







0.灵魂拷问
数仓同学每天都在做表,但有没有想过一个问题,计算过程往往是不能节省的,但你是因为什么把某个计算结果落一张表,而某些计算结果不落表呢(只是中间过程),是因为“感觉应该落一张吗?”
1.云计算中的存算分离
存算分离这个概念一开始是出自大数据和云计算,随着云原生的发展被提及的原来越多。早期在大数据和云计算环境中,存储服务和计算服务在集群中是混合部署的(存算耦合架构)。这样设计的原因也很简单,计算存储放一块可以避免很大的网络IO开销。
而然而最近十年的时间,网络性能从当时的百兆网卡增长到了万兆网卡, 网络带宽提升了100倍,网络传输已经不再是分布式环境中的瓶颈(网络IO已经不比磁盘IO慢)。此时矛盾转变为存储和计算并不是同步增长的,不同业务场景下存储和计算的配比也不相同。存算耦合架构会带来资源的浪费,同时为了扩充计算资源不得已要扩充存储资源,也会引起不必要的re-shuffle(想想mpp架构下的doris,增加节点就需要做数据的balance)。因此云计算在发展中提出了存算分离架构,让存储和计算资源都可以弹性可伸缩,集群中资源的利用更加合理(缺啥补啥)。
2.数仓设计的“存算分离”
数仓开发在整个大数据体系中是做数据内容的生产,有一个形象的比喻是从面粉加工成面包的过程,抽象的说是从一个数据集加工成另一个数据集的过程。数仓的生产大家每天都做,但有没有想过一个问题,为什么会把生产结果落一张表?

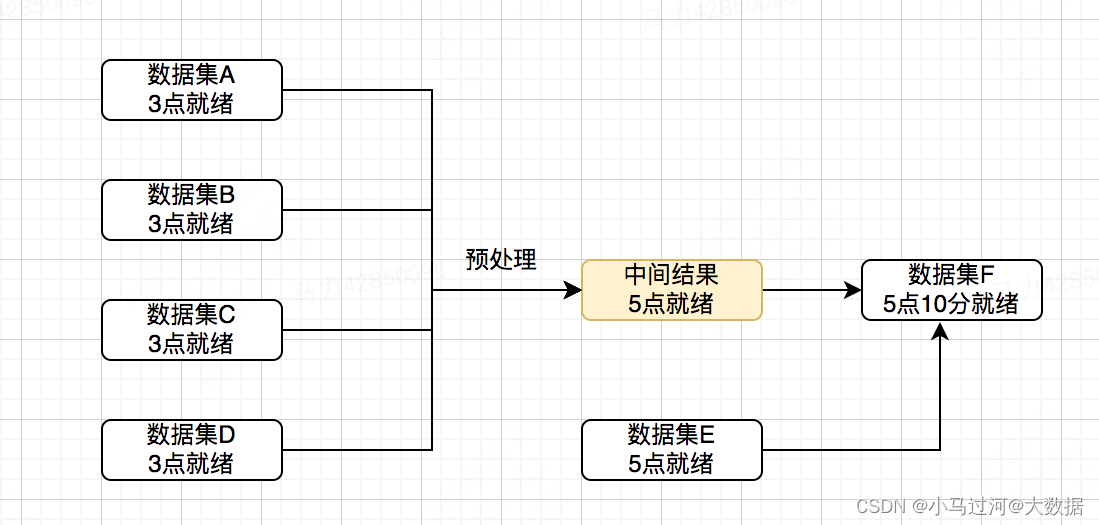
比如上图的生产过程,需要每一个计算之后的结果(数据集)都落成一张表吗?如果不是,哪些数据集应该落表,哪些不需要落表?指导原则是什么?
直接说结论:数仓设计中,每一个计算过程没必要都对应一个存储,计算和存储不应该是绑定的,应该是分离的。
什么情景需要存储数据?大的方向上分为两个
存储落地场景空间换时间一次计算多次使用分段计算缩短最终时间保留现场/关键结果
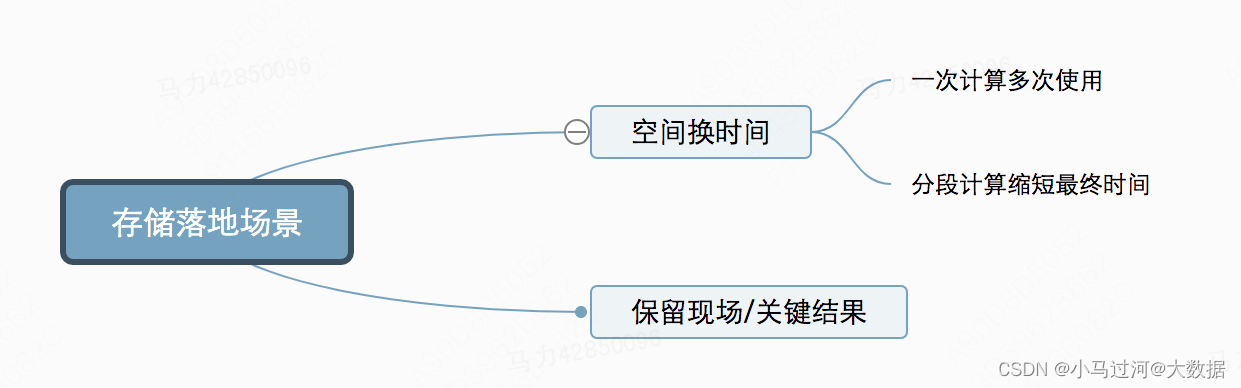
下面每个场景举例来说。
一次计算多次使用
这应该是最常见场景,一次计算的结果会被多次的使用,我们可以先把结果存起来,避免多次使用时的多次重复计算。
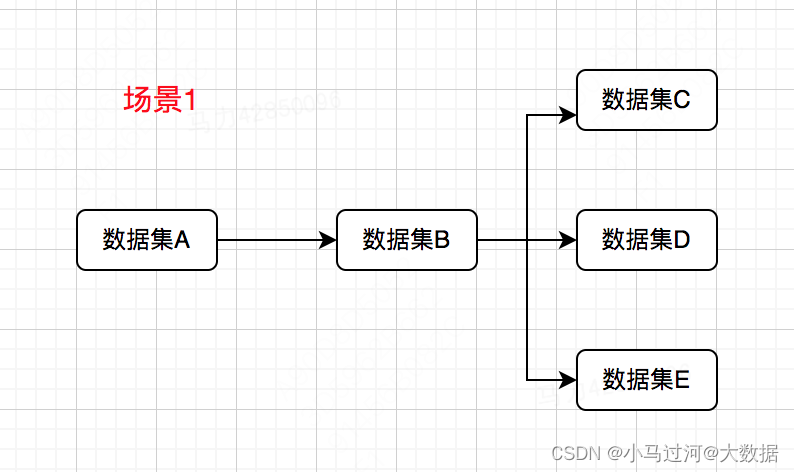
比如上图中,数据集B会被C、D、E使用,那么把B持久化,C、D、E直接基于B的结果计算,会节省A—>B的计算开销
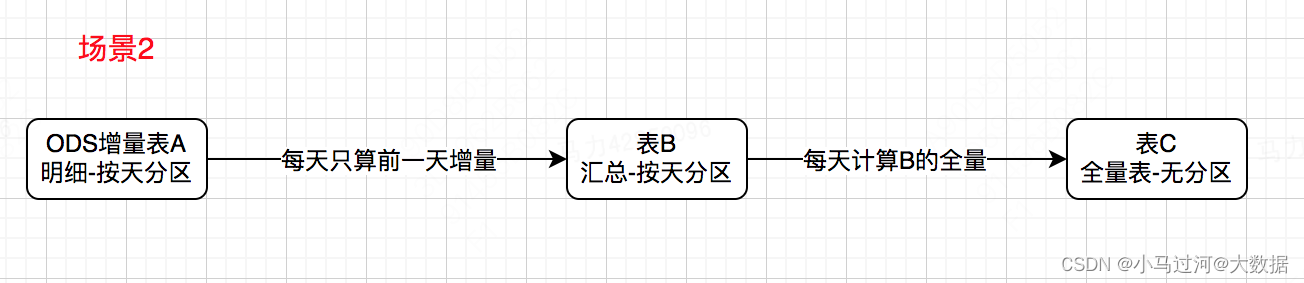
再比如,表B每天从A的最近一次分区计算明细到汇总,但是表C需要对表B的历史全量结果再进行计算。
如果表B不进行持久化,那么表C每天都要做:表A全量到汇总+全量计算到表C
如果表B持久化了,那么表C每天只要做:表A1天明细到汇总+全量计算到表C
也就是说,A—>B的一天数据一次计算持久化后,都会对未来每次B—>C的计算起到帮助
分段计算缩短最终时间
比如在每天生产中,一段任务链条如下
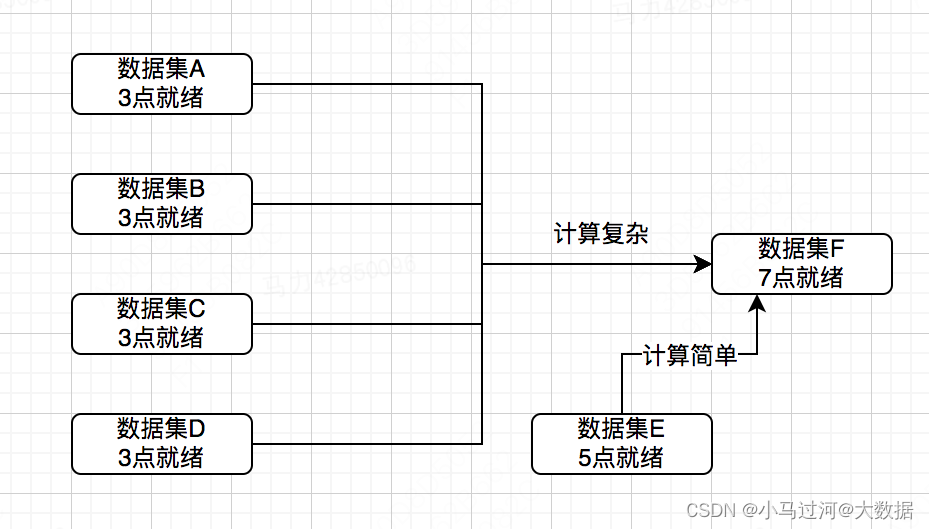
数据集F每天要在数据集E就绪之后,把ABCDE结合起来生成F,且ABCD计算特别复杂,但E—>F逻辑特别简单。有时为了追求就绪时间,可以先把复杂的已经就绪的预处理一个中间结果并持久化,等到E就绪后再把中间结果和E一起生成F
保留现场/关键结果
有别于空间换时间的场景,有些时候即使看起来不那么经济划算,但却必须要持久化落表。
常见的场景有:
-
明细留存:在外部对接的场景中,不仅要对外输出一个结论数据,还要把明细数据存下来与外部核对。比如信用卡对账单,不仅发给你一份待还金额,还会存下来一份生成这个金额的明细数据,用来对账。
-
现场留存:比如使用历史快照表保留事件发生时点的状态,方便历史追溯和核对。
-
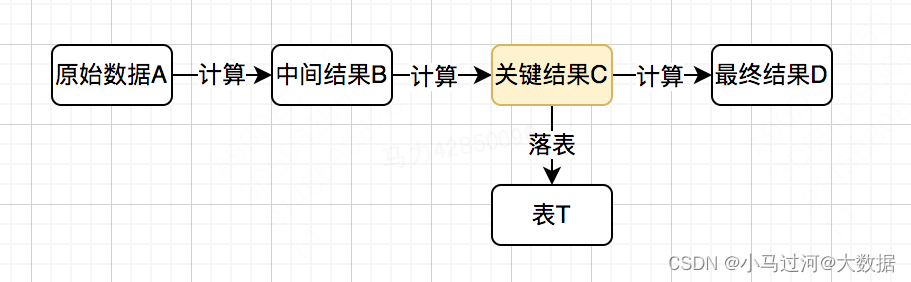
关键结果留存:一连串复杂的计算过程,最终生成的结果D,当D的指标发生波动变化时如果中间的过程完全不存储,则很难排查出是哪个计算过程有问题。如果对关键的结果进行存储,则可以很好的进行问题排查,提升排查效率

















 189
189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









