







函数loadtxt用于从文本文件中加载数据并返回一个numpy数组,其主要参数如下:

| 参数 | 含义 |
| fname | 被加载的文件路径或文件对象 |
| dtype | 读取数据时的数据类型 |
| comments | 跳过文件中指定参数开头的行(即不读取) |
| delimiter | 指定读取文件中数据的分割符 |
| converters | 对读取的数据进行预处理 |
| skiprows | 选择跳过的行数 |
| usecols | 指定需要读取的列 |
| unpack | 选择是否将数据进行向量输出 |
| encoding | 对读取的文件进行预编码 |
| max_rows | 最大读取的行数 |
| like | 用于指定新数组的同型对象 |
接下来以下表格为例展示每个参数的运用过程 ,将表格保存为1.csv

①fname,dtype
fname:本文选定的读取文件为‘1.csv’
dtype:dtype=str,表示读取时采用的为字符串类型
a = np.loadtxt('1.csv',dtype=str)
print (a)输出结果如下,可以看出每行都单独作为一个字符串输出

② comments
comments意为跳过以comments参数开头的内容,例如下图,l开头的表头字符串被跳过
a = np.loadtxt('1.csv',dtype=str, comments='l')
print (a)![]()
③ delimiter
没有使用delimiter参数进行分割时,默认是将整个数据一起输出,使用delimiter分割“,”,结果与字符串分割中的split()函数类似
a = np.loadtxt('1.csv',dtype=str,comments='l',delimiter=',')
print (a)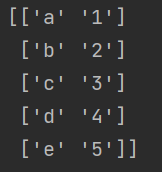
④converters
将某一列的数据进行函数预处理再获取,格式为:{列号:函数},可以看成一个字典形式,对列上的所有数据进行函数处理,如下完成了使输出的第二列数据全部+1的效果
def func(x):
return int(x)+1
a = np.loadtxt('1.csv',dtype=str,comments='l',delimiter=',',converters={1:func})
print (a)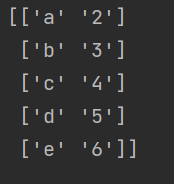
⑤skiprows
用于指定读取时忽略的行数,默认从首行开始计数,skiprows=1时,列名就会被跳过
def func(x):
return int(x)+1
a = np.loadtxt('1.csv',dtype=str,comments='l',delimiter=','
,converters={1:func},skiprows=1)
print (a)
可以看出由于表头虽然被comments跳过,但skiprows的跳过依然从表头开始
⑥usecols
用于指定需要使用的列,csv的列数计算从0开始,例如单独提取数字列
def func(x):
return int(x)+1
a = np.loadtxt('1.csv',dtype=str,comments='l',delimiter=','
,converters={1:func},skiprows=1,usecols=1)
print (a)![]()
⑦unpack
默认是False,即将数据逐行输出,当设置为True时,数据将逐列输出。
def func(x):
return int(x)+1
a = np.loadtxt('1.csv',dtype=str,comments='l',delimiter=','
,converters={1:func},skiprows=1,unpack=True)
print (a)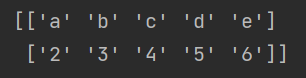
⑧encoding
决定读取文件时使用的编码方式,也就是对文件编码方式进行更改,例如csv文件中若存在中文则可能需要采用utf-8的编码方式
⑨max_rows
为最终读取的行数,此处的行数计数从经过comments与skiprows跳过的剩余行中开始
def func(x):
return int(x)+1
a = np.loadtxt('1.csv',dtype=str,comments='l',delimiter=','
,converters={1:func},skiprows=1,unpack=True,max_rows=2)
print (a)
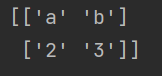















 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









