






背景
之前已经挑战过了基于onnxruntime部署yolo11n, 现在试试部署ocr汉字识别模型。
- 这里我们选用rapidocr(提供图片预处理和推理api封装,以及paddleocr的onnx格式模型,包含识别和检测两个模型 )
核心推理逻辑
模型文件可以在modelscope下载:https://modelscope.cn/studios/aiboycoder/RapidOCR
选择v4版本的最轻量级模型
import numpy as np
import onnxruntime
from PIL import Image
import os
from rapidocr_onnxruntime import RapidOCR, VisRes
class PaddleOCRInference:
def __init__(self, det_model_path=None,rec_model_path=None, box_thresh=0.5, unclip_ratio=1.6, text_score=0.5):
self.rapid_ocr = RapidOCR(
det_model_path=det_model_path,
rec_model_path=rec_model_path,
rec_img_shape=[3,48,320],
)
self.box_thresh = box_thresh
self.unclip_ratio = unclip_ratio
self.text_score = text_score
def predict(self, img):
ocr_result, infer_elapse = self.rapid_ocr(
img, box_thresh=self.box_thresh, unclip_ratio=self.unclip_ratio, text_score=self.text_score
)
return ocr_result
dockerfile编写
# 使用 Python 3.13 作为基础镜像
FROM python:3.13-slim
# 设置工作目录
WORKDIR /app
# 设置环境变量
ENV PYTHONPATH=/app
ENV PYTHONUNBUFFERED=1
ENV PYTHONDONTWRITEBYTECODE=1
# 复制项目文件
COPY . /app/
# 安装 Python 依赖
RUN pip install --no-cache-dir -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
RUN pip install --no-cache-dir gunicorn -i https://pypi.tuna.tsinghua.edu.cn/simple
# 暴露端口
EXPOSE 8000
# 使用 gunicorn 运行应用
CMD ["gunicorn", "server:app", \
"--workers", "4", \
"--worker-class", "uvicorn.workers.UvicornWorker", \
"--bind", "0.0.0.0:8000", \
"--timeout", "120"]
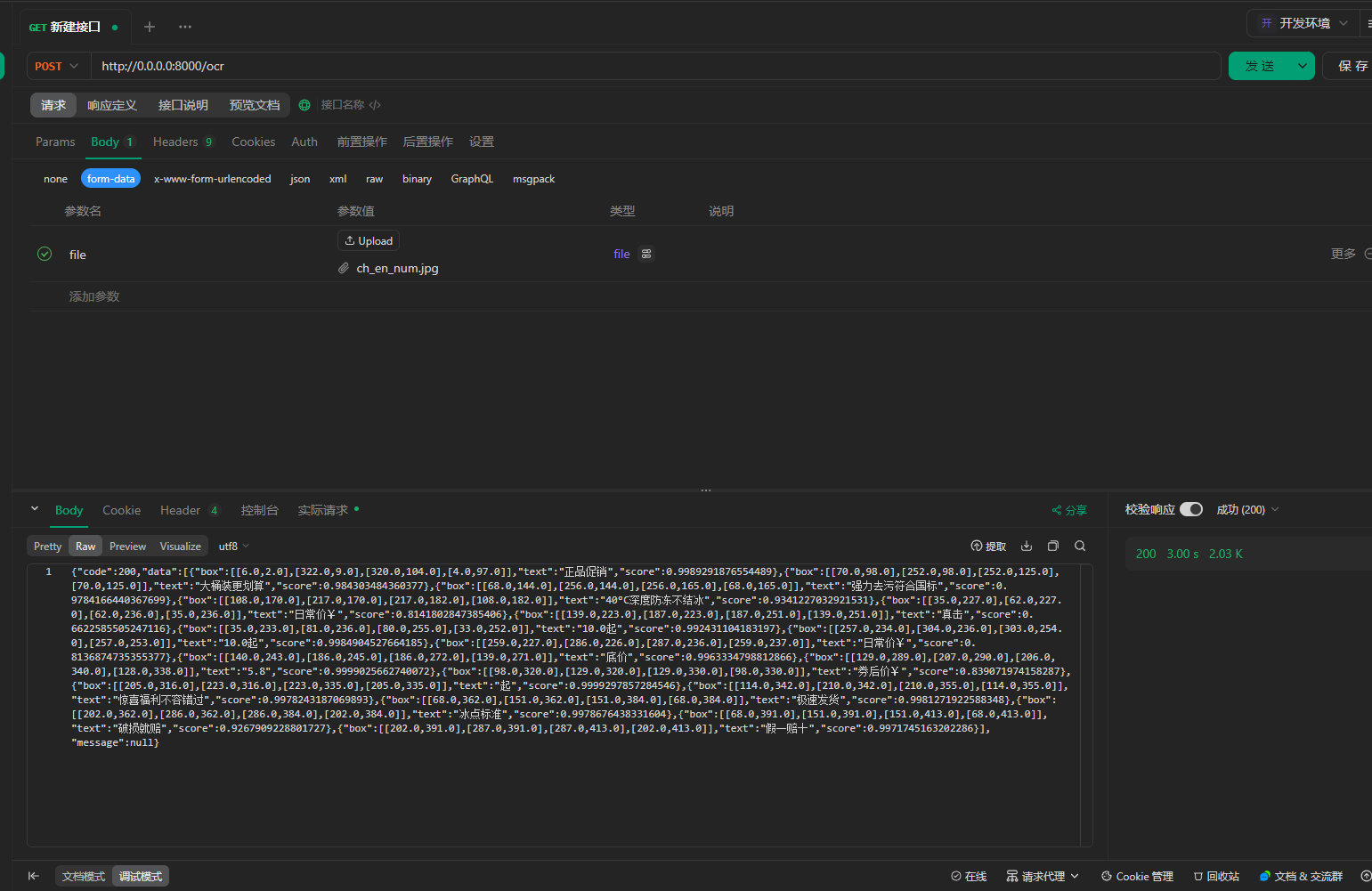
测试图片识别

识别结果json
- 包含检测区域、识别文本、置信度
{"code":200,"data":[{"box":[[6.0,2.0],[322.0,9.0],[320.0,104.0],[4.0,97.0]],"text":"正品促销","score":0.9989291876554489},{"box":[[70.0,98.0],[252.0,98.0],[252.0,125.0],[70.0,125.0]],"text":"大桶装更划算","score":0.984303484360377},{"box":[[68.0,144.0],[256.0,144.0],[256.0,165.0],[68.0,165.0]],"text":"强力去污符合国标","score":0.9784166440367699},{"box":[[108.0,170.0],[217.0,170.0],[217.0,182.0],[108.0,182.0]],"text":"40°C深度防冻不结冰","score":0.9341227032921531},{"box":[[35.0,227.0],[62.0,227.0],[62.0,236.0],[35.0,236.0]],"text":"日常价¥","score":0.8141802847385406},{"box":[[139.0,223.0],[187.0,223.0],[187.0,251.0],[139.0,251.0]],"text":"真击","score":0.6622585505247116},{"box":[[35.0,233.0],[81.0,236.0],[80.0,255.0],[33.0,252.0]],"text":"10.0起","score":0.992431104183197},{"box":[[257.0,234.0],[304.0,236.0],[303.0,254.0],[257.0,253.0]],"text":"10.0起","score":0.9984904527664185},{"box":[[259.0,227.0],[286.0,226.0],[287.0,236.0],[259.0,237.0]],"text":"日常价¥","score":0.8136874735355377},{"box":[[140.0,243.0],[186.0,245.0],[186.0,272.0],[139.0,271.0]],"text":"底价","score":0.9963334798812866},{"box":[[129.0,289.0],[207.0,290.0],[206.0,340.0],[128.0,338.0]],"text":"5.8","score":0.9999025662740072},{"box":[[98.0,320.0],[129.0,320.0],[129.0,330.0],[98.0,330.0]],"text":"券后价¥","score":0.839071974158287},{"box":[[205.0,316.0],[223.0,316.0],[223.0,335.0],[205.0,335.0]],"text":"起","score":0.9999297857284546},{"box":[[114.0,342.0],[210.0,342.0],[210.0,355.0],[114.0,355.0]],"text":"惊喜福利不容错过","score":0.9978243187069893},{"box":[[68.0,362.0],[151.0,362.0],[151.0,384.0],[68.0,384.0]],"text":"极速发货","score":0.9981271922588348},{"box":[[202.0,362.0],[286.0,362.0],[286.0,384.0],[202.0,384.0]],"text":"冰点标准","score":0.9978676438331604},{"box":[[68.0,391.0],[151.0,391.0],[151.0,413.0],[68.0,413.0]],"text":"破损就赔","score":0.9267909228801727},{"box":[[202.0,391.0],[287.0,391.0],[287.0,413.0],[202.0,413.0]],"text":"假一赔十","score":0.9971745163202286}],"message":null}
接口耗时:三秒
总结
- 磁盘占用少。 使用onnxruntime,cpu版本docker镜像几百MB磁盘占用。而paddlehub版本,我找过轻量级的镜像就得2GB,推理10多秒。

- 推理速度快于paddlehub运行的api接口服务。
疑问
ocr模型对于横向排列文本,且文字之间存在逻辑关联, 识别到一块是没问题。
但是如果文本是两行展示,两行文本合并到一起才是想要的结果, 如何关联?大概得后处理一下吧


















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









