






 本文介绍了AlexNet的早期神经网络架构,探讨了CNN在物体识别中的应用,如何通过数据增强和Dropout降低过拟合,以及使用SGD进行模型训练的细节。着重讲述了如何处理过拟合问题和利用多GPU进行模型并行计算的方法。
本文介绍了AlexNet的早期神经网络架构,探讨了CNN在物体识别中的应用,如何通过数据增强和Dropout降低过拟合,以及使用SGD进行模型训练的细节。着重讲述了如何处理过拟合问题和利用多GPU进行模型并行计算的方法。
学习初期为了方便理解和之后查看而写,总体都是来自于哔站李沐老师。
AlexNet,主要是看看当年的思路,里面有很多东西实际上不适用于现在的发展。
1.介绍部分
物体的识别,通过更大的数据集来实现目标。还得避免过拟合(正则优化)。
用CNN来做一个超级大的神经网络。CNN有点难训练,但是GPU的使用提高了训练速度。
用新的技术一定程度上解决了过拟合的问题。
对于预处理部分,作者把一个图片处理成了256*256大小,多余的部分会以中心为界裁掉。
2.网络架构
2.1.ReLU Nonlinerity(非线性)
用了这个东西会让训练变得很快。(现在也不是很正确,这是一开始的简单的结构)
2.2overall 架构
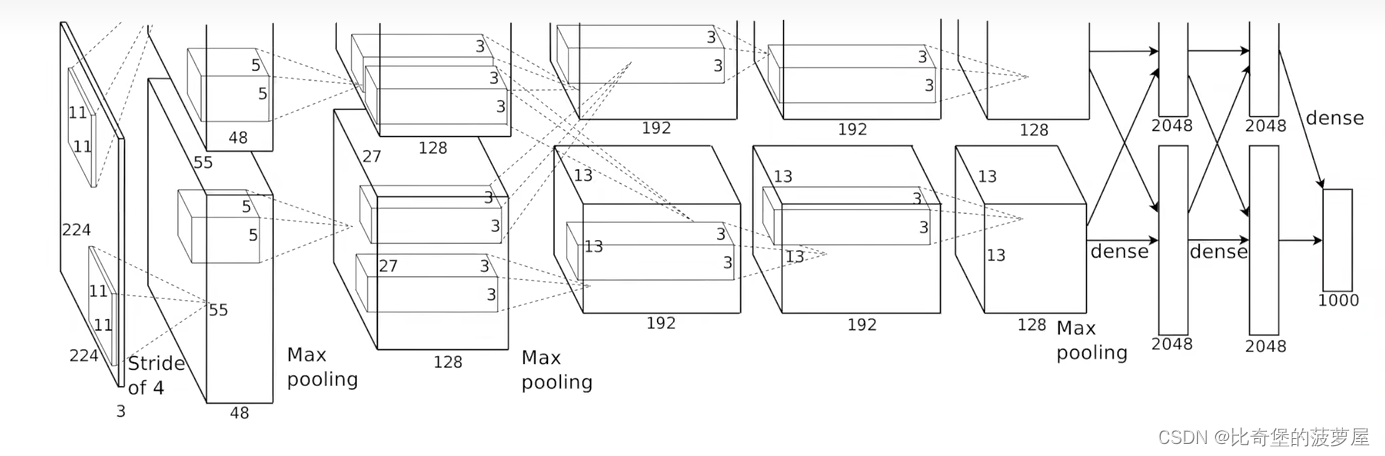
上图的框表述的是数据处理的结果,中间有没有画出来的卷积层,上下分为俩部分是因为在俩个GPU当中计算。
插入:卷积神经网络(CNN)包括卷积层、池化层、全连接层。
卷积层用来识别特定的线条、池化层用来减小图像的数据量,提高效率。全连接层用来最后的识别判断。
把一张224*224*3的图片分为俩部分,一部分由GPU0来卷积,另一部分交给GPU1。
第一层卷积有48个输出通道,第一层卷积后得到的结果再分别计算得到第二层卷积后的结果。
在第三层卷积的时候将俩个GPU的计算结果进行了通信
经过5层卷积,图片的高和宽变得越来越小,深度越来越大。把一个又大又扁平的图片变成了又小又后的图片。
把空间信息压缩到了13*13*128,13*13代表长宽、大小,128代表通道数,每一层通道可以识别不同的模式(比如说车轮、车门)
卷积结束进入全连接层
全连接层的输入是俩个GPU第五个卷积结束后的通信输入,不是单独的输入。
俩个GPU计算全连接层时候又是单独计算然后输出一个2048大小的结果,
然后再拼接成4096的向量。
如果俩个图片的4096向量很接近的话那这俩个图片就很相近甚至是同一个图片。
本流程图通用性太差,多GPU如何切模型没说明
model parallel :模型并行
再过去相当一段长时间内大家都没有干我们提到的模型并行计算(分割图片进行多CPU计算)
但是最近几年,像GPT、BERT的出现使得训练变得很困难,因为数据太大了,训练不动了。
所以大家又开始了模型并行。自然语言处理中用的挺多。
3.如何降低过拟合
过拟合:机器学习模型在训练数据上表现的很好,但是在没有见过的测试数据表现的却很差。
就像学生在模拟考试时候考的很好但是实际考试却很差。
过拟合的特点:对训练数据的噪声和细节过于敏感,导致在位置数据上表现不佳。
过拟合通常发生在图片比较复杂的情况下,好比在做数学题时,使用了太多的公式和计算,反而使得问题变得更加复杂了,模型会过渡拟合训练时候的各种细节和噪声,导致在新数据上泛化能力下降。
解决办法:多训练、降低复杂度、正则化、提前终止训练。(平衡复杂性和简单性)
以上内容来自哔站小七不是柒
回到论文:
3.1Data Augmentation 数据增强
1.把一些图片人工变大,把256*256的图片随机扣一个224*224的图片,但是其实都长得差不多,不太管用。
2.用PCA变一下图片的RGB通道。
3.2Dropout
model ensemble :把很多个模型放起来。不适用于深度学习。
dropout随机把隐藏层的输出用50%的概率变成0,目前看了它属于一个正则项。
作者把dropout放在了俩个全连接之前,要是不放的话过拟合(overfitting)会非常严重。
4 Details of learning 训练细节
SGD(随机梯度下降)stochastic gradient descent:深度学习最常用的算法
是一种优化常用的优化算法,特别适用于处理大规模数据集和高维参数空间的机器学习问题**。它是一种迭代算法,每次迭代都会随机选择一个样本来计算梯度并更新模型参数。这种方法的优势在于其高效性和速度,因为使用小批量或单个样本来计算梯度通常比使用整个数据集要快得多。这使得SGD成为大规模机器学习模型训练中的常用选择。
SGD的特点包括:
1. **mini-batch使用**:SGD通常不是使用单个样本,而是使用称为mini-batch的小样本集合来进行参数更新。
2. **自适应学习率**:SGD可以通过各种策略来自适应地调整学习率,以加快收敛速度并减少震荡。
3. **动量法**:为了解决SGD可能会在梯度较小的点卡住的问题,引入了动量法(Momentum),它在更新时考虑了之前时刻的梯度信息,有助于加快收敛并减少波动。
综上所述,SGD因其简单性和高效性而在机器学习领域中得到了广泛的应用,尤其是在深度学习模型的训练中。它通过随机选择数据子集来更新模型参数,既保留了梯度下降法的优点,又提高了计算效率。


















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









