模型」终极形态,一统理解/生成/分割/编辑-36氪
- GitHub - THUDM/CogVLM2: 第二代 CogVLM多模态预训练对话模型
- CogVLM Visual Expert for Pretrained Language Models [2023-11-10]
- CogAgent:带 Agent 能力的视觉模型,免费商用 - 文章 - 开发者社区 - 火山引擎
- LLM大语言模型和检索增强生成 [2023-12-06]
- LLM-TAP.pdf [2023-07-31]
- CogVLM与CogAgent:开源视觉语言模型的新里程碑-CSDN博客 [2023-12-19]
- 结合符号性记忆,清华等提出ChatDB,提升大模型的复杂 ... [2023-06-20]
- 知识图谱和大语言模型的共存之道 [2023-09-21]
- CogAgent-可免费商用的带 Agent 能力的视觉模型 - AIHub | AI导航 [2024-01-15]
- CogVLM:深度融合引领视觉语言模型革新,多领域性能创新高 - 知乎
- 文本生成图像工作简述1--概念介绍和技术梳理原创 [2022-10-14]
- 文本生成图像技术:概念、应用与实践 [2024-02-22]
- CogVLM2/README_zh.md at main · THUDM/CogVLM2 · GitHub
- 支持1120分辨率图像多轮对话具备GUI Agent能力- 智友网络 [2023-12-26]
- 统一图像和文字生成的MiniGPT-5来了:Token变Voken - 36氪 [2023-10-09]
- 多模态LLM论文分享(二): 智谱开源CogVLM - 知乎
- CogVLM:智谱AI 新一代多模态大模型-CSDN博客
- 多模态-CogVLM - 星辰大海,绿色星球 [2023-11-05]
- CogVLM:智谱AI 新一代多模态大模型 [2023-10-13]
- CogVLM:智谱AI 新一代多模态大模型 [2023-10-12]
- 多模态大模型-CogVLm 论文阅读笔记 [2023-12-28]
- 清华&智谱AI推出CogAgent:支持1120分辨率图像多轮对话,具备GUI Agent能力
- 【LLM多模态】CogVLM图生文模型结构和训练流程原创 [2024-03-24]
- CogAgent:带Agent 能力的视觉模型,免费商用原创 [2023-12-26]
- CogAgent:带Agent 能力的视觉模型,免费商用 [2023-12-25]
- 今天来聊一聊视觉大模型原创 [2023-07-19]
- CogAgent:带Agent 能力的视觉模型,免费商用 [2023-12-22]
- Github揽获3k+星!清华开源CogAgent:基于多模态大模型的 ... [2024-01-04]




















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











