







目录
2、K-折交叉验证(KFold, cross_val_score)
KNN(K-Nearest Neighbors,K近邻)算法是一种基本的分类方法(也可用于回归),它根据K个邻居样本的类别来判断当前样本的类别,核心原理是一个样本的类别可以由其"最近的"K个邻居的大多数类别来决定。例如: 有10000个样本,选出离样本A最近的7个“邻居”,然后在这7个样本中假设:类别1有2个,类别2有3个,类别3有2个,那么就可以认为A样本属于类别2,因为在它的7个“邻居”中 类别2最多,用一句古话解释就是:近朱者赤近墨者黑。
下面就来详细介绍:
一、样本距离判断
在上述举例的时候说要选出离样本A最近的7样本,而样本之间的距离怎么用远近描述呢?这里的距离实际上描述的是样本之间的差异,数值越小说明越相近。常见的距离算法有:
1、欧式距离
欧式距离是两点之间的直线距离,源于欧几里得几何中的最短路径,也是KNN算法默认的距离算法,计算公式如下:
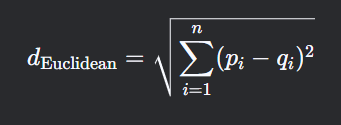
举个例子,点A(1,3)和点B(4,7)之间的欧式距离为:

2、曼哈顿距离
曼哈顿距离是两点在坐标轴上的绝对差之和,因类似曼哈顿街区的行走路径而得名(只能沿垂直方向移动),公式为:
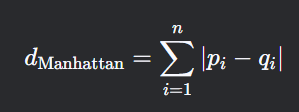
举个例子,点A(1,3)和点B(4,7)之间的欧式距离为:
还有其他距离算法如闵可夫斯基距离、余弦相似度等这里不过多介绍
二、KNN算法
原理开头已经讲过,下面用一个实际的例子来解释:
这里有一些电影的数据以及类型,请用KNN算法预测《唐人街探案》电影属于哪种类型?
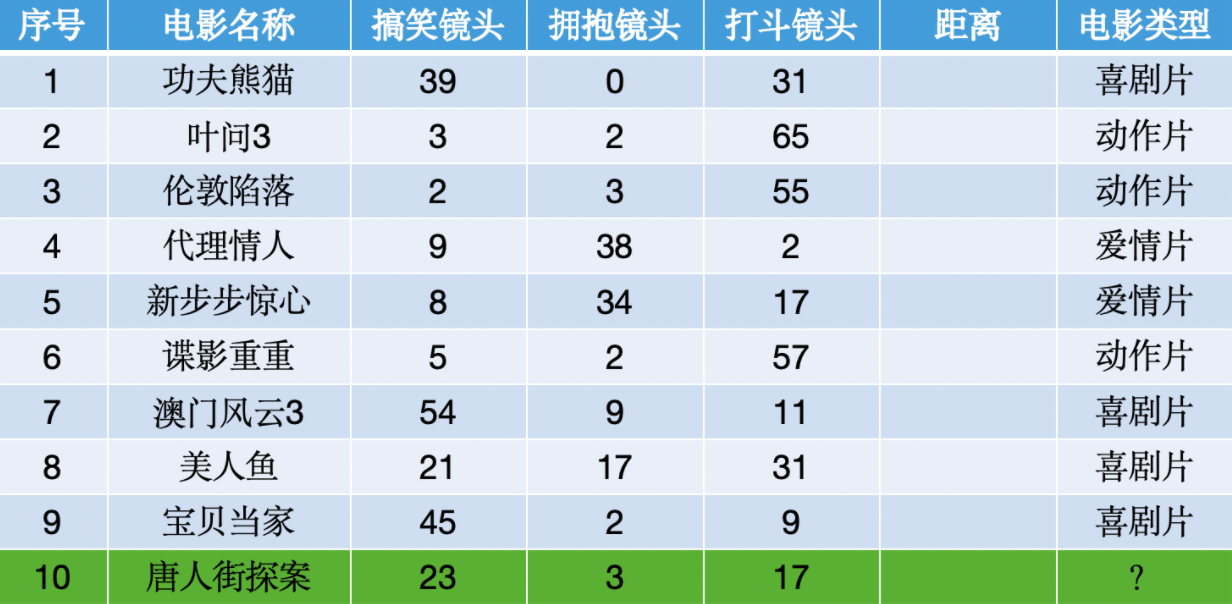
解决方法就是计算《唐人街探案》与每个电影之间的距离然后选取最近的5个或者7个电影,看大多数类别。这里的距离就用不同的镜头数计算即可,比如计算与《伦敦陷落》的距离:

所以将每个电影与唐探计算距离后得到:
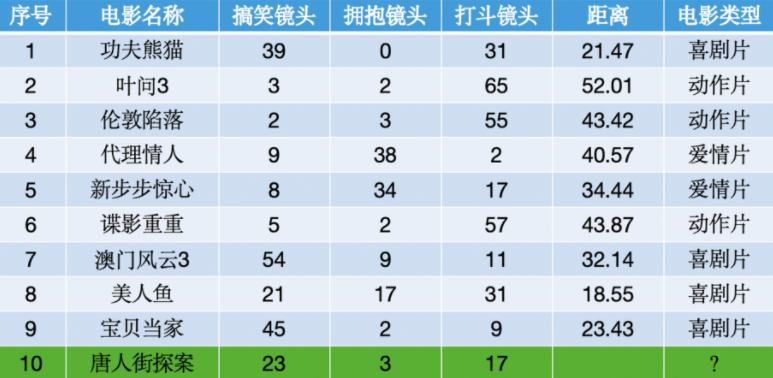
可以看到,不管是取最近的5个或者7个样本,类型最多的都是喜剧片,所以可以判断《唐人街探案》是喜剧片。
写代码的步骤就是:加载数据集-数据集划分-标准化数据-模型训练-测试集预测-模型评估
一句话解释:通过标准化后的 x_train ,和无需标准化的 y_train 来训练模型,然后根据转换后的 x_test 来预测 y_pred,并与真实的 y_test 进行比较,判断模型准确率。
代码示例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
iris=load_iris(return_X_y=False) #加载鸢尾花数据集 返回一个 Bunch 对象(类似字典),包含完整的数据集信息
x = iris.data
y = iris.target
#划分数据集 x_train训练特征,y_train训练目标, x_test测试特征,y_test测试目标
#注意返回值顺序
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.3,random_state=22, shuffle=True)
#标准化训练数据集(特征数据集,不是标签数据集)
standas = StandardScaler()
x_train = standas.fit_transform(x_train)
#生成KNN算法模型,选取参数为7,algorithm="auto"表示默认选择计算距离的最优算法
model = KNeighborsClassifier(n_neighbors=7, algorithm="auto")
#用测试集的特征数据和标签数据训练模型
model.fit(x_train, y_train)
#标准化测试数据集(同样是特征数据集)
x_test = standas.transform(x_test) #测试集只能用 transform()
#开始预测,把测试集的特征数据传入模型进行预测
y_pred = model.predict(x_test)
#模型评估
#方法一:直接打印比较
print(y_pred)
print(y_test)
#方法二:计算准确率
score = model.score(x_test, y_test) #底层逻辑就是先计算出y_pred再与y_test计算准确率,相当于一步完成了预测和评估,不需要显式生成 y_pred再计算
print(score)
运行结果:

可以看到,准确率还是很高的,所以此时就可以用这个模型去预测新的数据了,例如:
#预测新的数据
x_test_new=[[5.75,2.3,1.1,2.3],
[3.75,5.2,4.2,2.6],
[2.75,2.3,1.2,4.5],
[2.75,2.3,1.2,4.5]]
x_test_new = standas.transform(x_test_new) #测试集只能转换不能 fit()
y_pred_new = model.predict(x_test_new)
print(y_pred_new) # [1 0 2 2]模型保存与加载
模型构建完成后我们可以保存起来,以后可以直接使用,首先要新建一个pkl文件用于保存:
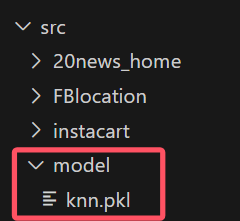
然后代码如下:
'''模型保存与加载'''
# 保存模型 :joblib.dump(estimator, "my_ridge.pkl")
# estimator为生成的模型名,路径就是保存的 pkl文件路径
joblib.dump(model, './src/model/knn.pkl')
# 加载模型:estimator = joblib.load("my_ridge.pkl")
model = joblib.load('./src/model/knn.pkl')
#使用模型预测
y1=model.predict([[0.4,0.2,0.4,0.7]])
print(y1) # [1]缺点
对于大规模数据集,计算量大,因为需要计算测试样本与所有训练样本的距离。对于高维数据,距离度量可能变得不那么有意义,这就是所谓的“维度灾难”,需要选择合适的k值和距离度量,这可能需要一些实验和调整,且计算复杂度高,需要存储所有训练数据。
三、模型选择与调优
模型选择是指在多个候选模型中选择最适合当前问题的模型,考虑因素包括问题类型分类、回归、聚类等)、数据特征(大小、维度、稀疏性等)、模型假设与数据特性的匹配度等;调优就是在选择模型后不断对模型进行优化。下面介绍两个不同侧重点的方法:
交叉验证(模型选择)
交叉验证的主要作用是模型评估,是模型选择的核心环节,它的核心目标是评估并对比模型的泛化性能,主要方法有以下几种,顺便说一下,由于这几个方法的 API用法都差不多,所以我用分层 K-折交叉验证方法写完整案例:
1、保留交叉验证(train_test_split)
最简单的交叉验证形式,它是将数据集随机划分为训练集和测试集,典型划分比例是整个数据集的近70%被用作训练集,其余30%被用作测试集。优点是计算成本低,实现简单,适用于大数据集,缺点是评估结果对数据分割方式敏感,可能浪费数据,不适合小数据集
代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
x,y=load_iris(return_X_y=True) #加载数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)2、K-折交叉验证(KFold, cross_val_score)
基本概念是将数据集随机划分为 K个大小相同的部分 (K通常取5或10),每个部分被称为一个 Fold,每次使用 K-1个部分作为训练集,剩下的1个作为测试集,这样重复 K次,直到每个Fold都被用作过测试集,最终取K次评估的平均准确率。优点是充分利用了数据,评估结果更稳定,适合中小规模数据集,缺点是计算成本是保留法的K倍,且对不平衡数据可能产生偏差
代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
x,y=load_iris(return_X_y=True)
kf=KFold(n_splits=5,shuffle=True,random_state=22) #分成5个部分,shuffle表示分之前是否洗牌3、分层K-折交叉验证(StratifiedKFold)
是 K-折交叉验证的改进版本,分层的意思是在每一个 Fold 中都保持着原始数据中各个类别的比例关系,比如说:原始数据有3类,比例为1:2:1,若采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别同样保持着1:2:1的比例,这样会使验证结果更加可信。优点是保持了数据分布的一致性,对不平衡数据的评估更可靠,缺点是仅适用于分类问题,且计算复杂度与K-折相同
代码如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold
x,y=load_iris(return_X_y=True)
skf=StratifiedKFold(n_splits=5,shuffle=True,random_state=22) #分成5个部分完整案例:
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import StratifiedKFold
import joblib
x,y=load_iris(return_X_y=True) #加载数据集
skf=StratifiedKFold(n_splits=5,shuffle=True,random_state=22) #将整个数据集分成5个部分
indexs=skf.split(x,y) #返回一个可迭代对象,一共有5个部分,每个部分对应的是训练集和测试集的下标
#用循环取出每一个部分对应的X和y下标,来访问到对应的训练集的特征数据和测试集的特征数据,以及训练集的目标和测试集的目标
for train_index,test_index in indexs:
x_train,x_test,y_train,y_test=x[train_index],
x[test_index],y[train_index],y[test_index]
stands = StandardScaler()
x_train = stands.fit_transform(x_train) #标准化训练集的特征数据
x_test = stands.transform(x_test) #标准化测试集的特征数据
model = joblib.load('./src/model/knn.pkl') #加载模型,这里用之前保存的KNN模型
model.fit(x_train, y_train) #每次预测完一个折叠后要重新训练模型
y_pred = model.predict(x_test) #预测5个部分
print(y_pred)
score = model.score(x_test, y_test) #计算5个部分的准确率
print("准确率为:", score)注意,为什么要将标准化 x_train 和 x_test 以及 model.fit() 放在循环里面是因为每次预测完一个折叠后需要重新训练模型,我们的目的是用交叉验证方法来评估模型而非单纯的预测,所以运行结果为:
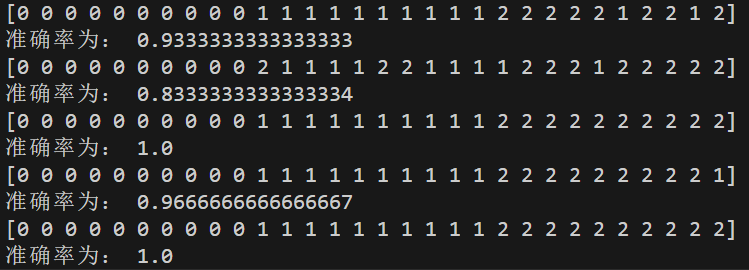
如果想要计算平均准确率,可以在循环开始之前创建一个空列表,然后将每个折叠的准确率追加到这个空列表中,用mean()方法计算即可
4、其他验证方法
还有留一法交叉验证(LeaveOneOut)、留P法交叉验证(LeavePOut)、时间序列交叉验证(TimeSeriesSplit)等方法,这里就不一一介绍了。
超参数搜索(模型调优)
也叫网格搜索(Grid Search ),主要作用是模型调优,超参数就是需要人为控制且会产生不同结果的参数,比如KNN算法里的参数K,网格搜索就能自动地帮助我们找到最好的超参数值。
API 为 GridSearchCV(estimator, param_grid= , cv= ),estimator是待调优的模型对象,param_grid是参数网格,是以参数名称作为键,将参数设置成列表作为值的字典(注意字典的键名由传入的模型的超参数名决定,比如现在传入KNN模型,则键就是下面的 n_neighbors,且键可以不止一个),cv是交叉验证策略,传入整数表示K折。其中,estimator有几个重要的属性:best_params_ (最佳参数),best_score_ (在训练集中的准确率),best_estimator_ (最佳估计器),cv_results_ (交叉验证过程描述),best_index_ (最佳k在列表中的下标)
代码示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
x,y=load_iris(return_X_y=True) #加载数据集
knn = KNeighborsClassifier(n_neighbors=5) #创建模型
params = [5,7,9,11]
param_grid = {"n_neighbors": params} #字典形式的网格参数
gs = GridSearchCV(knn, param_grid=param_grid, cv=5) #创建超参数搜索工具,cv=5表示进行5次交叉验证
gs.fit(x, y) #进行训练
#查看训练结果
print("最佳参数:", gs.best_params_)
print("最佳参数下标", gs.best_index_)
print("最佳结果:", gs.best_score_)
print("最佳模型:", gs.best_estimator_)
#此时如果要进行结果预测的话就可以用最佳模型进行预测
x_data = [1.2,3.4,5.6,7.8]
y_pred = gs.best_estimator_.predict([x_data]) #传入的必须是二维数组
print("预测值为:", y_pred)运行结果:

这样我们就将最佳参数性能可视化了。
KNN算法和超参数搜索就到这里,机器学习下一篇是朴素贝叶斯分类、决策树分类、集成学习之随机森林。以上有问题可以指出。

















 1524
1524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









