







目录
merge命令
merge 命令使用像 SQL 的连接方式
提示:下面的pd表示为pandas的缩写
pd.merge(
需要合并的 DF
left :需要合并的左侧 DF
right :需要合并的右侧 DF
how = ' inner':具体的连接类型 {left、right 、outer 、 inner、)
!!提示:Pandas中数据的横向合并merge中参数默认值how=inner
两个 DF (二维数组)的连接方式:
on :用于连接两个 DF 的关键变量(多个时为列表),必须在两侧都出现
left_on :左侧 DF 用于连接的关键变量(多个时为列表)
right_on :右侧 DF 用于连接的关键变量(多个时为列表)
left_index = False :是否将左侧 DF 的索引用于连接
right_index = False :是否将右侧 DF 的索引用于连接 )
【代码示例】:
import pandas as pd
left=pd.DataFrame({'key':['k0','k1','k2','k3'], 'A': ['A0','A1','A2','A3'],'B': ['B0','B1','B2','B3'],})
right=pd.DataFrame({'key':['k0','k1','k2','k3'],'C': ['C0','C1','C2','C3'], 'D': ['D0','D1','D2','D3'],})
result1=pd.merge(left,right)
print(result1)
print('\n')
#how参数的使用
left=pd.DataFrame({'key':['k0','k1','k2','k3'],'A':['A0','A1','A2','A3'],'B': ['B0','B1','B2','B3'],})
right=pd.DataFrame({'key':['k0','k1','k2','k4'],'C': ['C0','C1','C2','C3'],'D':['D0','D1','D2','D3'],})
result2=pd.merge(left,right,how='left')
print(result2)
print('\n')
#left_on right_on
left=pd.DataFrame({'key1':['k0','k1','k2','k3'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3'],})
right=pd.DataFrame({'key2':['k0','k1','k2','k4'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3'],})
result3=pd.merge(left,right,how='left',left_on='key1',right_on='key2')
print(result3)
print('\n')
#left_index right_index
left = left.set_index(keys='key1')
right = right.set_index(keys='key2')
result4=pd.merge(left,right,left_index=True,right_index=True)
print(result4)
print('\n')【执行结果】:
concat命令
同时支持横向合并与纵向合并
pd.concat(
objs :需要合并的对象,列表形式提供
axis = 0 :对行还是对列方向逬行合并 (0:index 、 1:columns )
join = outer :对另一个轴向的索引值如何逬行处理 (inner 、outer )
ignore_index = False
keys = None :为不同数据源的提供合并后的索引值
verify_integrity = False 是否检查索引值的唯一性,有重复时报错
copy=True)
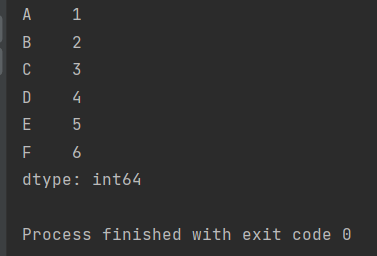
【示例】一维的Series拼接:
import pandas as pd
ser1=pd.Series([1,2,3],index=list('ABC'))
ser2=pd.Series([4,5,6],index=list('DEF'))
print(pd.concat([ser1,ser2]))【运行结果】:
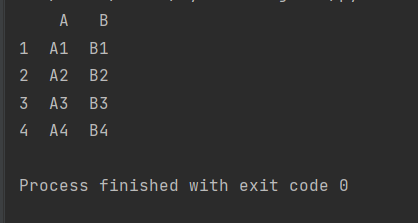
【示例】df对象拼接:
import pandas as pd
def make_df(cols,index):
data={c:[str(c)+str(i) for i in index] for c in cols}#字典生成式
return pd.DataFrame(data,index=index)
df1=make_df('AB',[1,2])
df2=make_df('AB',[3,4])
print(pd.concat([df1,df2]))【结果】
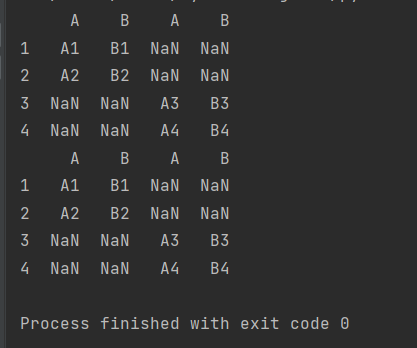
【示例】两个df对象拼接,按列进行拼接
'''两个DF对象进行拼接,按列进行拼接'''
import pandas as pd
def make_df(cols,index):
data={c:[str(c)+str(i) for i in index] for c in cols}#字典生成式
return pd.DataFrame(data,index=index)
df1=make_df('AB',[1,2])
df2=make_df('AB',[3,4])
print(pd.concat([df1,df2],axis=1))
#或者:
print(pd.concat([df1,df2],axis='columns'))【结果】
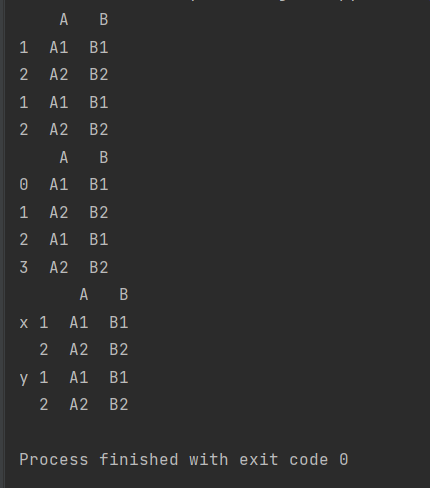
【示例】两个df对象拼接,如果索引重复
'''两个df对象拼接,如果索引重复'''
import pandas as pd
def make_df(cols,index):
data={c:[str(c)+str(i) for i in index] for c in cols}#字典生成式
return pd.DataFrame(data,index=index)
x=make_df('AB',[1,2])
y=make_df('AB',[1,2])
print(pd.concat([x,y]))
#解决索引重复问题加ignore_index属性
print(pd.concat([x,y],ignore_index=True))
#解决索引重复问题,加keys属性
print(pd.concat([x,y],keys=list('xy')))【结果】
【示例】两个df对象拼接,join参数的使用
'''两个df对象拼接,join参数的使用'''
import pandas as pd
def make_df(cols,index):
data={c:[str(c)+str(i) for i in index] for c in cols}#字典生成式
return pd.DataFrame(data,index=index)
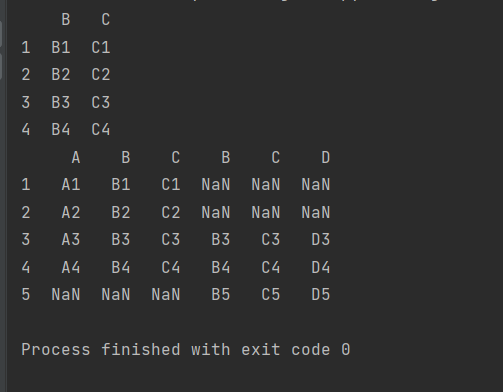
a=make_df('ABC',[1,2])
b=make_df('BCD',[3,4])
print(pd.concat([a,b],join='inner'))
a=make_df('ABC',[1,2,3,4])
b=make_df('BCD',[3,4,5])
print(pd.concat([a,b],join='outer',axis=1))【结果】















 8316
8316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









