







目录
1. 辛普森悖论简介
定义:
辛普森悖论(Simpson’s Paradox)指的是在分组数据中,各组内呈现某一趋势或结论,但当将所有组的数据合并后,整体数据却呈现相反趋势的现象。这种现象通常说明在数据聚合过程中,存在混杂或隐含的影响因素,使得分组内的真实关系被整体数据的权重分布所扭曲。
简单示例:
假设在两组人群中比较两种治疗方法 A 和 B,分组统计显示在每个子组中治疗 A 的成功率均高于治疗 B;但将两个子组数据合并后,治疗 B 的总体成功率反而高于 A。这就构成了辛普森悖论。
2. 成因解析
2.1 混杂变量和权重分布问题
1. 混杂变量
-
基本定义
在一个实验或观察性研究中,我们通常探讨自变量对因变量的影响。但是,有时存在某个或某些额外的变量,这些变量既与自变量有关,也与因变量有关。如果这些额外变量未被识别或控制,它们会使得自变量与因变量之间的关系看起来比实际情况更强、减弱或甚至方向发生反转。这种额外影响就称为混淆变量。
-
混淆变量如何产生误解
如果混淆变量没有被控制,就可能产生两种情况:
-
虚假的关联: 研究者可能会错误地认为自变量和因变量之间存在直接的因果关系,但实际上这种关系是混淆变量的结果。
-
隐藏的真正关系: 如果混淆变量的作用非常大,可能掩盖掉自变量对因变量实际存在的影响,使得研究者低估或误判两者之间的关系。
-
-
举例说明
例如,在研究“锻炼对健康状况的影响”的研究中,可能发现有锻炼的人群健康状况较好。看似说明锻炼有助于健康,但如果没有控制“饮食习惯”这一混淆变量,而健康饮食也能显著改善健康,那么良好的健康状况可能不仅仅归因于锻炼,而是锻炼的人通常也更注重饮食健康。这时,“饮食习惯”就是一个混淆变量,它同时与锻炼(自变量)和健康状况(因变量)相关联。
-
如何控制混淆变量
-
分层分析: 将样本按照混淆变量的水平进行分组,再分别分析自变量与因变量之间的关系。
-
多变量回归: 将混淆变量纳入回归模型,通过统计方法控制其影响,从而更准确地评估自变量对因变量的影响。
-
随机分配: 在实验设计中,采用随机分配的方法可以使混淆变量在各个处理组中大致均衡,从而减少其干扰。
-
2. 权重分布的影响:
各子组样本量的差异会导致加权平均出现严重偏移。即使在每个子组内比较时,某个策略更优,但如果较大权重的组倾向于另一策略,则整体上可能出现反转。
-
示例说明
在大学录取中,经常会发现整体数据显示女申请者的录取率低于男申请者,但当我们把数据分到各个院系后,可能发现在每个院系里女申请者的录取率并不低,甚至高于男申请者。为何会出现这种情况?关键就在于各院系的权重分布不同:各院系申请人数(或说“权重”)差异较大,而各院系的录取难易程度也不同。整体数据的加权平均结果便可能与各院系的局部趋势不一致,从而产生辛普森悖论。
假设某大学有两个院系 A 和 B,其录取数据如下:
- 院系数据
院系 性别 申请人数 录取人数 录取率 院系 A 男生 100 60 60% 女生 20 15 75% 院系 B 男生 100 80 80% 女生 200 120 60% -
局部分析:
-
在院系 A中:
女生录取率 = 15 / 20 = 75 % 女生录取率 =15/20=75\% 女生录取率=15/20=75% 高于男生的 60%。 -
在院系 B中:
男生录取率 = 80 / 100 = 80 % 男生录取率 =80/100=80\% 男生录取率=80/100=80% 高于女生的 60%。可以看到,在院系 A,女生表现更优;而在院系 B,虽然男生表现更好,但两院系的录取难度可能本身就不一样,比如院系 A的录取基准更严格,院系 B的相对宽松。
-
-
整体数据合并
将两个院系的数据合并计算整体录取率:
- 男生合计:
- 申请人数: 100 ( 院系 A ) + 100 ( 院系 B ) = 200 100(院系 A)+ 100(院系 B)= 200 100(院系A)+100(院系B)=200
- 录取人数: 60 + 80 = 140 60 + 80 = 140 60+80=140
- 录取率: 140 / 200 = 70 % 140/200 = 70\% 140/200=70%
- 女生合计:
- 申请人数: 20 ( 院系 A ) + 200 ( 院系 B ) = 220 20(院系 A)+ 200(院系 B)= 220 20(院系A)+200(院系B)=220
- 录取人数: 15 + 120 = 135 15 + 120 = 135 15+120=135
- 录取率: 135 / 220 ≈ 61.4 % 135/220 \approx 61.4\% 135/220≈61.4%
从合并后的数据看,男生的整体录取率(70%)高于女生(约61.4%),这一结果与院系 A中的趋势相反,也与院系 B中的局部情况不同。
- 男生合计:
关键在于权重分布:
- 女生更多申请到了竞争更激烈(录取率普遍较低)的院系 B;
- 男生则在两个院系间分布得较为均匀,所以高比例(较高录取率)的院系 B对男生整体录取率的贡献较大。
2.2 案例:肾结石治疗数据
经典的肾结石治疗案例中,研究人员将病例按结石大小分为“小结石组”和“大结石组”。具体数据如下:
| 成功例数 | 失败例数 | 总数 | 成功率 | |
|---|---|---|---|---|
| 小结石组 | ||||
| 治疗方法 A | 81 | 6 | 87 | 93.1% |
| 治疗方法 B | 234 | 36 | 270 | 86.7% |
| 大结石组 | ||||
| 治疗方法 A | 192 | 78 | 270 | 71.1% |
| 治疗方法 B | 55 | 28 | 83 | 66.3% |
在两个子组内,治疗方法 A 的成功率都高于 B。但合并后总体数据计算如下:
- 方法 A 合计: 81 + 192 = 273 成功,87 + 270 = 357 总例,成功率约 76.4%
- 方法 B 合计: 234 + 55 = 289 成功,270 + 83 = 353 总例,成功率约 81.9%
整体上看,治疗方法 B 的成功率超过 A,从而形成悖论。这种现象正是由于小结石组中两治疗方法的患者数量差异(治疗 A 在轻症患者中较多,而治疗 B 在重症患者中占比相对较高)所致。
3. 数学与图形表示
3.1 行列式公式的视角
在统计分析中,我们常使用二维列联表来表示分类数据。设某个 2×2 列联表为
M
=
(
a
b
c
d
)
,
M = \begin{pmatrix} a & b \\ c & d \end{pmatrix},
M=(acbd),
其中
a
a
a,
b
b
b,
c
c
c,
d
d
d 表示各类别对应的计数。定义 行列式 为
det
(
M
)
=
a
⋅
d
−
b
⋅
c
.
\det(M) = a \cdot d - b \cdot c.
det(M)=a⋅d−b⋅c.
在统计学中,行列式与 优势比(Odds Ratio, OR) 密切相关:
OR
=
a
⋅
d
b
⋅
c
.
\text{OR} = \frac{a \cdot d}{b \cdot c}.
OR=b⋅ca⋅d.
在各子组内,若 OR 大于 1,则说明第一行(例如某种处理效果)的情况更优;然而,当不同比例(即样本量或权重)混合在一起时,总体的
a
a
a,
b
b
b,
c
c
c,
d
d
d 为各子组的加权和,从而导致整体 OR 可能低于 1。如果各组的权重差异悬殊,那么对应的行列式符号或大小也会发生反转。这种现象就是辛普森悖论的数学基础之一。
举例说明:
对上述肾结石数据,可将每个组构造为一个列联表,计算各自的行列式:
-
小结石组:
det ( M 小 ) = ( 81 × 36 ) − ( 6 × 234 ) = 2916 − 1404 = 1512 \det(M_\text{小}) = (81 \times 36) - (6 \times 234) = 2916 - 1404 = 1512 det(M小)=(81×36)−(6×234)=2916−1404=1512 -
大结石组:
det ( M 大 ) = ( 192 × 28 ) − ( 78 × 55 ) = 5376 − 4290 = 1086 \det(M_\text{大}) = (192 \times 28) - (78 \times 55) = 5376 - 4290 = 1086 det(M大)=(192×28)−(78×55)=5376−4290=1086
虽然在各子组中由行列式可以反映出治疗方法 A(第一行)的优势,但当将两个组按各自样本量加权组合后,总计的列联表中 a a a, b b b, c c c, d d d 值发生了变化,从而可能使得整体计算的优势比(间接反映行列式的“符号”)倒转。
3.2 向量和向量图的解释
可以将每组数据用 向量 表示,其中向量的两个分量分别对应“成功比例”和“失败比例”。例如,对小结石组:
-
治疗方法 A 的向量表示为
v ⃗ A ( 小 ) = ( 81 87 , 6 87 ) \vec{v}_A^{(小)} = \left(\frac{81}{87}, \frac{6}{87}\right) vA(小)=(8781,876) -
治疗方法 B 的向量表示为
v ⃗ B ( 小 ) = ( 234 270 , 36 270 ) \vec{v}_B^{(小)} = \left(\frac{234}{270}, \frac{36}{270}\right) vB(小)=(270234,27036)
同理,对于大结石组亦然。
-
治疗方法 A 的向量表示为
v ⃗ A ( 大 ) = ( 192 270 , 78 270 ) \vec{v}_A^{(大)} = \left(\frac{192}{270}, \frac{78}{270}\right) vA(大)=(270192,27078) -
治疗方法 B 的向量表示为
v ⃗ B ( 大 ) = ( 55 83 , 28 83 ) \vec{v}_B^{(大)} = \left(\frac{55}{83}, \frac{28}{83}\right) vB(大)=(8355,8328)
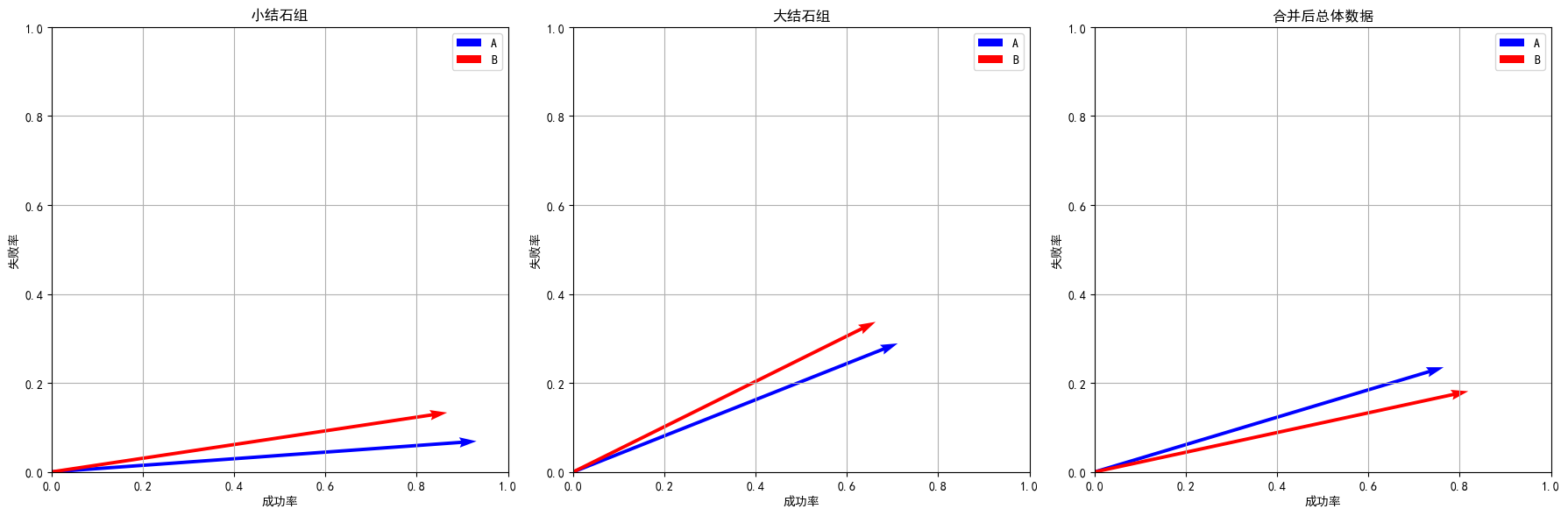
向量图示解释: -
在二维平面上,每个向量的坐标表示该治疗在某组的成功与失败比例。
-
各子组内,若 v ⃗ A \vec{v}_A vA的“方向”(指向高成功率区域)优于 v ⃗ b \vec{v}_b vb,说明在该组内 A 更有效。
-
合并数据时,相当于对各子组向量按照各组的样本量进行加权平均,即:
v ⃗ 总体 = λ v ⃗ ( 小 ) + ( 1 − λ ) v ⃗ ( 大 ) \vec{v}_\text{总体} = \lambda \vec{v}^{(小)} + (1 - \lambda) \vec{v}^{(大)} v总体=λv(小)+(1−λ)v(大)
其中 λ \lambda λ 表示小结石组的权重。 -
如果两个子组的权重差异巨大,加权后的总体向量可能偏向于样本量较多的组,而该组内两治疗方法的优劣差异较小甚至反转,就会出现整体数据与各子组数据“方向”相反的情况。
-
每个子组的向量在坐标平面中指向某一方向;
-
加权平均后的总体向量可能落在两个向量之间,但如果权重极不平衡,则总体向量的位置与单个组的直观判断不一致,从而导致悖论现象。
4. 解决方法
4.1 分层(分组)分析
- 必要性:
辛普森悖论正是由于在聚合数据时忽略了重要的分层信息或混杂变量。解决的第一步就是对数据进行分组分析,找出可能的混杂因素,如病情、年龄、性别等。 - 方法:
在分析时,先计算各子组内的指标(如成功率、比例或优势比),然后再分别报告各组结果,不直接依赖总计数据进行结论。
4.2 控制混杂变量
- 回归分析:
使用多变量回归模型,将混杂变量作为控制变量纳入模型,通过调整后得到更加可靠的结论。 - 倾向得分匹配(Propensity Score Matching):
对观测数据进行倾向得分匹配,确保两个处理组在混杂变量上相对平衡,从而减弱偏倚。
4.3 数据可视化与统计检验
- 图形表示:
采用分组的散点图、条形图或者向量图,直观地展示各子组数据以及聚合数据的差异,便于识别混杂因素的影响。 - 统计检验:
对各子组及整体数据进行统计假设检验,判断各分组之间是否存在显著差异,并测试聚合数据下的变化是否具有统计学意义。
4.4 建立因果模型
- 因果图(DAG):
使用因果图展示变量之间的关系,理清哪些变量是因果因素,哪些是混杂因素,从而更准确地解释数据间的关系。 - 结构方程模型(SEM):
通过建立结构方程模型,将测量误差、潜在变量同时纳入分析,更全面地理解数据生成过程。
5.总结
- 本质:
辛普森悖论突显了在统计分析中,仅仅依靠汇总数据可能导致误导性结论,特别是在存在混杂因素或不平衡权重的情况下。 - 数学解释:
从行列式与优势比的角度,数据加权合并可能改变数值关系;从向量与图形角度看,不同比例的加权平均会使整体数据“偏移”,从而引发趋势反转。 - 解决之道:
针对辛普森悖论,数据分析时需关注分层分析、混杂变量控制和因果关系的建立。只有在充分考虑所有潜在因素后,才能得出合理的结论,避免因数据聚合而产生的误判。
通过以上详细讨论,我们可以看到辛普森悖论不仅仅是一个统计现象,更反映了数据分析中对分层和因果关系理解的重要性。科学合理地处理数据,对避免和解释类似悖论具有重要意义。

















 3368
3368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









