









K-Means算法是一种常见且高效的无监督聚类算法,广泛应用于数据挖掘和机器学习领域。它通过将数据点划分为K个簇,极大简化了数据的复杂性。这一期我们来学习这个简单且强大的算法。

一、算法原理
K-means算法具有一个选代过程,在这个过程中,数据集被分组成若干个预定义的不重叠的聚类或子组,使簇的内部点尽可能相似,同时试图保持簇在不同的空间。

算法原理如下:
1.随机初始化聚类中心
μ
1
,
μ
2
,
.
.
.
,
μ
k
∈
R
n
\mu_1,\mu_2,...,\mu_k\in\mathbb{R}^n
μ1,μ2,...,μk∈Rn。通常从样本中选取
K
K
K个样本,然后将这些样本坐标赋值给各初始聚类中心。
2.将每一个样本点
(
i
∈
[
1
,
…
,
m
]
)
(i\in[1,\ldots,m])
(i∈[1,…,m])赋值为距离它最近的中心编号:
c
(
i
)
:
=
a
r
g
m
i
n
∥
∥
x
(
i
)
−
μ
j
∥
∥
2
.
c^{(i)}{:}=argmin\|\|x^{(i)}-\mu_j\|\|^2.
c(i):=argmin∥∥x(i)−μj∥∥2.
K
K
K是拟获取的聚类数量,
μ
j
\mu_{j}
μj表示当前估计的第
j
j
j个中心的位置。根据从属于该中心的样本点,重新计算当前中心的位置。
3.对于每一个中心
(
j
∈
[
1
,
…
,
k
]
)
(j\in[1,\ldots,k])
(j∈[1,…,k]),设置其更新后的中心位置为:
μ
j
:
=
∑
i
=
1
m
1
{
c
(
i
)
=
j
}
x
(
i
)
∑
i
=
1
m
1
{
c
(
i
)
=
j
}
.
\mu_j:=\frac{\sum_{i=1}^m1\{c^{(i)}=j\}x^{(i)}}{\sum_{i=1}^m1\{c^{(i)}=j\}}.
μj:=∑i=1m1{c(i)=j}∑i=1m1{c(i)=j}x(i).
上述第2、3步需要迭代执行,直到收敛为止。
4.收敛条件设置:定义如下目标函数:
J
(
c
,
μ
)
=
∑
i
=
1
m
∥
x
(
i
)
−
μ
c
(
i
)
∥
2
.
J(c,\mu)=\sum_{i=1}^m\left\|x^{(i)}-\mu_{c^{(i)}}\right\|^2.
J(c,μ)=i=1∑m
x(i)−μc(i)
2.
衡量每一个训练样本
x
(
i
)
x^{(i)}
x(i)和相应聚类中心
μ
c
(
i
)
\mu_{c}(i)
μc(i)之间的距离平方之和。
通常为了获得更好的聚类结果,保证K-means尽量接近全局最优,可以运行K-means算法多次,最后选择目标函数最小的中心点进行聚类。
二、代码展示
算法手推
import math
import random
import matplotlib.pyplot as plt
def dataloader(path):
xy = []
f = open(path, 'r')
for line in f:
x1, y1 = map(float, line.split())
xy.append([x1, y1, 0]) # each point donated as [x,y,label]
f.close()
return xy
def start_random(xy, k=4):
# choose k points as start_centers
start_centers = random.sample(xy, k) # choose k init_points to start
for i in range(k):
start_centers[i][2] = i # set color of point as red
# print('start_point=', start_centers)
return start_centers
def cul_dis(xy, centers):
for i in range(len(xy)): # point=[x,y,label==0]
mean_dis = 0
for center in centers: # center=[x,y,i]
dis = math.sqrt((xy[i][0] - center[0])**2 + (xy[i][1] - center[1])**2)
if center[2] == 0:
mean_dis = dis
xy[i][2] = center[2]
else:
if dis < mean_dis:
mean_dis = dis
xy[i][2] = center[2]
# print(xy)
return xy
def update_center(xy_dis, k):
num_class = [0 for i in range(k)]
centers_x = [0 for i in range(k)]
centers_y = [0 for i in range(k)]
centers = []
for dot in xy_dis:
i = dot[2]
centers_x[i] += dot[0]
centers_y[i] += dot[1]
num_class[i] += 1
for i in range(k):
centers_x[i] = centers_x[i]/num_class[i]
centers_y[i] = centers_y[i]/num_class[i]
centers.append([centers_x[i], centers_y[i], i])
return centers
def plt_scatter(xy,centers):
x = []
y = []
color = ['olive', 'y', 'yellow', 'olivedrab', 'yellowgreen', 'darkolivegreen', 'greenyellow', 'sage']
for i in range(len(xy)):
plt.scatter(xy[i][0], xy[i][1], c=color[xy[i][2]])
for center in centers:
plt.scatter(center[0],center[1], c='r')
plt.show()
def main():
k = 4
xy = dataloader(r'.\testSet.txt')
# plt_scatter(x, y)
start_centers = start_random(xy,k)
xy_dis = cul_dis(xy, start_centers)
centers = update_center(xy_dis, k)
# print(centers)
for epoch in range(4000):
xy_dis = cul_dis(xy_dis, centers)
centers = update_center(xy_dis, k)
plt_scatter(xy_dis, centers)
if __name__ == '__main__':
main()
OpenCV调用
import numpy as np
import cv2
import matplotlib.pyplot as plt
def dataloader(path):
xy = []
f = open(path, 'r')
for line in f:
x1, y1 = map(float, line.split())
xy.append([x1, y1])
f.close()
return np.array(xy, dtype=np.float32)
def kmeans_opencv(xy, k=4, max_iter=1000):
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, max_iter, 1.0)
_, labels, centers = cv2.kmeans(xy, k, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
return labels.flatten(), centers
def plt_scatter(xy, labels, centers):
color = ['olive', 'y', 'yellow', 'olivedrab', 'yellowgreen', 'darkolivegreen', 'greenyellow', 'sage']
for i in range(len(xy)):
plt.scatter(xy[i][0], xy[i][1], c=color[labels[i]])
for center in centers:
plt.scatter(center[0], center[1], c='r')
plt.show()
def main():
k = 4
xy = dataloader(r'.\testSet.txt')
labels, centers = kmeans_opencv(xy, k)
plt_scatter(xy, labels, centers)
if __name__ == '__main__':
main()
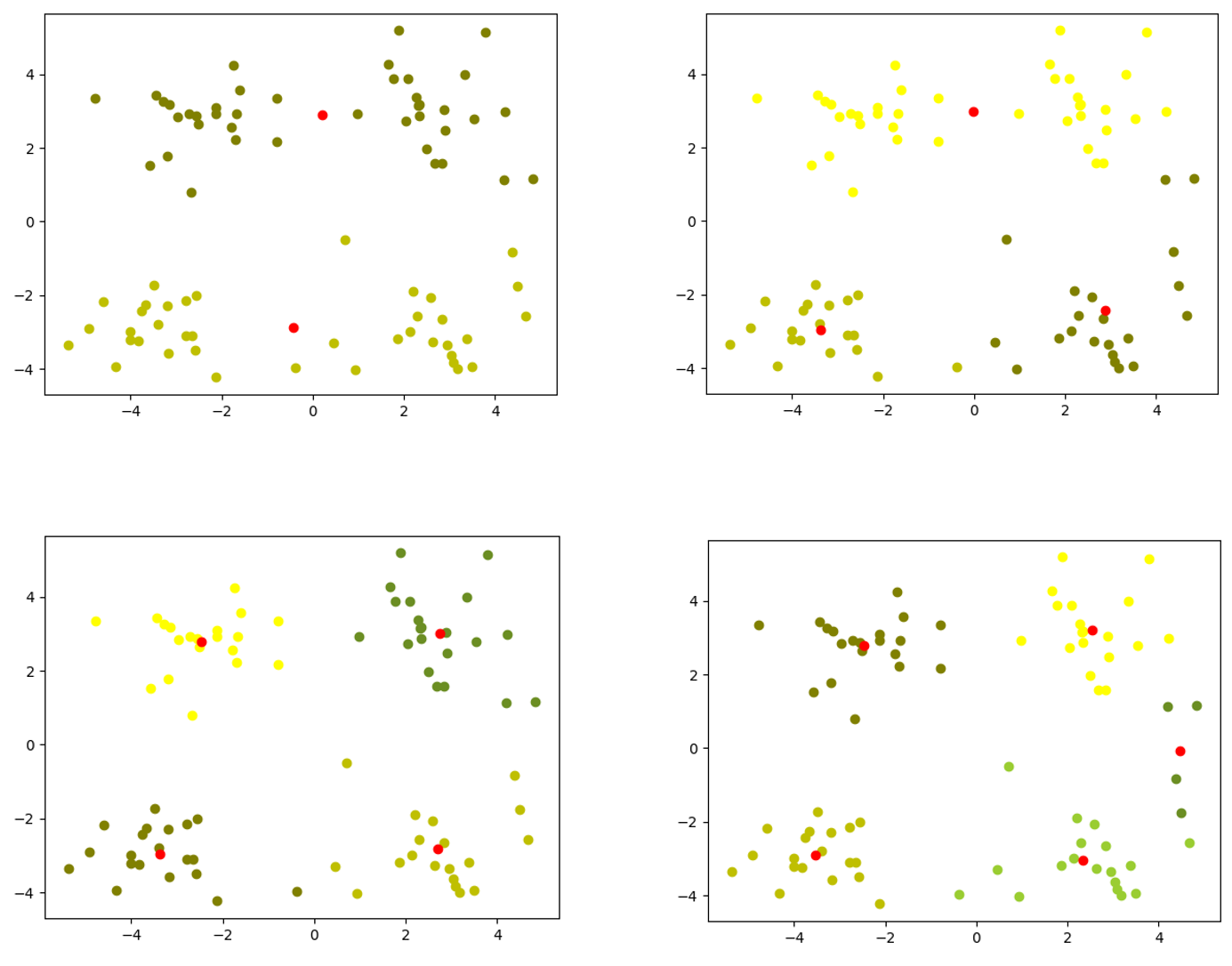
三、结果可视化
K
K
K依次取值2、3、4、5时的分类结果















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









