







视图的特点是指保存逻辑不保存数据,天然就具有节省存储、修改迭代方便的优势。可以应用在以下场景中
1.创建base层
我们在base层中创建表的主要是做了数据集成、数据标准化和数仓内建模。由于base层的建模一般还是3NF建模,而业务系统一般也是标准3NF建模,很多时候base层的表只做了标准化的工作(甚至连标准化都没有)。比如字段名的标准化和通用字段值的标准化。此时base层的表往往形如
-- 字段名的标准化
INSERT OVERWRITE TABLE `${target.table}`
SELECT
id as id --分表中字自增id
,order_id as --订单编号
,type as contact_type --用户类型 0入住人 1联系人
,area_code as area_code --联系电话国际区号
,name as person_name --关系人姓名
,email as email --关系人邮件
,phone as mobile_no --关系人手机号
,identity as identity --身份证号
,room_index_id as room_index_id --房间编号
FROM origindb.hoteltrade01_hotel_order_trade_0_sharding__trade_order_guest_info
;
这种情况下使用视图,既可以完成标准化的工作,还可以很好的节省存储空间,同时也能提升任务执行的速度,是一种比较好的方法。由于整个代码中没有join、group by等shuffle操作,下游在读取时也不用额外增加stage,可谓是“无本多利”
注意:如果base层的逻辑需要做shuffle操作,则需要权衡是建表还是建视图,并不是所有场景都适合建视图
2.数据分发
有些数据团队服务的是平台型的业务/组织,那么在职责上天然就需要向垂直型的业务/组织分发数据,比如公共数据、美团/点评平台、金融平台、客服等。如果加工时存一份数据,分发时再存一份数据,数据就冗余了一倍,此时可以考虑使用视图进行分发。
其实不使用视图也有其他的方案可以既分发又节省存储,比如表中有分发的字段,根据字段的不同值分发给不同的垂直业务,权限控制可以使用河图的行级权限管理。但是和视图相比不够灵活,比如没法多字段组合判断分发,也没法在分发中处理一些业务特有的逻辑。
使用视图分发可以灵活选择分发的字段、灵活处理分发的逻辑、灵活的追加特殊处理,下游大概率不会有很多,即使分发逻辑有shuffle也无所谓。
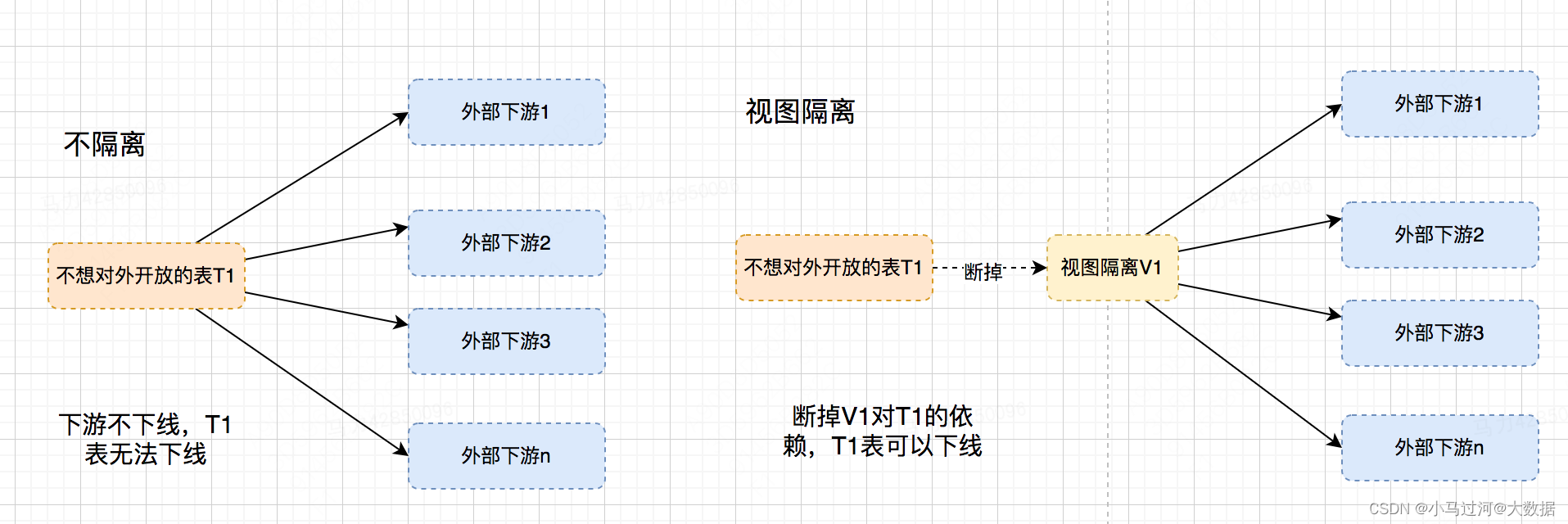
3.隔离授权,避免反向依赖
有时我们不希望一个表直接对外授权,或者不希望一个表的所有字段给外授权都可以使用视图进行隔离。以住宿为例,数仓分层中bas-fact-aggr-topic-app,一般是把aggr、topic、app对外开发,fact和base并不希望对外授权。但是有时业务上就是有场景需要fact的查询、生产权限。对于查询权限还可以通过授权时长来解决,但是生产权限一旦开了,下游任务连上之后想做下线就非常的难,这也是一种反向依赖的场景。
画外音:表A的下游有BCDE等等,由于A表要切换成AA表,导致BCDE要修改自己的代码,BCDE内心会非常的郁闷:明明重构的人是你,为什么配合的人是我?(变动方是A,配合方却是BCDE。或者说需求方是A,改动方却是BCDE),这就是架构设计中的“反向依赖”。
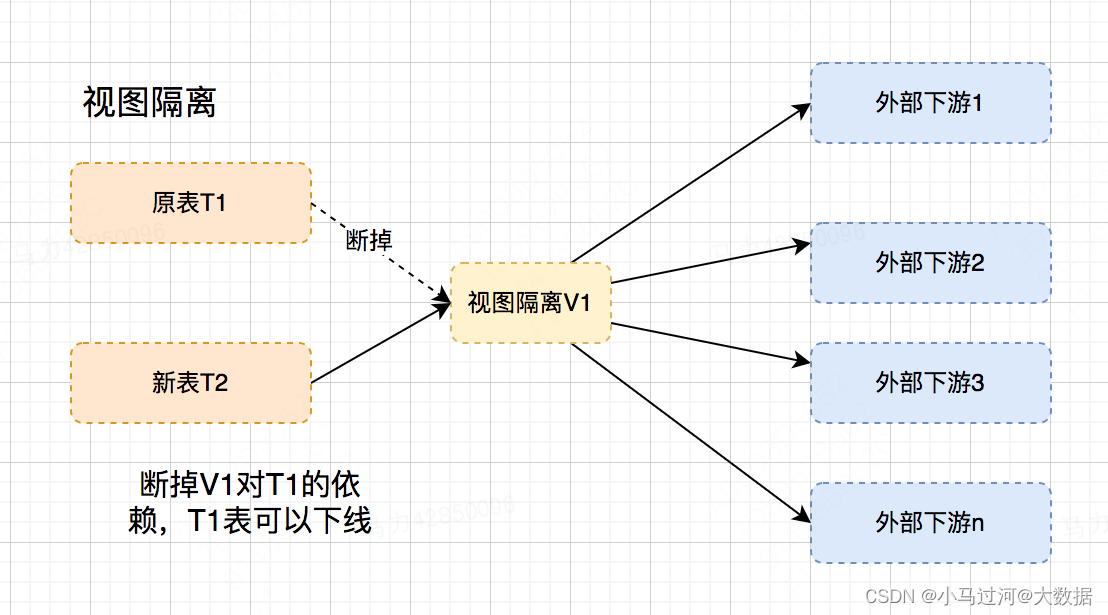
反向依赖的存在对下游很痛,对推下游的人也很痛,所以在架构设计中的一些场景应该尽量避免。使用视图后,可以把整个内外部进行隔离。如下图所示,如果想对T1做下线,当下游多的时候总是会出现下游不响应也不下线,但是使用视图只要直接断掉V1的依赖就好了。如果T1重构成了T2不希望影响外部下游,可以在视图层做兼容(但并不是所有的修改都可以兼容)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









