







 本文介绍了robots.txt文件的作用,包括定义User-agent、Disallow、Allow、Sitemap和Crawl-delay等规则,帮助网站管理员控制搜索引擎对网站的访问,保护隐私和服务器资源。
本文介绍了robots.txt文件的作用,包括定义User-agent、Disallow、Allow、Sitemap和Crawl-delay等规则,帮助网站管理员控制搜索引擎对网站的访问,保护隐私和服务器资源。
目录
一、简介
robots.txt 是一个文本文件,通常位于网站的根目录下,用于指示爬虫程序哪些页面可以访问,哪些页面不可以访问。它的主要目的是帮助网站管理员控制搜索引擎对网站的爬取行为,以及指示用户禁止访问的url和可以访问的url。在网站域名后加上/robots.txt即可读取此文件的内容。以下是 robots.txt 文件中可能包含的一些常见规则。
二、常见规则
1.User-agent
表示访问网站的搜索引擎。User-agent: *表示该规则适用于所有的搜索引擎,若后面加具体的搜索引擎名字则表明该搜索引擎需要遵守的规则。
示例:
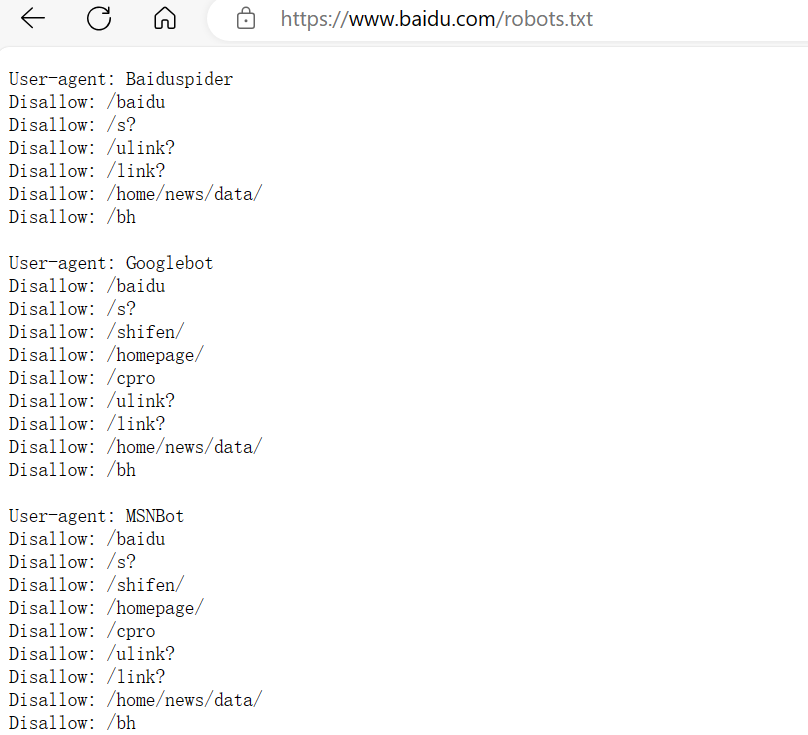
2.Disallow
用于指示搜索引擎不应该访问的页面或目录。如上图,表示根目录下的/baidu不允许Baiduspider访问。当Disallow的值为/时表示不允许访问任何内容。
3.Allow
用于指示搜索引擎可以访问的特定页面或目录。通常,如果没有特定的规则,搜索引擎会默认允许访问所有页面,所以 Allow 指令通常是不必要的。
4.Sitemap
用于提供网站中所有可以被爬出的页面或目录。
5.Crawl-delay
用于提醒搜索引擎在访问网站时应该等待多长时间之后再次爬取页面。这个指令对于控制爬虫访问频率非常有用,可以避免对服务器造成过大的负担,同时也能保护网站的数据和资源。
robots.txt 文件的规则通常使用简单的文本格式编写,搜索引擎会根据这些规则来决定它们是否可以访问网站的特定页面或目录。robots.txt 文件是网站管理者与搜索引擎之间的一种约定,通过合理配置 robots.txt 文件,可以帮助网站管理员更好地管理搜索引擎的行为,保护网站的隐私和安全。

















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









