







统计过程中对每一个MapTask的输出进行局部汇总,以减小网络传输量。
2. 文件
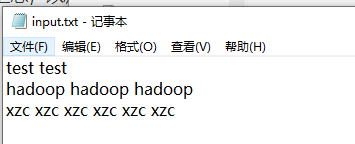
1. 需求分析
可以采用Combiner功能来对每个MapTask的输出进行局部汇总,从而达到减小网络传输量。
2. 输入数据
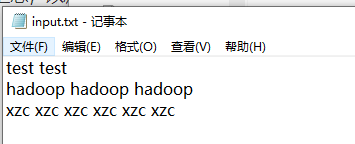
3. 期望输出数据
Combine输入数据多,输出时经过合并,输出数据降低(观察输出控制台可以看出来)
4. 实施方案
(1)方案一
-
增加一个WordcountCombiner类继承Reducer
-
在WordcountCombiner中统计单词汇总,并将统计结果输出。
(2)方案二
- 将WordcountCombiner作为Combiner在WordcontDriver驱动类中指定
job.setCombinerClass(WordcountReducer.class);
必看视频!获取2024年最新Java开发全套学习资料 备注Java
1. 基于wordcount案例
2. 方案一
1)增加一个WordcountCombiner类继承Reducer
package com.atguigu.mr.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//累加求和
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
v.set(sum);
//写出
context.write(key, v);
}
}
2)在WordcountDriver驱动类中指定Combiner
// 指定需要使用combiner,以及用哪个类作为combiner的逻辑
job.setCombinerClass(WordcountCombiner.class);
写在最后
很多人感叹“学习无用”,实际上之所以产生无用论,是因为自己想要的与自己所学的匹配不上,这也就意味着自己学得远远不够。无论是学习还是工作,都应该有主动性,所以如果拥有大厂梦,那么就要自己努力去实现它。
最后祝愿各位身体健康,顺利拿到心仪的offer!
由于文章的篇幅有限,所以这次的蚂蚁金服和京东面试题答案整理在了PDF文档里



体健康,顺利拿到心仪的offer!
由于文章的篇幅有限,所以这次的蚂蚁金服和京东面试题答案整理在了PDF文档里
[外链图片转存中…(img-8wtwCB6s-1716405781004)]
[外链图片转存中…(img-pN6ZFXYB-1716405781005)]
[外链图片转存中…(img-egUJ77HE-1716405781005)]















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









