









目录
当模型中增加更多的自变量时,即使这些变量对模型没有贡献,R方也可能会增加。而statsmodels库中的调整R方可以通过惩罚模型中自变量的数量来解决这个问题,适用于多元线性回归。本代码将使用statsmodels库实现二元线性回归的拟合与预测,并使用调整R方,T检验和F检验评价拟合与预测的效果。
1.简介
statsmodels 是一个Python库,用于进行统计分析,包括描述性统计、概率分布、统计测试、回归分析等。它提供了一个灵活和全面的框架,用于建模和评估数据。statsmodels 库建立在NumPy、SciPy和Pandas等库之上,能够处理各种统计模型,并提供详细的结果。
2.调整R方(Adjusted R-squared)
计算公式:![]()
其中, 是R方值, 𝑛是是样本数量,𝑘是自变量的数量。
调整R方接近1时,代表自变量与因变量之间存在较强的线性关系。
3.T检验
计算公式: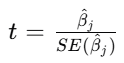
其中,是第 𝑗个自变量的回归系数估计值,𝑆𝐸(
) 是该系数的标准误差。
通过对回归系数与0的检验,看其是否有显著性差异,来判断回归系数是否显著,用于检验系数是否显著。临界值为0.05,小于0.05时代表模型中至少有一个自变量的系数在统计上显著,即至少有一个自变量对因变量的影响是显著的。
4.F检验
计算公式:![]()
和
分别是缩减模型(只包含截距的模型)和完整模型的残差平方和,𝑘是完整模型中自变量的数量,𝑝是缩减模型中自变量的数量(通常为1),𝑛是样本数量。
检验自变量x与因变量y之间的线性关系是否显著,或者说,它们之间能否用一个线性模型来表示,是对于整个方程显著性的检验。临界值为0.05,小于0.05时代表整个回归模型(所有自变量作为一个整体)对因变量的解释是有统计学意义的,即模型整体是有效的。
5.数据格式
6.代码示例
import pandas as pd
import statsmodels.api as sm
# 导入数据
data = pd.read_csv("多元线性回归.csv", encoding='gbk', engine='python')
# 选择自变量和因变量
x = data[['体重', '年龄']]
y = data['血压收缩']
# 为自变量添加截距项
x = sm.add_constant(x)
# 创建OLS模型
model = sm.OLS(y, x)
# 拟合模型
results = model.fit()
# 打印模型的摘要,包含调整R方、F检验和T检验等统计信息
print(results.summary())
# 使用回归模型进行预测
# 预测新的数据点
new_data = pd.DataFrame([[80, 60], [70, 30], [70, 20]], columns=['体重', '年龄'])
new_data = sm.add_constant(new_data) # 为新数据添加截距项
predictions = results.predict(new_data)
# 打印预测结果
print(predictions)
# 查看参数
a = results.params[1:] # 系数
b = results.params[0] # 截距
# 打印线性回归模型
print("线性回归模型为: y = {:.2f} + {:.2f}x1 + {:.2f}x2.".format(b, a[0], a[1]))7.结果分析
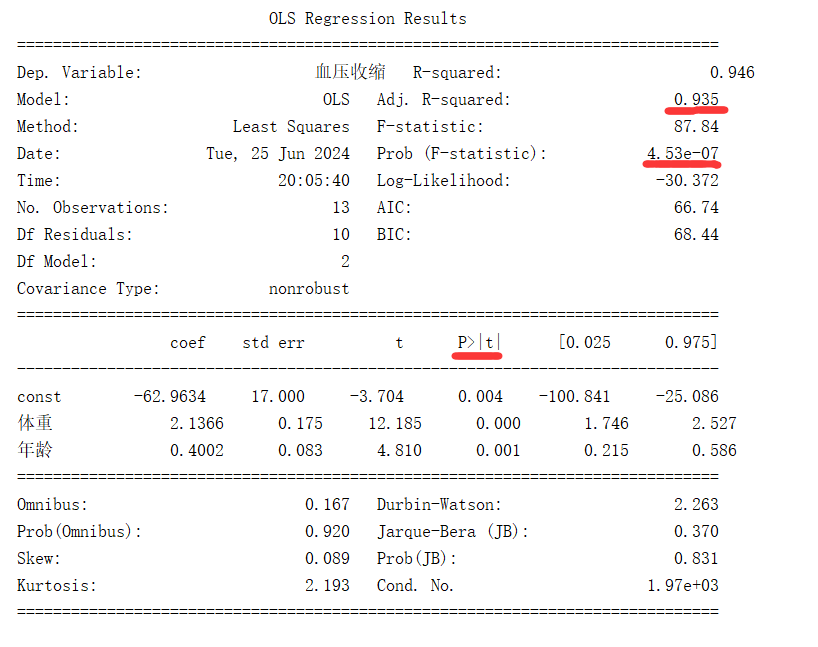
![]()
Adj. R-squared:即调整R方,此处为0.935,接近1,代表自变量与因变量之间存在较强的线性关系。
Prob (F-statistic):即F检验,此处为4.53e-07,小于0.05,代表模型整体是有效的。
P>|t|:即T检验,此处为0.004,小于0.05,代表至少有一个自变量对因变量的影响是显著的。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









